
Tianqing Fang
@TFang229
Researcher @TencentGlobal AI Lab | PhD @HKUST (@HKUSTKnowComp) | Former intern @epfl_en, @CSatUSC, @NVIDIAAI
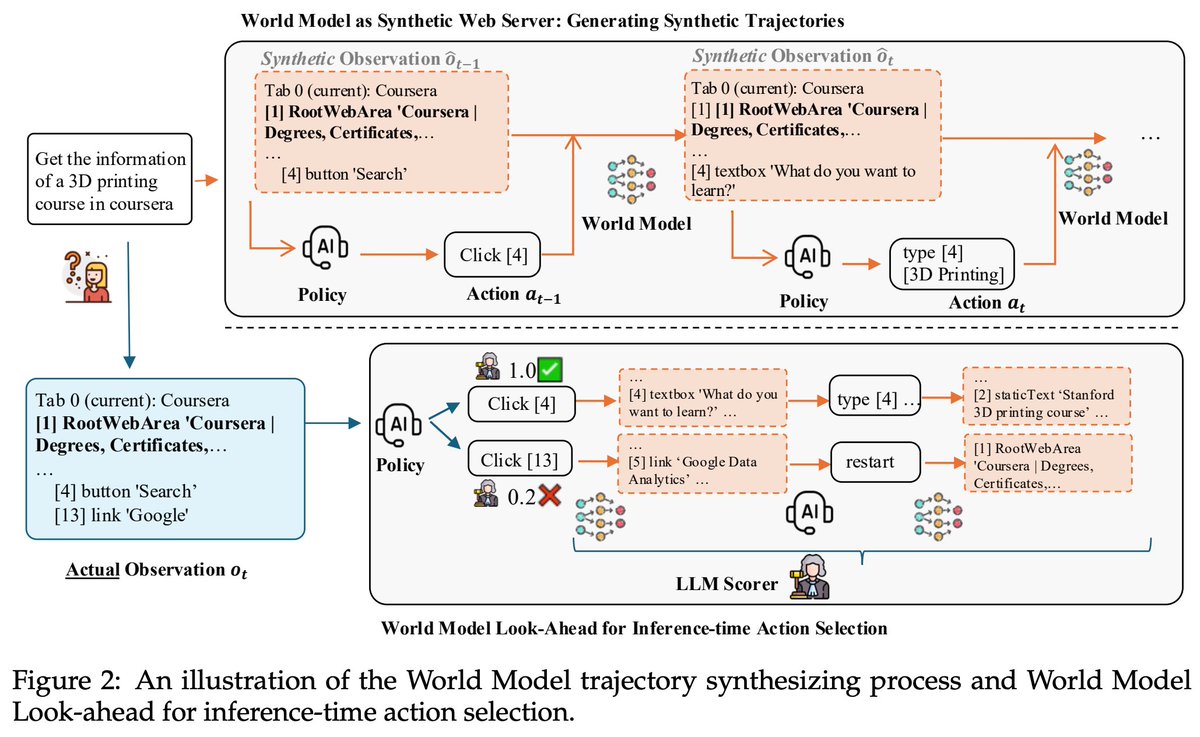
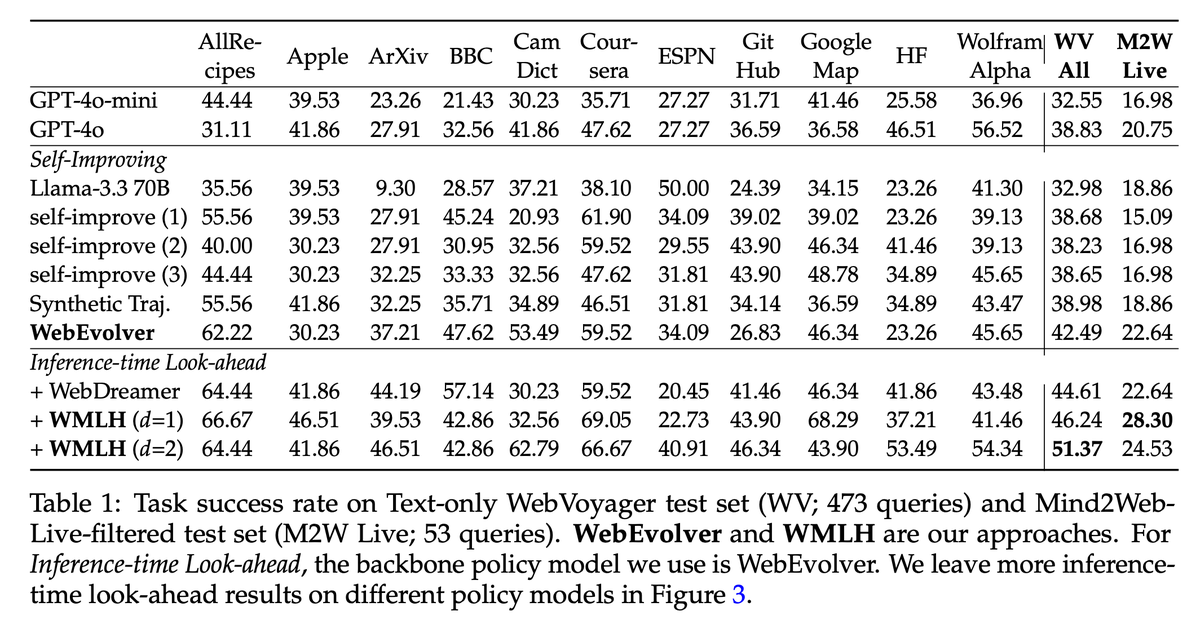
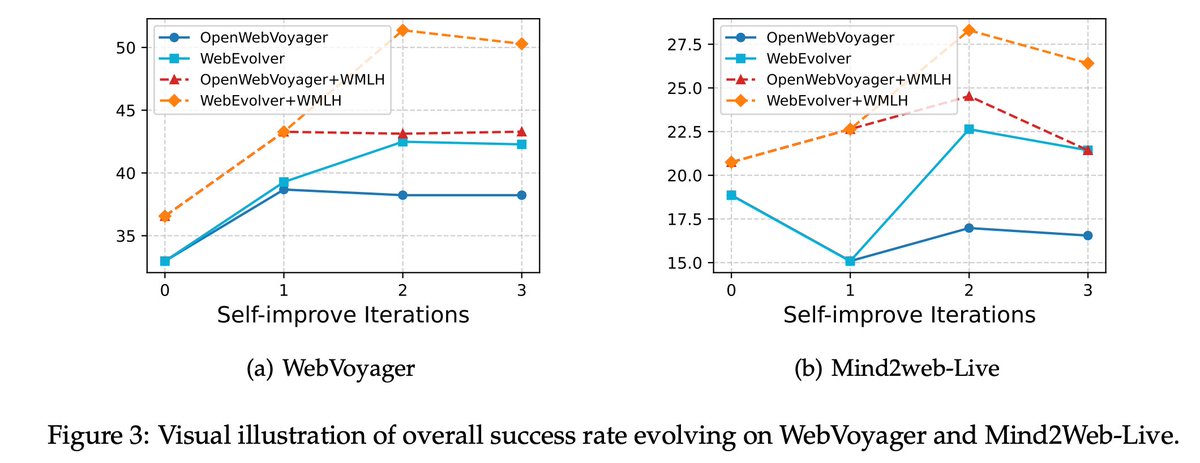
🚀 Check out our paper: WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model, from Tencent AI Lab!. We present a world model-driven framework for self-improving web agents, addressing critical challenges in self-training—such as limited exploration and…

My earlier work #VLM2Bench called for clearer principles on *when* language aids vision. Our new work **MindCube**: *First Map then Reasoning* puts this into practice—tackling limited-view spatial reasoning with appropriate language-side mapping. Welcome check it out! 🚀
Can VLMs build Spatial Mental Models like humans? Reasoning from limited views? Reasoning from partial observations? Reasoning about unseen objects behind furniture / beyond current view? Check out MindCube! 🌐mll-lab-nu.github.io/mind-cube/ 📰arxiv.org/pdf/2506.21458…
🚀 Introducing VScan! A two-stage visual token reduction framework for efficient multimodal LLMs, enabling up to 2.91× faster inference and 10× fewer FLOPs -- while keeping 95.4% of original performance. Check it out at arxiv.org/abs/2505.22654!
We have some interesting findings in our recent work "One Token to Fool LLM-as-a-Judge" (arxiv.org/abs/2507.08794) that will affect RLVR with generative reward models.
