
Fei Wang
@fwang_nlp
PhD @USC. Trustworthy (Multimodal) LLMs.
🚨 DPO works well on LLMs, but what happens when we apply it to VLMs/MLLMs? 🚀 Excited to introduce our #EMNLP2024 work on DPO for Multimodal LLMs! We identify the unconditional preference issues (where the model 𝐨𝐯𝐞𝐫𝐥𝐨𝐨𝐤𝐬 𝐯𝐢𝐬𝐮𝐚𝐥 𝐜𝐨𝐧𝐭𝐞𝐱𝐭), leading to severe…
1+1=3 2+2=5 3+3=? Many language models (e.g., Llama 3 8B, Mistral v0.1 7B) will answer 7. But why? We dig into the model internals, uncover a function induction mechanism, and find that it’s broadly reused when models encounter surprises during in-context learning. 🧵
A little late but nevertheless happy to share that our paper “Outlier Gradient Analysis: Efficiently Identifying Detrimental Training Samples for Deep Learning Models” was accepted as an oral presentation at #ICML2025 (top 1%). More details here: arxiv.org/pdf/2405.03869!
🚀 Check out our paper: WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model, from Tencent AI Lab!. We present a world model-driven framework for self-improving web agents, addressing critical challenges in self-training—such as limited exploration and…
🚨 New paper accepted to #ACL2025! We propose SudoLM, a framework that lets LLMs learn access control over parametric knowledge. Rather than blocking everyone from sensitive knowledge, SudoLM grants access to authorized users only. Paper: arxiv.org/abs/2410.14676… 🧵[1/6]👇
Can LLM guardrails think twice before deciding? ✨ Check out our #ACL2025 paper: THINKGUARD — a critique-augmented safety guardrail! ✅ Structured critiques ✅ Interpretable decisions ✅ Robust against adversarial prompts 📑 arxiv.org/abs/2502.13458 🧵[1/n]
🔦 Speaker Spotlight: Sercan Ö. Arık (@sercanarik) We're thrilled to welcome Sercan, Senior Staff Research Scientist at Google Cloud AI, as an invited speaker at the ICML 2025 Workshop on Computer Use Agents! Sercan's focuses on democratizing AI and applying it to impactful use…
Worried about backdoors in LLMs? 🌟 Check out our #NAACL2025 work on test-time backdoor mitigation! ✅ Black-box 📦 ✅ Plug-and-play 🛡️ We explore: → Defensive Demonstrations 🧪 → Self-generated Prefixes 🧩 → Self-refinement ✍️ 📄 arxiv.org/abs/2311.09763 🧵[1/n]
🧵1/ Excited to share our #NAACL2025 work! 🎉 "Assessing LLMs for Zero-Shot Abstractive Summarization Through the Lens of Relevance Paraphrasing" We study how robust LLM summarization is to our relevance paraphrasing method? 🧠📝 More details below:👇 arxiv.org/abs/2406.03993
Should multimodal in-context learning demonstrations mirror the visual or textual patterns of test instances? I'll present paper “From Introspection to Best Practices: Principled Analysis of Demonstrations in Multimodal In-Context Learning” on April 30th at NAACL. See you there!
🚨 New paper 🚨 Excited to share my first paper w/ my PhD students!! We find that advanced LLM capabilities conferred by instruction or alignment tuning (e.g., SFT, RLHF, DPO, GRPO) can be encoded into model diff vectors (à la task vectors) and transferred across model…
