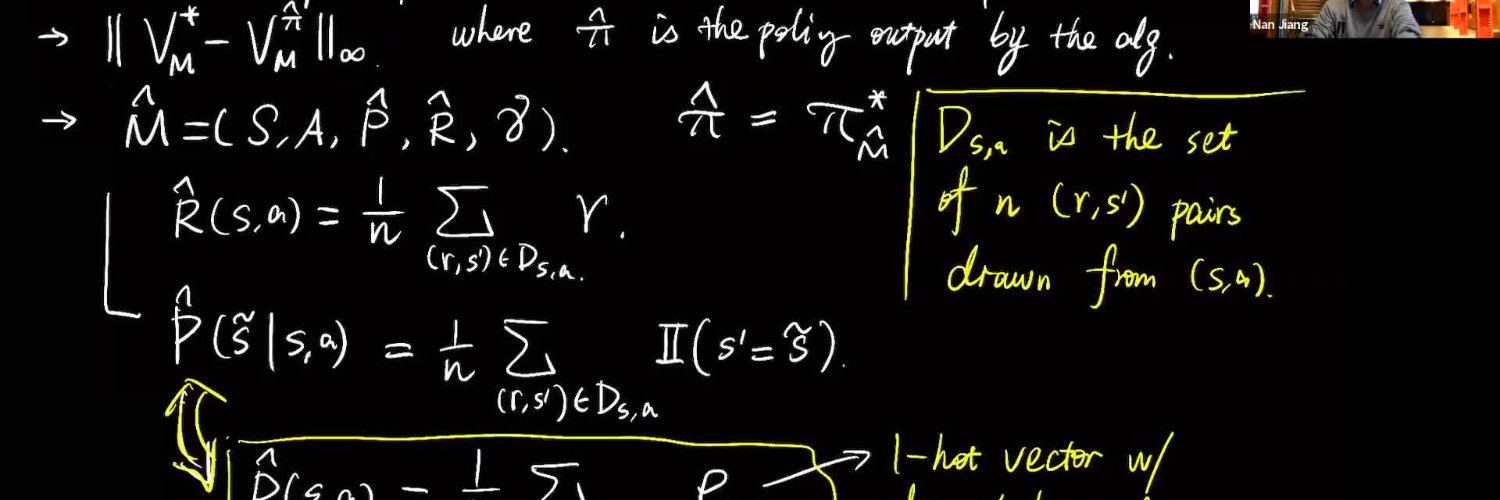
Nan Jiang
@nanjiang_cs
machine learning researcher, with focus on reinforcement learning. assoc prof @ uiuc cs. Course on RL theory (w/ videos): https://nanjiang.cs.illinois.edu/cs542
Learning Q* with + poly-sized exploratory data + an arbitrary Q-class that contains Q* ...has seemed impossible for yrs, or so I believed when I talked at @RLtheory 2mo ago. And what's the saying? Impossible is NOTHING arxiv.org/abs/2008.04990 Exciting new work w/@tengyangx! 1/


Thank goodness at least someone remembers nytimes.com/2025/05/30/opi…
It’s almost hilarious that he chose to mention US space program. Who tells him what happened when a founding figure of JPL was expelled for the exact same reasons they use today?
Really excited that I will be co-chairing ALT 2026 with Matus Telgarsky! The conference will be Feb 23-26, 2026 at the Fields Institute in Toronto. Website with cfp is now live---stay tuned for updates Please submit your best work and come join us!
missing ICML, and I used this week to write my first technical blog on some recent thoughts on two different roles of simulators in RL and the confusions/misconceptions around them. Comments welcome! nanjiang.cs.illinois.edu/2025/07/16/sim…

Provably Learning from Language Feedback TLDR: RL theory can help us do better inference-time exploration with feedback. Work done with @wanqiao_xu, @ruijie_zheng12, @chinganc_rl, @adityamodi94, @adith387 📰 arxiv.org/pdf/2506.10341 📍EXAIT Best Paper/Oral Sat 8:45-9:30 am
For those at ICML, Audrey will be presenting this paper at the 4:30 poster session this afternoon! West Exhibition Hall B2-B3 W-1009
Is Best-of-N really the best we can do for language model inference? New algo & paper: 🚨InferenceTimePessimism🚨 Led by the amazing Audrey Huang (@auddery) with Adam Block, Qinghua Liu, Nan Jiang (@nanjiang_cs), and Akshay Krishnamurthy. Appearing at ICML '25. 1/11
I thought what disappeared was test (replaced by benchmark evals), not val. If you use the “test” split from train data (1) more than once and (2) without reporting it, then that’s just val?
when i first learned Machine Learning, our professor ingrained into us how every ML problem starts by splitting data into train, test, and validation these days there is just train and test. in many cases there is just train and more train where’d all the validation sets go?
this sounds more like unreal/unity…?