🚀 Thrilled to share our new paper at Tencent AI Lab! We introduce a framework DRP-IMO that proves 5 post-2000 IMO problems — a set where no prior open-source prover has solved a single one. 🤯 Link: arxiv.org/pdf/2507.06804 Details in thread👇
📢 New paper alert 📢 We introduce MobileGUI-RL, an RL framework advancing mobile GUI agents through trajectory-based rollouts and rewards in 𝗼𝗻𝗹𝗶𝗻𝗲 environments. With RL, Qwen 2.5-VL achieves 44.8% Success on Android World! ✨ Checkout paper at: arxiv.org/abs/2507.05720
Thank you for mentioning our paper, VScan! Hope more people will pay attention to this interesting field. The code was recently released: github.com/Tencent/SelfEv… arxiv: arxiv.org/abs/2505.22654
Lately I'm seeing lots of papers about token pruning in VLMs The goal is to reduce the number of visual tokens which are usually the bottleneck Imagine an image and the question "how many buses in the image?": the visual tokens are ~1000, the text tokens are ~10, so ... [1/4]
Excited to share our recent work on agentic task generation! TaskCraft is designed to synthesize agentic tasks for agent RL, agent optimization, and agent evaluation.
🚀 Hello everyone! We are excited to share our latest work, TaskCraft, which marks the first automated approach for generating and evaluating Agentic Tasks! Paper: arxiv.org/abs/2506.10055 Code : github.com/OPPO-PersonalA… Data : huggingface.co/datasets/Perso… 👇 [1/n]
It’s so exciting to see BioCLIP 2 demonstrates a biologically meaningful embedding space while only trained to distinguish species. Can’t wait to see more applications of BioCLIP 2 in solving real world problems. I’m attending #CVPR2025 in Nashville. Happy to chat about it!
