Wei Liu
@WeiLiu99
#NLProc | Ph.D. Student @hkust @hkustnlp | Prev. @AlibabaGroup @ShanghaiTechUni
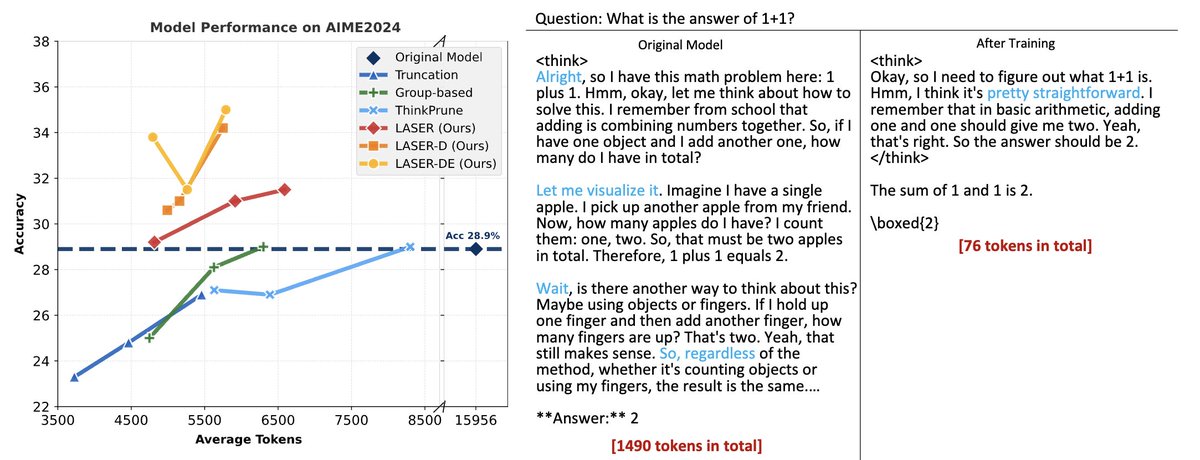
“What is the answer of 1 + 1?” Large Reasoning Models (LRMs) may generate 1500+ tokens just to answer this trivial question. Too much thinking 🤯 Can LRMs be both Faster AND Stronger? Yes. Introducing LASER💥: Learn to Reason Efficiently with Adaptive Length-based Reward Shaping…
MegaMath has been accepted to @COLM_conf 2025🥳 Hoping you find our data useful!
🥁🥁 Happy to share our latest efforts on math pre-training data, the MegaMath dataset! This is a 9-month project starting from 2024’s summer, and we finally deliver: the largest math pre-training data to date containing 💥370B 💥tokens of web, code, and synthetic data!
🚀 Just one week after SWE-Perf launched (the first repository-level benchmark for realistic code performance optimization), Qwen3-Coder drops and IMMEDIATELY takes the crown! 👑 Released just 3 days ago, Qwen3-Coder with OpenHands is now the top performer on SWE-Perf's…
🔥 LLMs can fix bugs, but can they make your code faster? We put them to the test on real-world repositories, and the results are in! 🚀 New paper: "SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?" Key findings: 1️⃣ We introduce SWE-Perf, the…
Wrapped up a SWE-Perf website redesign using Qwen3-Coder on AnyCoder (huggingface.co/spaces/akhaliq…). The process was incredibly fast and great! One question for Qwen devs, though: did you pretrain a secret love for the color purple into the coder's persona? 😉
🔥 LLMs can fix bugs, but can they make your code faster? We put them to the test on real-world repositories, and the results are in! 🚀 New paper: "SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?" Key findings: 1️⃣ We introduce SWE-Perf, the…
🚀 Thrilled to announce Dream-Coder 7B — the most powerful open diffusion code LLM to date.
What happend after Dream 7B? First, Dream-Coder 7B: A fully open diffusion LLM for code delivering strong performance, trained exclusively on public data. Plus, DreamOn cracks the variable-length generation problem! It enables code infilling that goes beyond a fixed canvas.
Can we build an operating system entirely powered by neural networks? Introducing NeuralOS: towards a generative OS that directly predicts screen images from user inputs. Try it live: neural-os.com Paper: huggingface.co/papers/2507.08… Inspired by @karpathy's vision. 1/5
"Chatting" with LLM feels like using an 80s computer terminal. The GUI hasn't been invented, yet but imo some properties of it can start to be predicted. 1 it will be visual (like GUIs of the past) because vision (pictures, charts, animations, not so much reading) is the 10-lane…
👇this nice guy❤️will help us present CodeI/O (arxiv.org/abs/2502.07316) at Oral session 6A Applications in Agents and Coding, Thu 17 Jul 4 p.m. — 4:15 p.m. PDT. Take a look if you are there and feel interested.