Modern licenses so funny. Amazing looking model. MIT-Modified. Marketing is king. "Our only modification part is that, if the Software (or any derivative worksthereof) is used for any of your commercial products or services that havemore than 100 million monthly active users, or…
Re prompt injection in papers: what if reviewers do their job seriously using LLM as a useful tool (given conf permission)? Aren’t we supposed to be “not afraid of LLMs” as in eg education? somehow we become extremely conservative when it comes to ourselves…?
First position paper I ever wrote. "Beyond Statistical Learning: Exact Learning Is Essential for General Intelligence" arxiv.org/abs/2506.23908 Background: I'd like LLMs to help me do math, but statistical learning seems inadequate to make this happen. What do you all think?
HUGE congrats to @wanqiao_xu -- this paper just got the best theory paper award at ICML 2025 EXAIT (Exploration in AI) -- proposing a new provably efficient exploration algorithm 🛣️ with the right level of abstraction to leverage the strengths of LLMs 💭.
Decision-making with LLM can be studied with RL! Can an agent solve a task with text feedback (OS terminal, compiler, a person) efficiently? How can we understand the difficulty? We propose a new notion of learning complexity to study learning with language feedback only. 🧵👇
E66: Satinder Singh: The Origin Story of RLDM @ RLDM 2025 Professor Satinder Singh of @GoogleDeepMind and @UMich is co-founder of @RLDMDublin2025. Here he narrates the origin story of the Reinforcement Learning and Decision Making meeting (not conference).
A new opening for multimodal model research: jobs.careers.microsoft.com/global/en/job/… . Please apply if interested.
We now know RL agents can zero-shot crush driving benchmarks. Can we put them on a car and replace the planning stack? We're hiring a postdoc at NYU to find out! Email me if interested and please help us get the word out.
Decision-making with LLM can be studied with RL! Can an agent solve a task with text feedback (OS terminal, compiler, a person) efficiently? How can we understand the difficulty? We propose a new notion of learning complexity to study learning with language feedback only. 🧵👇
Re error propagation: if you believe model-based is a solution but also want the benefits of model-free, perhaps time to investigate (never thoroughly-studied) bellman-error minimization... BRM is, in a way, closer to model-based than TD (small revelation from my l4dc talk)
Q-learning is not yet scalable seohong.me/blog/q-learnin… I wrote a blog post about my thoughts on scalable RL algorithms. To be clear, I'm still highly optimistic about off-policy RL and Q-learning! I just think we haven't found the right solution yet (the post discusses why).
I've received multiple emails from nxtai-conference.com. Having "AI+quantum" as keywords looks very much like a scam at first glance (sorry!) but the speaker list seems very legit. What's going on with this...? Also can't find organizer info. Are there academics behind this?
In the interim, I wanted to advertise our YouTube channel - youtube.com/@montecarlosem… - which contains recordings for the bulk of our talks so far (sites.google.com/view/monte-car…, sites.google.com/view/monte-car…). I encourage you to catch up and enjoy them over the intervening months!
En route to (my first) l4dc and will be giving a keynote on Friday. Happy to chat tmr & Friday if you are around!
Join the Opening Reception at the Ford Robotics Building (FRB) on North Campus: - Opening Reception starts at 6pm - Lab tours and demos from 5:30pm-8:30pm Ask a volunteer to take blue bus (CN) on Division at Jefferson or rideshare to head north! maps.app.goo.gl/LnJPR3fTNLTTAB…
Given the sheer number of ppl interested in PG methods nowadays I'm sure innocent "rediscoveries" like this are happening everyday. Otoh, due diligence takes minimal effort today as you can just DeepResearch. All it takes is the sense/taste to ask "no way this is not done b4"...
I read this paper in detail, and I am very sad! They literally re-do the optimal reward baseline work that we have known since forever, without even crediting the true authors in their derivations. The third screenshot is taken from: ieeexplore.ieee.org/stamp/stamp.js… As you see, they…
It’s almost hilarious that he chose to mention US space program. Who tells him what happened when a founding figure of JPL was expelled for the exact same reasons they use today?
Vance: I've heard a lot of the criticisms, the fear that we're going to have a brain drain. If you go back to the 50s and 60s, the American space program, the program that was the first to put a human being on the surface of the moon was built by American citizens. Some German…