📈 Scaling may be hitting a wall in the digital world, but it's only beginning in the biological world! We trained a foundation model on 214M images of ~1M species (50% of named species on Earth 🐨🐠🌻🦠) and found emergent properties capturing hidden regularities in nature. 🧵
impressive work👍
Thrilled to share a major milestone: the culmination of a 15-month project, ATLAS—a new benchmark in event graphs and conceptualization! This journey began with Probase in 2012, evolved through ASER (2019), AbstractATOMIC (2022), and AbsPyramid (2023), and now realizes a…
Introducing MCIP: A Safer Model Contextual Integrity Protocol for LLMs! Enhanced with tracking tools & a guard model, MCIP tackles safety risks in MCP interactions. Our taxonomy & benchmark reveal LLM vulnerabilities, improving safety by up to 40.81%. #AI #LLMSafety #MCIP #MCP…
Can image safeguards be bypassed by breaking harmful prompts into harmless steps? ⚠️ Introducing Chain-of-Jailbreak (CoJ) Attack, a novel method showing how image generation models (e.g., GPT-4V/o, Gemini 1.5) can be compromised by decomposing malicious queries into a…
🚨 Announcing DeepTheorem: Revolutionizing LLM Mathematical Reasoning! 🚀 𝕋𝕃𝔻ℝ: - 🌟 Learning by exploration is the most important rationale that recent RL-zero training teaches us since self-exploration significantly boosts the utilization of LLM pre-training knowledge; -…
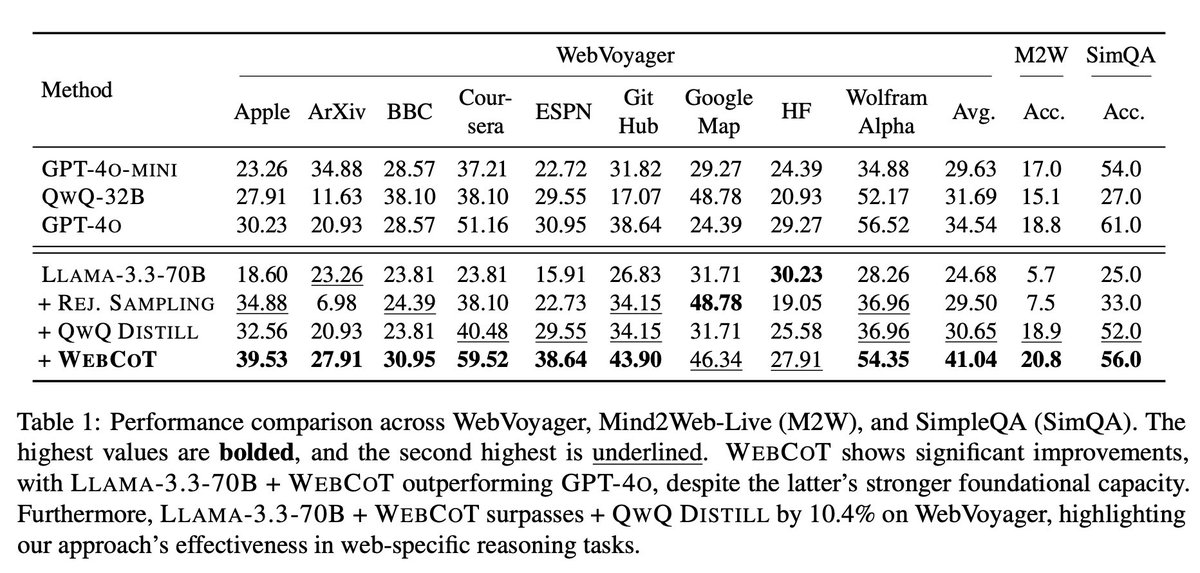
🚀 Introducing WebCoT! By capturing and verbalizing web agent cognitive patterns (reflection, branching, rollback) as chain-of-thought, WebCoT outperforms rejection sampling distillation by 10% on WebVoyager, Mind2web-live, and SimpleQA. arxiv.org/pdf/2505.20013