Thrilled to be featured in the #ICLR2025 Spotlight! 🎉 Come see our poster in Hall 3 + Hall 2B #602, April 25, 10:00–12:30 PM SGT
Thank you so much for sharing our work! @_akhaliq We present 💥AutoDAN-Turbo, a lifelong agent designed for the jailbreak redteaming task. Three key features: ⚙️ Lifelong automatic jailbreak. Simply run the agent, and it will explore the jailbreak stratgies and evaluate the…
Excited to share our papers at #ICLR2025 in Singapore! Check out the summaries on our blog (ccgblog.seas.upenn.edu/2025/04/ccg-pa…), and then check out the papers at oral session 1B (BIRD) and poster session 2 (for all three)! @AnnieFeng6, @XingyuFu2, @BenZhou96, @muhao_chen, @DanRothNLP
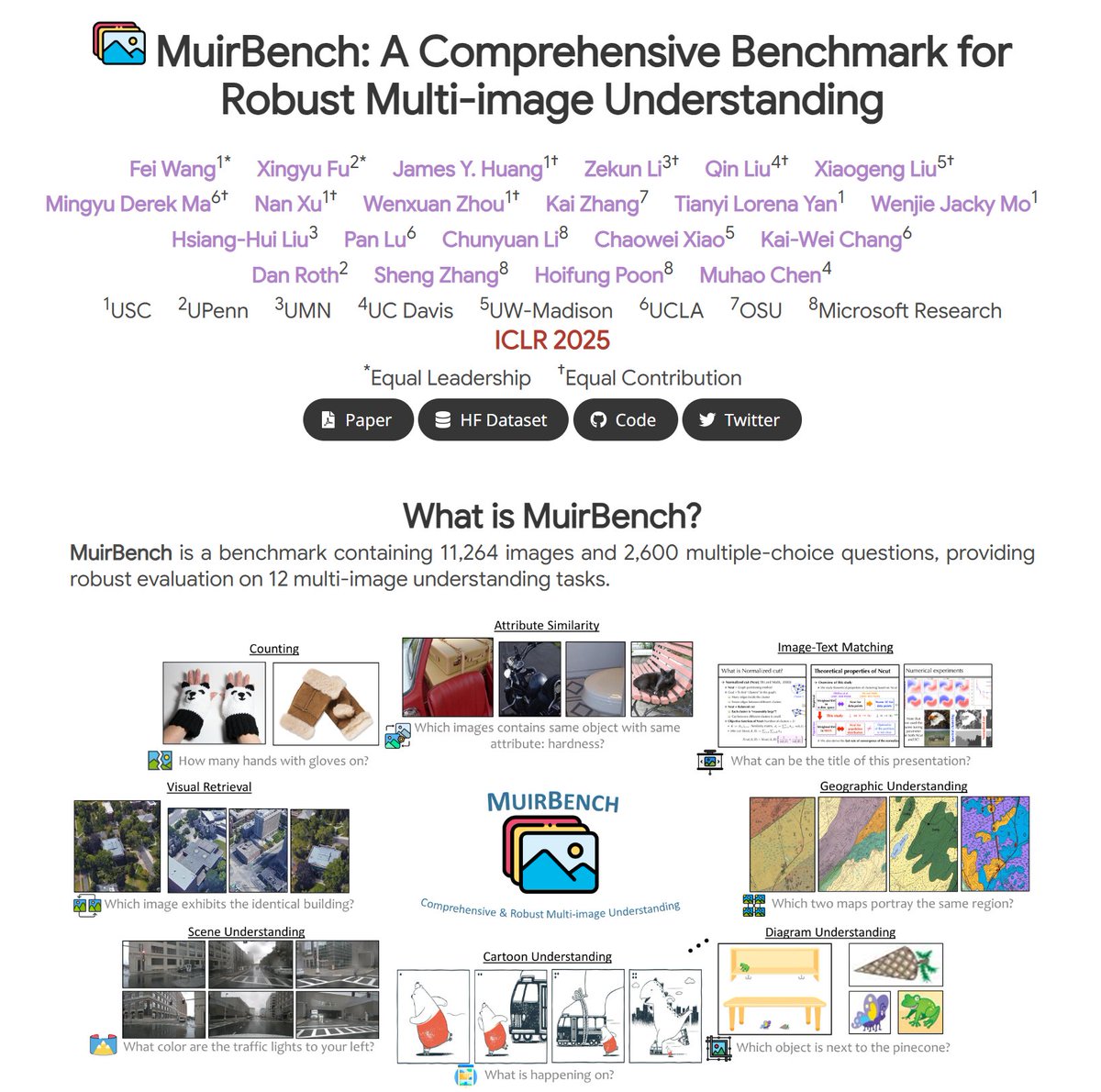
🎉 Excited to share that our paper, "MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding", will be presented at #ICLR2025! 📅 Date: April 24 🕒 Time: 3:00 PM 📍 Location: Hall 3 + Hall 2B #11 MuirBench challenges multimodal LLMs with diverse multi-image…
#ICLR2025 Oral LLMs often struggle with reliable and consistent decisions under uncertainty 😵💫 — largely because they can't reliably estimate the probability of each choice. We propose BIRD 🐦, a framework that significantly enhances LLM decision making under uncertainty. BIRD…
Curious how LLMs tackle planning tasks, such as travel and computer use? Our new survey #PlanGenLLMs (arxiv.org/abs/2502.11221) builds on classic work by Kartam and Wilkins (1990) and examines 6 key metrics to compare today's top planning systems. Your next agentic workflow…
📢 Research internship @Google📢 I am looking for a PhD student researcher to work with me and my colleagues on advanced reasoning and/or RAG factuality this summer @Google Mountain View, CA. We will focus on open-source models and benchmarks, and aim to publish our findings.…
🤖 Imagine a world where everyone has a personalized LLM agent by their side! Our latest research (arxiv.org/abs/2502.12149) explores how persona dynamics influence multi-agent competitive auctions. 🏆 Discover who wins, who loses, and the impact of personas on competitiveness!
When answering queries with multiple answers (e.g., listing cities of a country), how do LMs simultaneously recall knowledge and avoid repeating themselves? 🚀 Excited to share our latest work with @robinomial! We uncover a promote-then-suppress mechanism: LMs first recall all…
I know internship hunting has been especially tough this year -- I hear you! 📢Great news: Our team at Microsoft Research (@MSFTResearch) has opened up a few additional internship slots for this summer! We're seeking talented PhD candidates with experience in 🖼️Multimodality,…
🚀 Excited to share MetaScale, our latest work advancing LLM reasoning capabilities! MetaScale empowers GPT-4o to match or even surpass frontier reasoning models like o1, Claude-3.5-Sonnet, and o1-mini on the challenging Arena-Hard benchmark (@lmarena_ai). Additionally, MetaScale…