
Qian Liu
@sivil_taram
Researcher @ TikTok 🇸🇬 📄 Sailor / StarCoder / OpenCoder 💼 Past: Research Scientist @SeaAIL; PhD @MSFTResearch 🧠 Contribution: @XlangNLP @BigCodeProject
🔥 LLMs can fix bugs, but can they make your code faster? We put them to the test on real-world repositories, and the results are in! 🚀 New paper: "SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?" Key findings: 1️⃣ We introduce SWE-Perf, the…
😝 Thanks to @sivil_taram for the evaluation. It's great to see Qwen3-Coder performing excellently on SWE-Perf! The community also needs more outstanding evaluations like SWE-Perf to continue guiding the development of CodeLLM!
🚀 Just one week after SWE-Perf launched (the first repository-level benchmark for realistic code performance optimization), Qwen3-Coder drops and IMMEDIATELY takes the crown! 👑 Released just 3 days ago, Qwen3-Coder with OpenHands is now the top performer on SWE-Perf's…
🚀 Just one week after SWE-Perf launched (the first repository-level benchmark for realistic code performance optimization), Qwen3-Coder drops and IMMEDIATELY takes the crown! 👑 Released just 3 days ago, Qwen3-Coder with OpenHands is now the top performer on SWE-Perf's…
🔥 LLMs can fix bugs, but can they make your code faster? We put them to the test on real-world repositories, and the results are in! 🚀 New paper: "SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?" Key findings: 1️⃣ We introduce SWE-Perf, the…
Definitely worth a read, MoE plus RL
Proud to introduce Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant RL algorithm that powers the large-scale RL training of the latest Qwen3 models (Instruct, Coder, Thinking) 🚀 📄 huggingface.co/papers/2507.18…
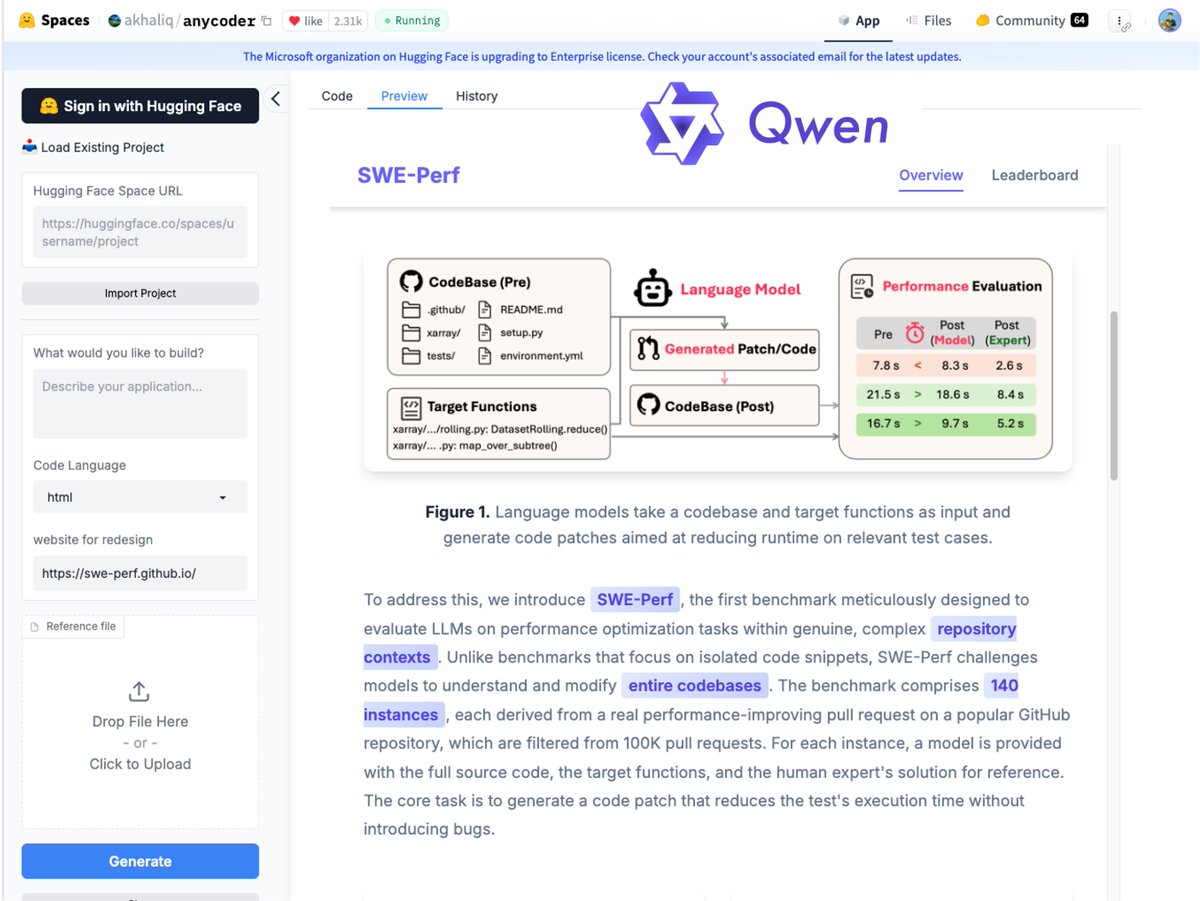
Wrapped up a SWE-Perf website redesign using Qwen3-Coder on AnyCoder (huggingface.co/spaces/akhaliq…). The process was incredibly fast and great! One question for Qwen devs, though: did you pretrain a secret love for the color purple into the coder's persona? 😉
🚀🚀🚀 Ever wondered what it takes for robots to handle real-world household tasks? long-horizon execution, deformable object dexterity, and unseen object generalization — meet GR-3, ByteDance Seed’s new Vision-Language-Action (VLA) model! GR-3 is a generalizable…
