
Furong Huang
@furongh
Associate professor of @umdcs @umiacs @ml_umd at UMD. Researcher in #AI/#ML, AI #Alignment, #RLHF, #Trustworthy ML, #EthicalAI, AI #Democratization, AI for ALL.
🌟 A series of LLM Alignment & RLHF progress from our group 👉 1️⃣ PARL: Pioneering bilevel formulations for policy-driven data dependency. 🔗: arxiv.org/abs/2308.02585 2️⃣ SAIL: Elevating LLM alignment with principled, efficient solutions. 🔗: arxiv.org/abs/2406.15567 3️⃣ Transfer Q…
Everyone’s hyped about test-time scaling—more steps, longer traces, just add “Wait” or “Let me rethink,” and boom: better reasoning? Not quite. We find that performance almost always improves at first—then declines. Classic overthinking. That’s not news. But why does it happen?…
🔥 Does test-time scaling in #reasoningmodels via thinking more always help? 🚫 Answer is No - Performance increases first and then drops due to #Overthinking ❓Why is this behaviour and how to mitigate 🚀 Check our recent findings #LLMReasoning Link: arxiv.org/pdf/2506.04210
Great minds think alike! 👀🧠 We also found that more thinking ≠ better reasoning. In our recent paper (arxiv.org/abs/2506.04210), we show how output variance creates the illusion of improvement—when in fact, it can hurt precision. Naïve test-time scaling needs a rethink. 👇…
New Anthropic Research: “Inverse Scaling in Test-Time Compute” We found cases where longer reasoning leads to lower accuracy. Our findings suggest that naïve scaling of test-time compute may inadvertently reinforce problematic reasoning patterns. 🧵
This inspired me.
Someone on LinkedIn posted about cool theoretical research that he wants to check, and someone from AMD just told him that they will give him the compute 😍
🤣
You can tell the RL is done properly when the models cease to speak English in their chain of thought
Apparently Dion is now being worked on for Torch Titan: github.com/pytorch/torcht… :-)
Since nobody asked :-), here is my list of papers not to be missed from ICML: 1) Dion: distributed orthonormalized updates (well, technically not at ICML, but everyone's talking about it). 2) MARS: Unleashing the Power of Variance Reduction for Training Large Models 3) ...
Congratulations @TahseenRab74917!
Come to CFAgentic at #ICML2025 in West 215-216 to watch me discuss how LoRA secretly reduces memorization. Afterwards I'm joining a panel to discuss the future of collaborative learning + agents. 🕐: 4:05-5:00pm Workshop: cfagentic.github.io 📰: arxiv.org/pdf/2502.05087
x.com/furongh/status…
AegisLLM leverages DSPy's MIPROv2 optimizer in a totally unexpected way: to evolve its prompts based on the attacks it sees in real time. Some really large gains!
🐭🔒 LLM security is a cat-and-mouse game. Attackers adapt. Prompts mutate. Meanwhile, most defenses? 🚫 Static. Fragile. One-shot fixes. It’s time for something smarter. ⚔️ Meet AegisLLM: An agentic runtime defense that thinks, reacts, and learns — just like the attackers do.…
If you are interested in building agentic workflows, AegisLLM is a nice instantiation in safety/security domain! Thanks @furongh for sharing it with me. Agentic workflows must be designed and optimized as systems, as @lateinteraction keeps repeating.
Excited to give a tutorial with @leenaCvankadara on Training Neural Networks at Any Scale (TRAINS) @icmlconf at 13:30 (West Ballroom A). Our slides can be found here: go.epfl.ch/ICML25TRAINS Please join us.
Highly recommend
@caglarml and I are excited to share our lecture slides for EE-628 Training Large Language Models course: epfl.ch/labs/lions/tea… If you have any feedback, please reach out to us. I am also at #ICLR25.
Congratulations!
