
Sansa Gong
@sansa19739319
Diffusion in NLP; PhD@HKU; Prev. @ SJTU
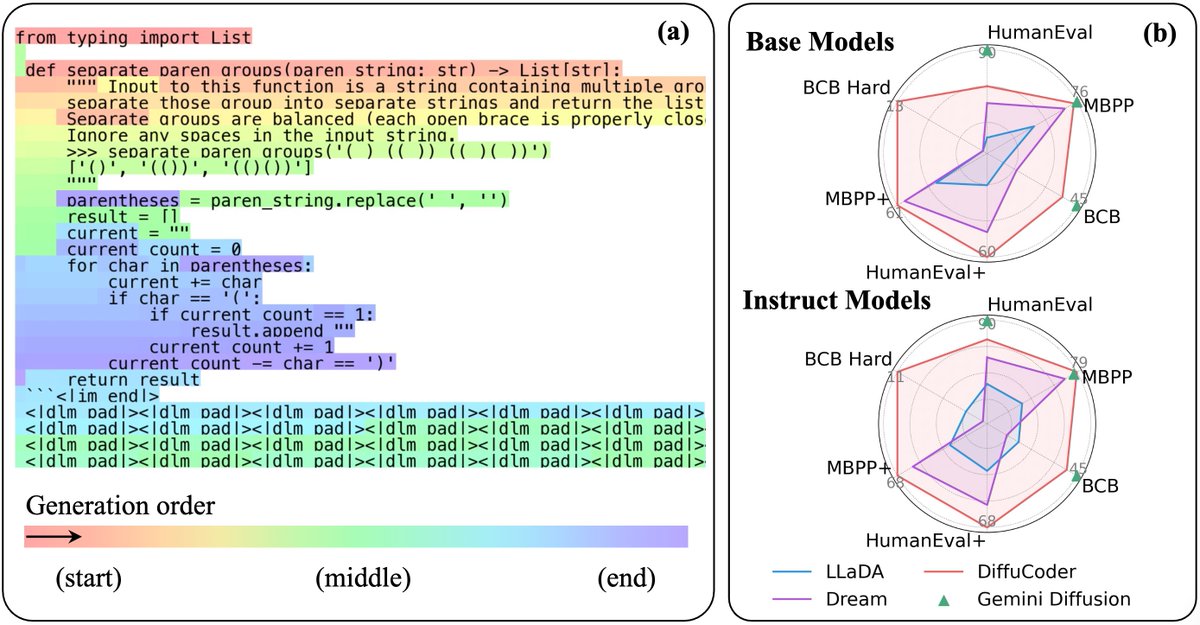
🤖Can diffusion models write code competitively? Excited to share our latest 7B coding diffusion LLM!!💻 With DiffuCoder, we explore how they decode, why temperature🔥 matters, and how to improve them via coupled-GRPO that speaks diffusion!!📈 Code: github.com/apple/ml-diffu… 🧵
Xinyu Yang from CMU will be giving a talk titled "Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation" at Friday July 25 11am HKT (Thursday July 24 8pm PDT). Link to talk: hku.zoom.us/j/92651812689?…
Thanks to @omarsar0 for sharing our work!
Reinforcement Pre-Training New pre-training paradigm for LLMs just landed on arXiv! It incentivises effective next-token reasoning with RL. This unlocks richer reasoning capabilities using only raw text and intrinsic RL signals. A must-read! Bookmark it! Here are my notes:
📢 Update: Announcing Dream's next-phase development. - Dream-Coder 7B: A fully open diffusion LLM for code delivering strong performance, trained exclusively on public data. - DreamOn: targeting the variable-length generation problem in dLLM!
Supporting variable length generation is definitely a big step for diffusion language model. Checkout Dreamon - great work from Zirui😎!!
We present DreamOn: a simple yet effective method for variable-length generation in diffusion language models. Our approach boosts code infilling performance significantly and even catches up with oracle results.
DreamCoder - 7B diffusion model for even better coding performance!!🤗
🚀 Thrilled to announce Dream-Coder 7B — the most powerful open diffusion code LLM to date.
Can data owners & LM developers collaborate to build a strong shared model while each retaining data control? Introducing FlexOlmo💪, a mixture-of-experts LM enabling: • Flexible training on your local data without sharing it • Flexible inference to opt in/out your data…
Introducing FlexOlmo, a new paradigm for language model training that enables the co-development of AI through data collaboration. 🧵
Apple just dropped DiffuCoder on Hugging Face Understanding and Improving Masked Diffusion Models for Code Generation
Thanks for sharing our work!!!🙏Code release is in progress😺
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation Apple introduces DiffuCoder, a 7B diffusion LLM trained on 130B tokens of code authors also propose a diffusion-native RL training framework, coupled-GRPO Decoding of dLLMs differ from…
# 🚨 4B open-recipe model beats Claude-4-Opus 🔓 100% open data, recipe, model weights and code. Introducing Polaris✨--a post-training recipe for scaling RL on advanced reasoning models. 🥳 Check out how we boost open-recipe reasoning models to incredible performance levels…
We’ve developed Gemini Diffusion: our state-of-the-art text diffusion model. Instead of predicting text directly, it learns to generate outputs by refining noise, step-by-step. This helps it excel at coding and math, where it can iterate over solutions quickly. #GoogleIO
We are kicking off a series of seminars at @hkunlp2020. @siyan_zhao will be giving a talk titled "d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning" at ⏰Friday 5.9 11am HKT (Thursday 5.8 8pm PDT). Link to talk: hku.zoom.us/j/97925412724?…
🚀 Meet PromptCoT-QwQ-32B, a breakthrough in mathematical reasoning! Outperforming all open-source models on AIME2024 and AIME2025, including Nemotron-Ultra-253B, DeepSeek-R1-671B, and QwQ-32B! 🔥
Introducing d1🚀 — the first framework that applies reinforcement learning to improve reasoning in masked diffusion LLMs (dLLMs). Combining masked SFT with a novel form of policy gradient algorithm, d1 significantly boosts the performance of pretrained dLLMs like LLaDA.