Tu Vu
@tuvllms
Research Scientist @GoogleDeepMind & Assistant Professor @VT_CS. PhD from @UMass_NLP. Google FLAMe/FreshLLMs/Flan-T5 Collection/SPoT #NLProc
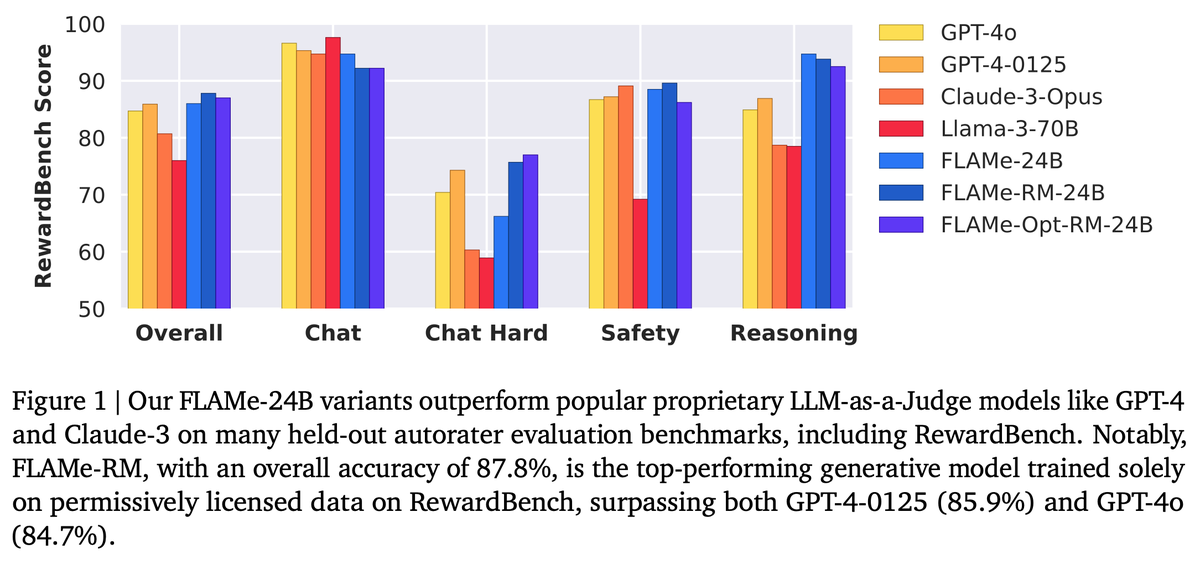
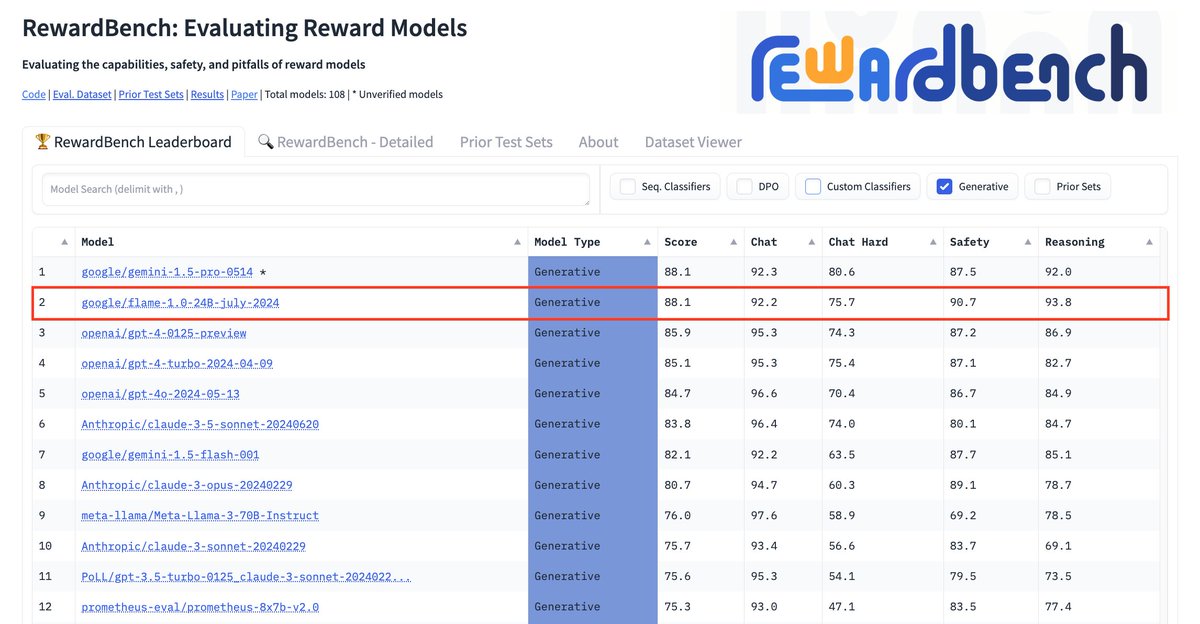
🚨 New @GoogleDeepMind paper 🚨 We trained Foundational Large Autorater Models (FLAMe) on extensive human evaluations, achieving the best RewardBench perf. among generative models trained solely on permissive data, surpassing both GPT-4 & 4o. 📰: arxiv.org/abs/2407.10817 🧵:👇
In our continued commitment to open-science, we are releasing the Voxtral Technical Report: arxiv.org/abs/2507.13264 The report covers details on pre-training, post-training, alignment and evaluations. We also present analysis on selecting the optimal model architecture, which…
Kimi K2 paper dropped! describes: - MuonClip optimizer - large-scale agentic data synthesis pipeline that systematically generates tool-use demonstrations via simulated and real-world environments - an RL framework that combines RLVR with a self- critique rubric reward mechanism…
Official results are in - Gemini achieved gold-medal level in the International Mathematical Olympiad! 🏆 An advanced version was able to solve 5 out of 6 problems. Incredible progress - huge congrats to @lmthang and the team! deepmind.google/discover/blog/…
Excited to share that a scaled up version of Gemini DeepThink achieves gold-medal standard at the International Mathematical Olympiad. This result is official, and certified by the IMO organizers. Watch out this space, more to come soon! deepmind.google/discover/blog/…
This year was a major paradigm shift, where we can solve problems end to end in natural language. With novel reinforcement learning techniques, we are able to train an advanced Gemini model on multi-step reasoning proof data, which advances the model's capabilities in terms of…
An advanced version of Gemini with Deep Think has officially achieved gold medal-level performance at the International Mathematical Olympiad. 🥇 It solved 5️⃣ out of 6️⃣ exceptionally difficult problems, involving algebra, combinatorics, geometry and number theory. Here’s how 🧵
My Reinforcement Learning (RL) & Agents 3 hour workshop is out! I talk about: 1. RL fundamentals & hacks 2. "Luck is all you need" 3. Building smart agents with RL 4. Closed vs Open-source 5. Dynamic 1bit GGUFs & RL in @UnslothAI 6. The Future of Training youtube.com/watch?v=OkEGJ5…
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
Free 1-year Google Colab Pro subscriptions for verified US students and faculty
Big news for data science in higher ed! 🚀Colab now offers 1-year Pro subscriptions free of charge for verified US students/faculty, interactive Slideshow Mode for lectures, & an AI toggle per notebook. Enhance teaching & learning in the upcoming academic year! Read all about it…
Excited to talk about long-context models / eval at this panel on Saturday! I'm also looking for a postdoc / PhD students to work on related topics, happy to chat with anyone interested at #ICML2025!
