Fei Liu
@feiliu_nlp
Associate professor @EmoryUniversity. Working on large language models, LLM inference, reasoning, natural language generation, and various aspects of GenAI.
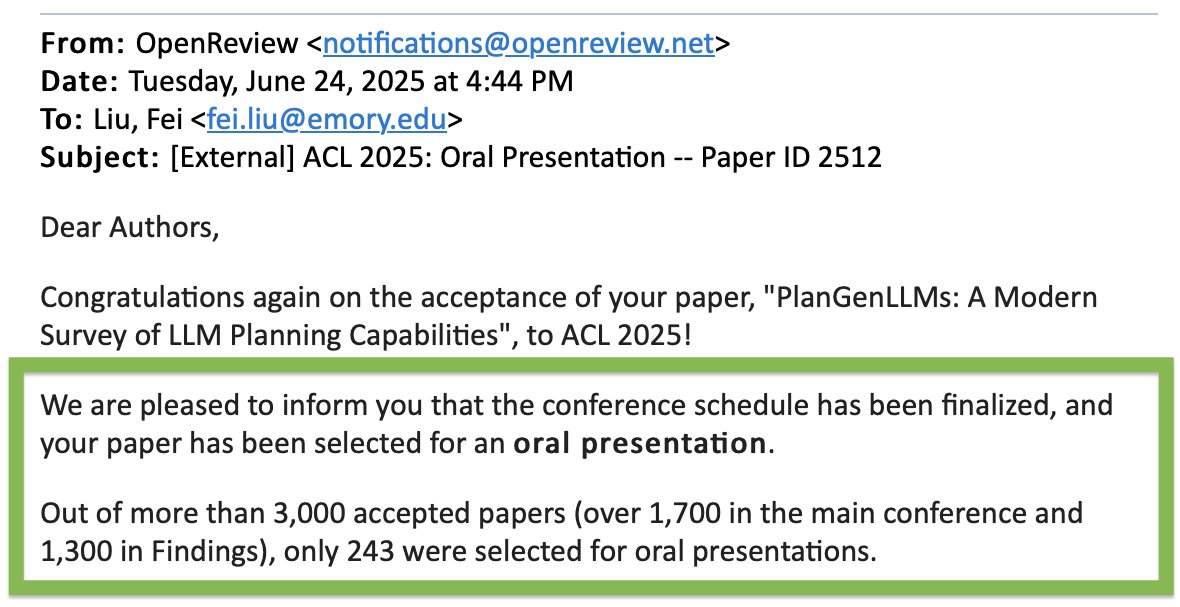
Happy to share our paper got selected as an Oral Presentation at #ACL2025! Out of 8,000+ submissions and 3,000+ accepted papers, only 245 were chosen for oral (<3%)! Our amazing first author Hui Wei can't travel, so I'll be presenting in Vienna. Hope to see you there! 🇦🇹 📄…
Just watched Nathan's recent talk and really enjoyed it. Around 19:30 is where it gets really interesting. Totally agree that planning is the exciting frontier. If you're curious, our recent survey #PlanGenLLMs is a great place to start: arxiv.org/pdf/2502.11221…
Here's a recent talk I gave recapping the last 6-12 months of AI progress, why getting perfect models is hard, how labs are likely approaching the next phase of training (for agents), and other interesting tidbits across the reasoning landscape. Topics: 00:00 Introduction & the…
Just watched John Oliver's episode on AI Slop and loved it. He describes AI slop as the flood of low-quality, AI-generated content: music, images, short videos, maybe even news articles, books, research papers, code... you name it. Feels like we're (almost) drowning in it. Real…