Check out our work of navigation agent using Large Vision Language Models!
🧐Can we create a navigational agent that can handle thousands of new objects across a wide range of scenes? 🚀 We introduce DivScene bench and NatVLM. DivScene contains houses of 81 types and thousands of target objects. NatVLM is an end-to-end agent based on a Large Vision…
#ACL2024 I'll be giving an oral presentation at 17:15 in World Ballroom B on my previous work about how to indirectly apply constraining to Blackbox LLM. arxiv.org/abs/2401.09967 I’d love to chat about LLM inference, constrained decoding, or any interesting ideas :)
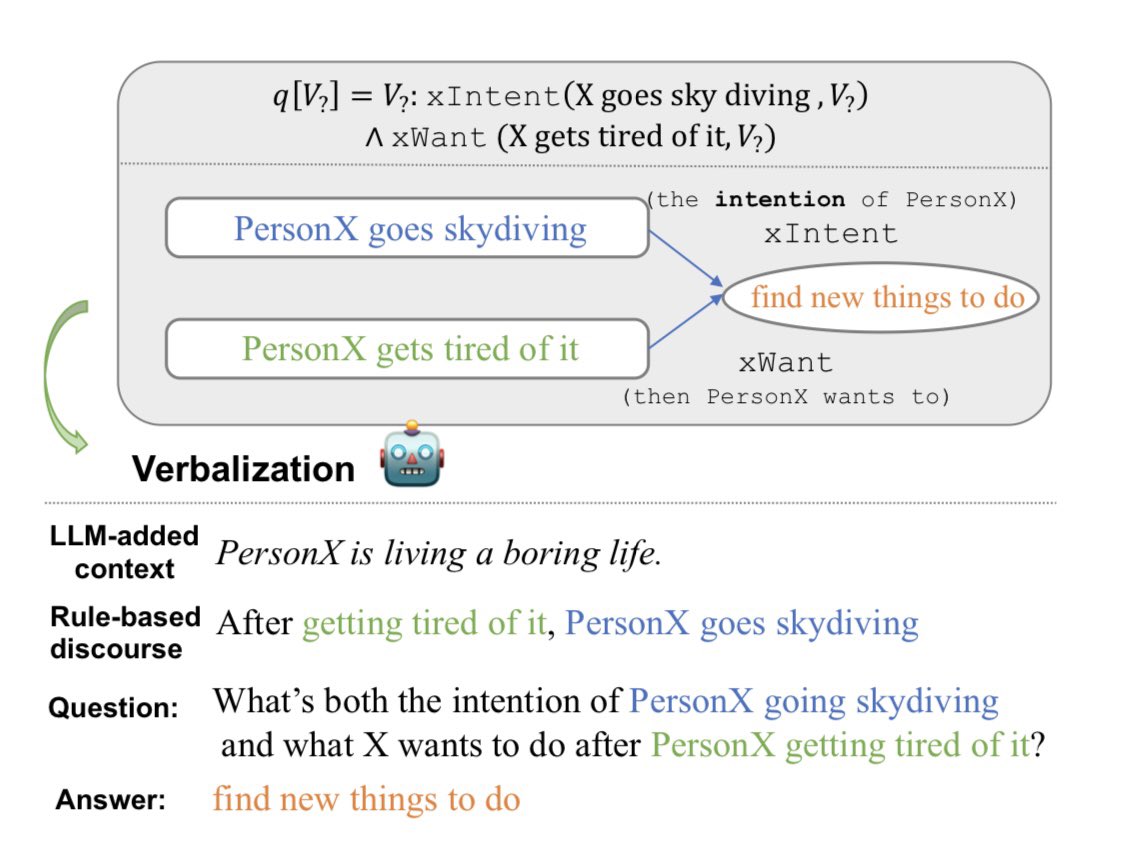
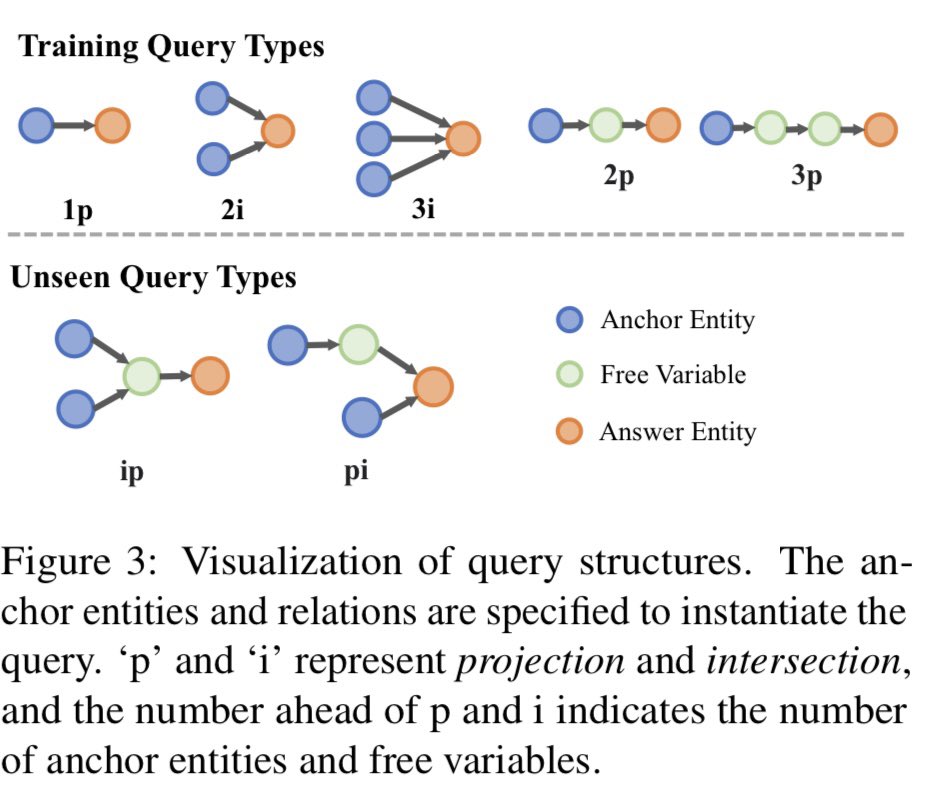
Check out our ACL 2024 paper Complex Commonsense Reasoning over Logical Queries on Commonsense Knowledge Graphs (arxiv.org/pdf/2403.07398). The poster session will be 13 August (Tuesday) 4pm! Come and say Hi #NLProc #ACL2024


Nice to meet everyone in #ACL2024 Findings in person session 2 today at 17:45.
“Concepts are the glue that holds our mental world together.”– Murphy (2004) I started to work on conceptualization in 2010 when I joined #MSRA to work on #Probase (haixun.github.io/probase.html) with Haixun Wang @haixunwang . At that time, we leveraged Probase to conceptualize things…
🎉Our work is accepted by ACL 2024: AbsInstruct: Eliciting Abstraction Ability from LLMs through Explanation Tuning with Plausibility Estimation. While previous evaluations show that LLMs lack abstraction ability, do LLMs already own a lot of abstraction knowledge? The answer is…