Even the smartest LLMs can fail at basic multiturn communication Ask for grocery help → without asking where you live 🤦♀️ Ask to write articles → assumes your preferences 🤷🏻♀️ ⭐️CollabLLM (top 1%; oral @icmlconf) transforms LLMs from passive responders into active collaborators.…
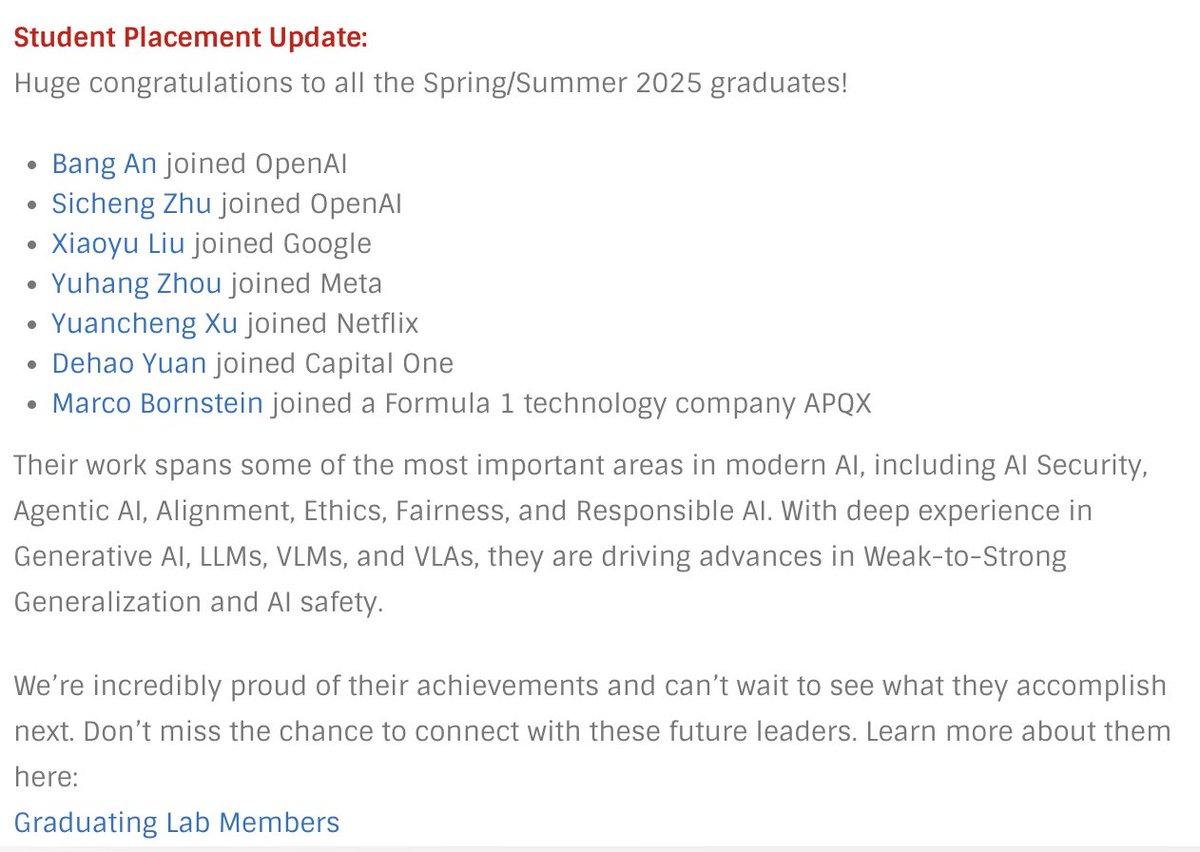
This Spring/Summer 2025, I’m incredibly proud of our lab’s graduating students and their next steps: Bang An @bang_an_ and Sicheng Zhu @sichengzhuml joined OpenAI @OpenAI Xiaoyu Liu @xiaoyu_liu_1231 joined Google @Google Yuhang Zhou @YuhangZhou2 joined Meta @Meta Yuancheng Xu…

Second Panel at WiML @ ICML 2025! Join @__alucic, @_beenkim, @furongh & @MeganRisdal as they share what’s missing, what’s broken, and what still needs to change in AI. 🎙️ With Natasha Jaques as a moderator 🗓️ July 16 | 2:00 PM #WiML #ICML2025 #WomenInML
As many of you know, I’ve been spending my sabbatical at Capital One with Bayan Bruss @cbbruss’s amazing team, under Prem Natarajan and Milind Naphade. Bayan has been the most supportive and visionary leader: deeply attentive to the technical work across the group. Excited to…

There’s been heated debate lately: Can generative AI truly self-improve? ✅Some say yes, pointing to models learning like curious humans. ❌Others say no, invoking the first law of thermodynamics: You can’t get something from nothing. No new info, no gain. 🧠 But what if the…
Introducing MORSE-500 🌐 morse-500.github.io 500 scripted videos that stress-test six reasoning skills — beyond math, beyond static pics, built to get harder. Key Features: 🚀 Fresh & Portable 🎯 Diverse Categories 👁️ Pure Visual Cues 📈 Scalable Difficulty Dive in 🧵