❄️We're looking for a MLE/Applied Scientist to join our @Snowflake AI team to work on AI+Software Engineering. If you have sharp eyes to find potential pain points for developers and can solve with AI, this job is just for you! 👉Apply here: careers.snowflake.com/us/en/job/SNCO…
try creating reels from longer videos with reka vision: app.reka.ai/vision/reels watch the video below or check out this user guide for more details reka.ai/reel-generatio… we are adding more prompt-based editing capabilities very soon!
I’m looking for a new postdoc to start this fall working on AI for Science/Science-Inspired AI (focusing on chemistry and bioengineering domains for now). Please drop me a CV if interested.
Pokémon Red has recently emerged as an evaluation benchmark, adopted by several top AI labs. But is it really a good benchmark for evaluating LLM capabilities or guiding LLM research? We wrote this blog to dive into the challenges, surface the opportunities, and introduce…
🔥 Pokémon Red is becoming a go-to benchmark for testing advanced AIs such as Gemini. But is Pokémon Red really a good eval? We study this problem and identify three issues: 1️⃣ Navigation tasks are too hard. 2️⃣ Combat control is too simple. 3️⃣ Raising a strong Pokémon team is…
Autonomous agents are powerful, but without guardrails, they drift into inefficiency. We view 'cost' as a form of guardrail and use Monte Carlo Tree Search with explicit cost-awareness to guide LLM-based planning. Tight cost constraints push the planner to quickly identify…
Anthropic staff realized they could ask Claude to buy things that weren’t just food & drink. After someone randomly decided to ask it to order a tungsten cube, Claude ended up with an inventory full of (as it put it) “specialty metal items” that it ended up selling at a loss.
Q-learning is not yet scalable seohong.me/blog/q-learnin… I wrote a blog post about my thoughts on scalable RL algorithms. To be clear, I'm still highly optimistic about off-policy RL and Q-learning! I just think we haven't found the right solution yet (the post discusses why).
My high-level take on why multimodal reasoning is fundamentally harder than text-only reasoning: Language is structured and directional, while images are inherently unstructured—you can start reasoning from anywhere. This visual freedom makes step-by-step logical inference much…
Revisited @andy_l_jones's RL debugging post from a few years back. Still one of the most insightful guides out there. If your agent's acting weird, here's a great checklist: andyljones.com/posts/rl-debug…

✨ Our paper #PlanGenLLMs: A Modern Survey of LLM Planning Capabilities (arxiv.org/pdf/2502.11221) is accepted to the #ACL2025 main conference! Huge thanks to the reviewers for the unanimous 4-4-4 reviews and meta score ❤️ Grateful for your thoughtful feedback! #ACL2025 #NLProc

✨ Excited to share that our paper "#DeFine: Decision-Making with Analogical Reasoning" has been accepted to #ACL2025 Findings! 🙌 We study how LLMs can better handle uncertainty in complex scenarios using analogical reasoning. Congrats to my amazing students and collaborators!…

I’ve seen many questions about how to choose ARR tracks for submissions aim at the new tracks at #emnlp2025. We actually wrote a blogpost along with the 2nd CFP exactly to address this: 2025.emnlp.org/track-changes/ Please help us share it widely! Good luck with your emnlp submissions!
Happy to see #EMNLP2025 introducing new tracks on AI/LLM Agents, Code Models, Safety & Alignment, Reasoning, LLM Efficiency, and more. Big thanks to the organizers for making this happen! @emnlpmeeting #NLProc Perfect venue for agentic research and language technologies.…
Happy to see #EMNLP2025 introducing new tracks on AI/LLM Agents, Code Models, Safety & Alignment, Reasoning, LLM Efficiency, and more. Big thanks to the organizers for making this happen! @emnlpmeeting #NLProc Perfect venue for agentic research and language technologies.…
New AI/LLM Agents Track at #EMNLP2025! In the past few years, it feels a bit odd to submit agent work to *CL venues because one had to awkwardedly fit it into Question Answering or NLP Applications. Glad to see agent research finally finds home at *CL! Kudos to the PC for…
Just got back from the #ICLR2025 trip, grateful for the conversations, questions, and inspiring talks. Thought I'd share a few reflections from the conference (not exhaustive, just things that stuck with me). 1. Can reasoning learned from code/math generalize to all problems?…
Got questions about research, careers, or just want to chat? 💕 Join us Friday 4/25 at 12:30-1:15pm for Mentorship Hour in the Topaz Concourse. See you there! #ICLR2025 #NLProc
