
Feng Yao
@fengyao1909
Ph.D. student @UCSD_CSE | Intern @Amazon Rufus Foundation Model Ex. @MSFTResearch @TsinghuaNLP
😵💫 Struggling with 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐌𝐨𝐄? Meet 𝐃𝐞𝐧𝐬𝐞𝐌𝐢𝐱𝐞𝐫 — an MoE post-training method that offers more 𝐩𝐫𝐞𝐜𝐢𝐬𝐞 𝐫𝐨𝐮𝐭𝐞𝐫 𝐠𝐫𝐚𝐝𝐢𝐞𝐧𝐭, making MoE 𝐞𝐚𝐬𝐢𝐞𝐫 𝐭𝐨 𝐭𝐫𝐚𝐢𝐧 and 𝐛𝐞𝐭𝐭𝐞𝐫 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐢𝐧𝐠! Blog: fengyao.notion.site/moe-posttraini……
[Implicit Personalization of #LLMs] How do we answer the question "What colo(u)r is a football?" Answer 1: "Brown🏈 ". Answer 2: "Black and white⚽". We propose a #Causal framework to test if LLMs adjust its answers depending on the cultural background inferred from the question.…
Feel free to join if you’re interested! This will be my first public talk on DenseMixer — I was previously invited by the Qwen Team to give a private talk, and now excited to share it more broadly at Cohere.
Be sure to join our Regional Asia group next week on July 23rd as they sit down with @fengyao1909 for an insightful session on "DenseMixer: Improving MoE Post-Training with Precise Router Gradient" Thanks to @KanwalMehreen2 and @AhmadMustafaAn1 for organizing this session! 👏
What happend after Dream 7B? First, Dream-Coder 7B: A fully open diffusion LLM for code delivering strong performance, trained exclusively on public data. Plus, DreamOn cracks the variable-length generation problem! It enables code infilling that goes beyond a fixed canvas.
🚀 Attention is the bottleneck in video DiTs—5 s of 720p = 100K+ tokens, quadratic cost blows up fast. Sparse/linear attention is 🔑 for long-context world models. 🧠 Track relavent papers in our awsome-video-attention repo → github.com/hao-ai-lab/Aws… #WorldModel #VideoAI
My brilliant friend just got an ICML 2025 oral for this wild and elegant theory connecting double descent, grokking, and prime numbers 🤯 He’s on the job market — if you’re hiring, don’t miss out. Feel free to reach out!
Our new ICML 2025 oral paper proposes a new unified theory of both Double Descent and Grokking, revealing that both of these deep learning phenomena can be understood as being caused by prime numbers in the network parameters 🤯🤯 🧵[1/8]
Glad to see DensenMixer has been integrated into Axolotl, an fully open source framework for post-training various LLMs! Welcome to try!