💡 Curious about long-context foundation models (LFCM)? 🧠 We’re hosting a panel at the LCFM workshop at #ICML2025 on “How to evaluate long-context foundation models?” — We’d love to feature your question! Anything on long-context evaluation or modeling — drop it below / DM me🎤
Students from @SanghaniCtrVT are working as interns across the country on projects that run the gamut of AI, data analytics & ML, including LLMs. Read a roundup of the students and the work they are doing: tinyurl.com/2rdy267k 🔽Ph.D. student Quyet Do @Adobe in San Jose, CA.
Becoming an RL diehard in the past year and thinking about RL for most of my waking hours inadvertently taught me an important lesson about how to live my own life. One of the big concepts in RL is that you always want to be “on-policy”: instead of mimicking other people’s…
considering Muon is so popular and validated at scale, we've just decided to welcome a PR for it in PyTorch core by default. If anyone wants to take a crack at it... github.com/pytorch/pytorc…
New from our security teams: Our AI agent Big Sleep helped us detect and foil an imminent exploit. We believe this is a first for an AI agent - definitely not the last - giving cybersecurity defenders new tools to stop threats before they’re widespread.
(1/4)🚨 Introducing Goedel-Prover V2 🚨 🔥🔥🔥 The strongest open-source theorem prover to date. 🥇 #1 on PutnamBench: Solves 64 problems—with far less compute. 🧠 New SOTA on MiniF2F: * 32B model hits 90.4% at Pass@32, beating DeepSeek-Prover-V2-671B’s 82.4%. * 8B > 671B: Our 8B…
One Token to Fool LLM-as-a-Judge Watch out for this one, devs! Semantically empty tokens, like “Thought process:”, “Solution”, or even just a colon “:”, can consistently trick models into giving false positive rewards. Here are my notes:
Honored to get the outstanding position paper award at @icmlconf :) Come attend my talk and poster tomorrow on human centered considerations for a safer and better future of work I will be recruiting PhD students at @stonybrooku @sbucompsc coming fall. Please get in touch.
Very excited for a new #ICML2025 position paper accepted as oral w @mbodhisattwa & @TuhinChakr! 😎 What are the longitudinal harms of AI development? We use economic theories to highlight AI’s intertemporal impacts on livelihoods & its role in deepening labor-market inequality.
Our independent evaluation on reasoning over conflicting evidence with SEAL-0 shows that Grok 4 is a strong model, though its performance gaps with other frontier models like Gemini-2.5-Pro and o3-pro are small.
We just evaluated Grok 4 on our SEAL-0 dataset 👍Try it: huggingface.co/datasets/vtllm…
There’s a secret code if you observe the authors’ first initials in the order of authorship: “GEMINI MODELS CAN THINK AND GET BACK TO YOU IN A FLASH” Nice little Easter Egg @GoogleDeepMind 🥚
Every ML Engineer’s dream loss curve: “Kimi K2 was pre-trained on 15.5T tokens using MuonClip with zero training spike, demonstrating MuonClip as a robust solution for stable, large-scale LLM training.” arxiv.org/abs/2502.16982
🚀 Hello, Kimi K2! Open-Source Agentic Model! 🔹 1T total / 32B active MoE model 🔹 SOTA on SWE Bench Verified, Tau2 & AceBench among open models 🔹Strong in coding and agentic tasks 🐤 Multimodal & thought-mode not supported for now With Kimi K2, advanced agentic intelligence…