Attending #ICML2025 🇨🇦 this week! Will be presenting Aguvis (arxiv.org/abs/2412.04454) on July 15 at 11am, and joining Computer Use Agent Workshop @workshopcua on July 19. If you’re into digital agent research, especially around computer/browser use, let’s grab a coffee!
Attending #ICML2025 🇨🇦 this week! Will be presenting Aguvis (arxiv.org/abs/2412.04454) on July 15 at 11am, and joining Computer Use Agent Workshop @workshopcua on July 19. If you’re into digital agent research, especially around computer/browser use, let’s grab a coffee!
Reinforcement Learning with Action Chunking Q-Chunking improves offline-to-online RL by operating in a temporally extended action space: - Action chunking: Policies output short sequences of actions, improving exploration and handling non-Markovian dynamics - Chunked TD…
📢New conference where AI is the primary author and reviewer! agents4science.stanford.edu Current venues don't allow AI-written papers, so it's hard to assess the +/- of such works🤔 #Agents4Science solicits papers where AI is the main author w/ human advisors. 💡Initial reviews by…
🚀 Check out our recent work Afterburner: Reinforcement Learning demonstrating super powerful self-improving code efficiency optimization! 💻✨
🚀 Thrilled to announce our new paper: Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency Optimization Stop settling for LLM-generated code that just works. Demand code that performs! Our new RL framework boosts Pass@1 +15% and significantly…
1/n Multi-token prediction boosts LLMs (DeepSeek-V3), tackling key limitations of the next-token setup: • Short-term focus • Struggles with long-range decisions • Weaker supervision Prior methods add complexity (extra layers) 🔑 Our fix? Register tokens—elegant and powerful
🤖Can diffusion models write code competitively? Excited to share our latest 7B coding diffusion LLM!!💻 With DiffuCoder, we explore how they decode, why temperature🔥 matters, and how to improve them via coupled-GRPO that speaks diffusion!!📈 Code: github.com/apple/ml-diffu… 🧵
Multi-turn RL is crucial for enabling richer real-world interactions, but training can be unstable. SimpleTIR offers a simple and effective solution to stabilize multi-turn RL training.
🛠️🤖 Introducing SimpleTIR: An end-to-end solution for stable multi-turn tool use RL 📈 Multi-turn RL training suffers from catastrophic instability, but we find a simple fix ✨ The secret? Strategic trajectory filtering keeps training rock-solid! 🎯 Stable gains straight from…
Excited to introduce our 7B Coding Diffusion LLM, DiffuCoder — advancing open-source diffusion models for high-quality code generation! Diffusion offers powerful global planning via iterative generation, and code is the perfect testbed to push its limits! #DiffusionModels
🤖Can diffusion models write code competitively? Excited to share our latest 7B coding diffusion LLM!!💻 With DiffuCoder, we explore how they decode, why temperature🔥 matters, and how to improve them via coupled-GRPO that speaks diffusion!!📈 Code: github.com/apple/ml-diffu… 🧵
💥💥BANG! Experience the future of gaming with our real-time world model for video games!🕹️🕹️ Not just PLAY—but CREATE! Introducing Mirage, the world’s first AI-native UGC game engine. Now featuring real-time playable demos of two games: 🏙️ GTA-style urban chaos 🏎️ Forza…
Excited to share our new survey on the reasoning paradigm shift from "Think with Text" to "Think with Image"! 🧠🖼️ Our work offers a roadmap for more powerful & aligned AI. 🚀 📜 Paper: arxiv.org/pdf/2506.23918 ⭐ GitHub (400+🌟): github.com/zhaochen0110/A…
No matter how AI evolves overnight—tech, career, how it may impact me—I remain committed to using "physics of language models" approach to predict next-gen AI. Due to my limited GPU access at Meta, Part 4.1 (+new 4.2) are still in progress, but results on Canon layers are shining
(1/8)🍎A Galileo moment for LLM design🍎 As Pisa Tower experiment sparked modern physics, our controlled synthetic pretraining playground reveals LLM architectures' true limits. A turning point that might divide LLM research into "before" and "after." physics.allen-zhu.com/part-4-archite…
😵💫 Struggling with 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐌𝐨𝐄? Meet 𝐃𝐞𝐧𝐬𝐞𝐌𝐢𝐱𝐞𝐫 — an MoE post-training method that offers more 𝐩𝐫𝐞𝐜𝐢𝐬𝐞 𝐫𝐨𝐮𝐭𝐞𝐫 𝐠𝐫𝐚𝐝𝐢𝐞𝐧𝐭, making MoE 𝐞𝐚𝐬𝐢𝐞𝐫 𝐭𝐨 𝐭𝐫𝐚𝐢𝐧 and 𝐛𝐞𝐭𝐭𝐞𝐫 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐢𝐧𝐠! Blog: fengyao.notion.site/moe-posttraini……