The most rewarding moment in research: hearing someone say "This actually works in our scenario!" ✨
Apart from the performance, it’s pure entertainment just watching Qwen3‑Coder build Qwen Code all by itself. Agentic coding is really something: it explores, understands, plans, and acts seamlessly. Honored to be “in the game”—even if my entire work so far is smashing the Enter…
>>> Qwen3-Coder is here! ✅ We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves…
>>> Qwen3-Coder is here! ✅ We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves…
After three intense months of hard work with the team, we made it! We hope this release can help drive the progress of Coding Agents. Looking forward to seeing Qwen3-Coder continue creating new possibilities across the digital world!
>>> Qwen3-Coder is here! ✅ We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves…
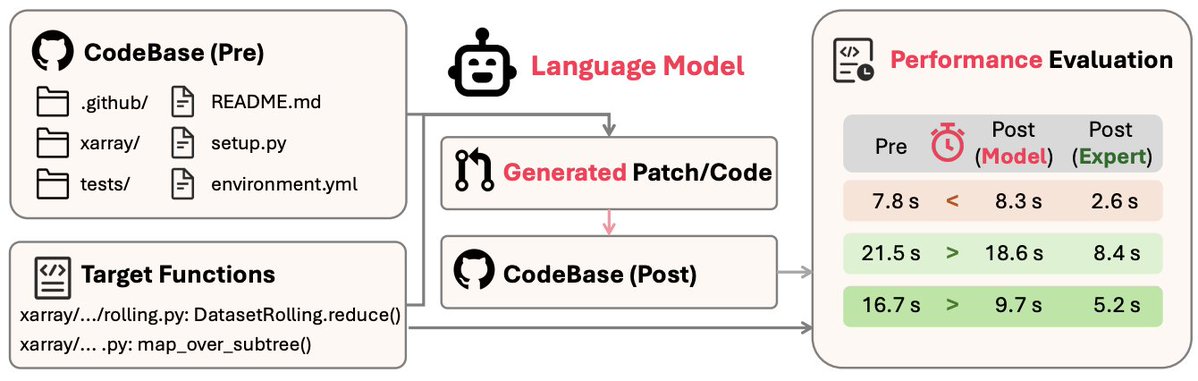
TikTok Researchers Introduce SWE-Perf: The First Benchmark for Repository-Level Code Performance Optimization SWE-Perf, introduced by TikTok researchers, is the first benchmark designed to evaluate large language models (LLMs) on repository-level code performance optimization.…
Nice new research work by @tiktok_us on benchmarking performance optimization by LLM agents: arxiv.org/abs/2507.12415 OpenHands w/ Sonnet 3.7 achieves the best results, optimizing 44 functions in popular open-source code bases (compared to human experts' 184).
Excited to share that our two papers have been accepted to #ICML2025! @icmlconf However, I can't be there in person due to visa issues. What a pity.🥲 Feel free to check out our poster, neither online nor offline in the Vancouver Convention Center. Programming Every Example:…
Excited to share that our two papers have been accepted to #ICML2025! @icmlconf However, I can't be there in person due to visa issues. What a pity.🥲 Feel free to check out our poster, neither online nor offline in the Vancouver Convention Center. Programming Every Example:…
SWE-Perf Can Language Models Optimize Code Performance on Real-World Repositories?