Axolotl v0.11.0 is out! We've included ALST's TiledMLP for increased long sequence length training as well as support for Devstral, DenseMixer (MoE performance), and support for the most recent releases of transformers 4.53.1, accelerate 1.8.1, and FlashAttention2.
🚀 New release for the Phi family! **SlimMOE** (arxiv.org/abs/2506.18349) trims bulky Φ-3.5-MoE experts into agile models (4-6× smaller) with MINIMAL accuracy loss. If you ❤️ Phi-3 mini/small, you’ll love these lighter siblings.👇
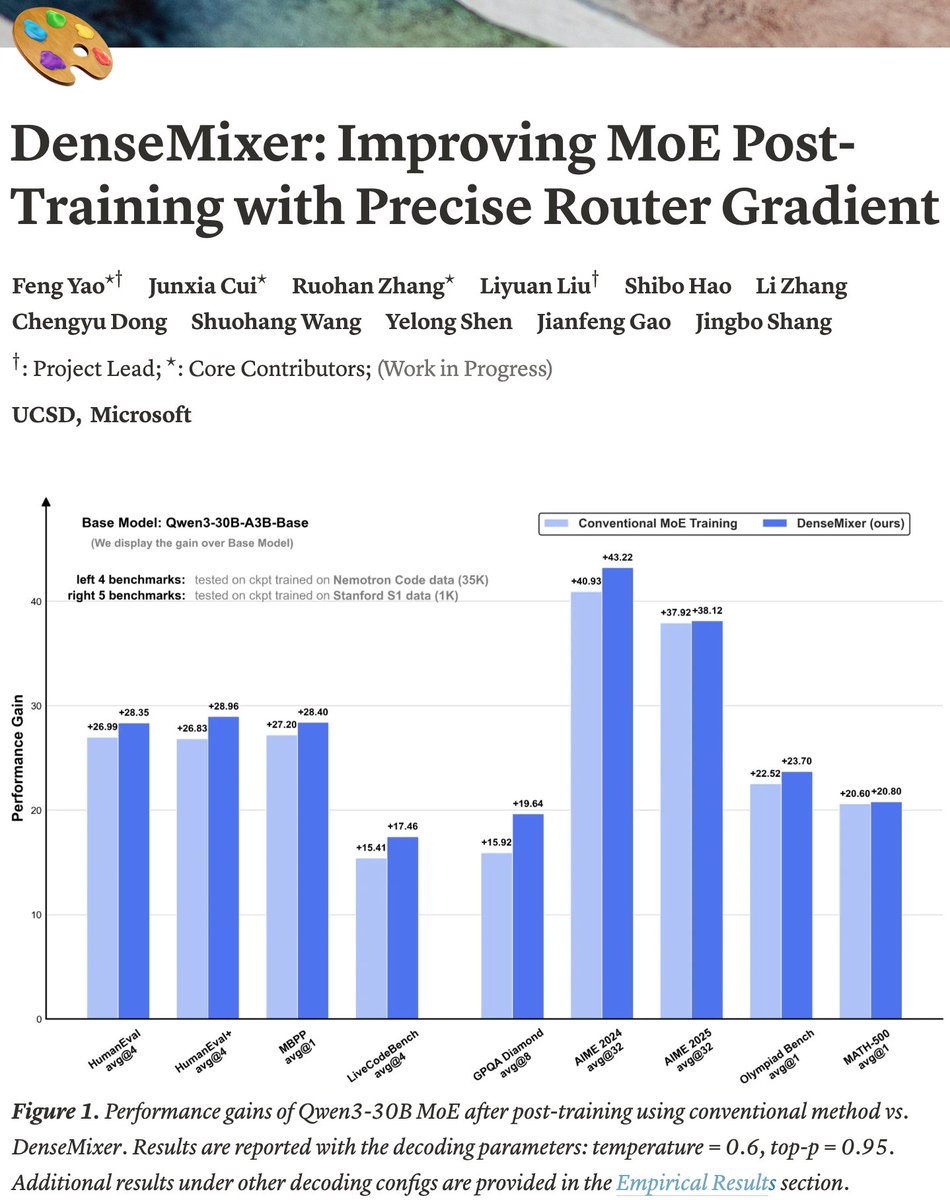
Training mixture‑of‑experts models hits a wall at the router. This new technique DenseMixer, fixes that, by trading one extra forward pass on inactive experts for precise router gradient DenseMixer sends each training token through every expert once, then treats the router’s…
😵💫 Struggling with 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐌𝐨𝐄? Meet 𝐃𝐞𝐧𝐬𝐞𝐌𝐢𝐱𝐞𝐫 — an MoE post-training method that offers more 𝐩𝐫𝐞𝐜𝐢𝐬𝐞 𝐫𝐨𝐮𝐭𝐞𝐫 𝐠𝐫𝐚𝐝𝐢𝐞𝐧𝐭, making MoE 𝐞𝐚𝐬𝐢𝐞𝐫 𝐭𝐨 𝐭𝐫𝐚𝐢𝐧 and 𝐛𝐞𝐭𝐭𝐞𝐫 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐢𝐧𝐠! Blog: fengyao.notion.site/moe-posttraini……
Take a look at Mirage👇our new work on real-time neural game engine!
😵💫 Struggling with 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐌𝐨𝐄? Meet 𝐃𝐞𝐧𝐬𝐞𝐌𝐢𝐱𝐞𝐫 — an MoE post-training method that offers more 𝐩𝐫𝐞𝐜𝐢𝐬𝐞 𝐫𝐨𝐮𝐭𝐞𝐫 𝐠𝐫𝐚𝐝𝐢𝐞𝐧𝐭, making MoE 𝐞𝐚𝐬𝐢𝐞𝐫 𝐭𝐨 𝐭𝐫𝐚𝐢𝐧 and 𝐛𝐞𝐭𝐭𝐞𝐫 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐢𝐧𝐠! Blog: fengyao.notion.site/moe-posttraini……
A differentiable, semi-full-param training for MoEs. More FLOPs, comparable speed, higher and more predictable perf gain. I think it's a big deal. Academic research is stuck with finetuning dense models due to MoE complexity overhead. This is NGMI in the inference-dominant era.
😵💫 Struggling with 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐌𝐨𝐄? Meet 𝐃𝐞𝐧𝐬𝐞𝐌𝐢𝐱𝐞𝐫 — an MoE post-training method that offers more 𝐩𝐫𝐞𝐜𝐢𝐬𝐞 𝐫𝐨𝐮𝐭𝐞𝐫 𝐠𝐫𝐚𝐝𝐢𝐞𝐧𝐭, making MoE 𝐞𝐚𝐬𝐢𝐞𝐫 𝐭𝐨 𝐭𝐫𝐚𝐢𝐧 and 𝐛𝐞𝐭𝐭𝐞𝐫 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐢𝐧𝐠! Blog: fengyao.notion.site/moe-posttraini……
🐙Octothinker tech report is finally out! We also release the 70B math-focusing mid-training dataset -- MegaMath-Web-Pro-Max. Hope you'll find it useful!🤗 👇 hf.co/datasets/OctoT… huggingface.co/papers/2506.20…
Say hi to 🐙 OctoThinker — our new mid-training efforts for building strong reasoning base models tailored for the RL scaling era. Still a WIP, but we're excited to share our early insights into rethinking base model development. 📖 Blog: tinyurl.com/OctoThinker 🤗 Huggingface:…