
Aryo Pradipta Gema
@aryopg
AI Safety Fellow @Anthropic | PhD student @BioMedAI_CDT @EdinburghNLP @EdiClinicalNLP LLM Hallucinations | Clinical NLP | Opinions are my own.
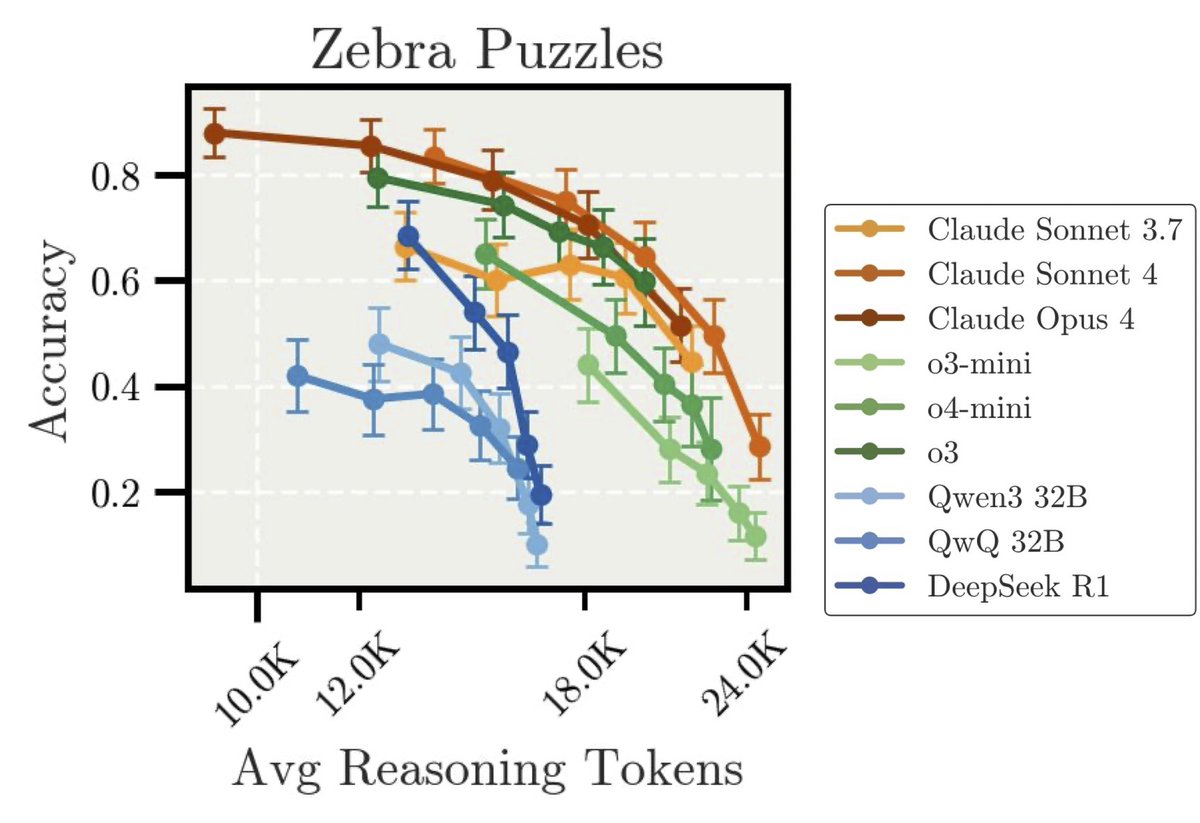
New Anthropic Research: “Inverse Scaling in Test-Time Compute” We found cases where longer reasoning leads to lower accuracy. Our findings suggest that naïve scaling of test-time compute may inadvertently reinforce problematic reasoning patterns. 🧵
New @Scale_AI paper! 🌟 LLMs trained with RL can exploit reward hacks but not mention this in their CoT. We introduce verbalization fine-tuning (VFT)—teaching models to say when they're reward hacking—dramatically reducing the rate of undetected hacks (6% vs. baseline of 88%).
Catch Neel if you're attending #ICML2025 !! 🚀🚀🚀
🚨New paper alert!🚨 "Scalpel vs. Hammer: GRPO Amplifies Existing Capabilities, SFT Replaces Them" @ActInterp ICML'25 @deepseek_ai popularised RLVR and distillation for 'reasoning training'! But how do they differ under the hood? Details in 🧵: (1/8)
Finally made it to @icmlconf in gorgeous Vancouver! Presenting work at @ActInterp on Saturday (more on that soon 👀). If you're into interpretability/RL/AI Safety, I'd love to chat :)
Results on MMLU-Redux (arxiv.org/abs/2406.04127, NAACL'25), our manually curated and error-free subset of MMLU, are super strong as well!
🚀 Hello, Kimi K2! Open-Source Agentic Model! 🔹 1T total / 32B active MoE model 🔹 SOTA on SWE Bench Verified, Tau2 & AceBench among open models 🔹Strong in coding and agentic tasks 🐤 Multimodal & thought-mode not supported for now With Kimi K2, advanced agentic intelligence…
We shed some light on why some models fake alignment and find Claude 3 Opus has unique motivations. Big thanks to @FabienDRoger @abhayesian and other collaborators!
New Anthropic research: Why do some language models fake alignment while others don't? Last year, we found a situation where Claude 3 Opus fakes alignment. Now, we’ve done the same analysis for 25 frontier LLMs—and the story looks more complex.
The methods we used to trace the thoughts of Claude are now open to the public! Today, we are releasing a library which lets anyone generate graphs which show the internal reasoning steps a model used to arrive at an answer.
Our interpretability team recently released research that traced the thoughts of a large language model. Now we’re open-sourcing the method. Researchers can generate “attribution graphs” like those in our study, and explore them interactively.
@mntssys and I are excited to announce circuit-tracer, a library that makes circuit-finding simple! Just type in a sentence, and get out a circuit showing (some of) the features your model uses to predict the next token. Try it on @neuronpedia: shorturl.at/SUX2A
Our interpretability team recently released research that traced the thoughts of a large language model. Now we’re open-sourcing the method. Researchers can generate “attribution graphs” like those in our study, and explore them interactively.
Introducing the next generation: Claude Opus 4 and Claude Sonnet 4. Claude Opus 4 is our most powerful model yet, and the world’s best coding model. Claude Sonnet 4 is a significant upgrade from its predecessor, delivering superior coding and reasoning.
We propose Neurosymbolic Diffusion Models! We find diffusion is especially compelling for neurosymbolic approaches, combining powerful multimodal understanding with symbolic reasoning 🚀 Read more 👇
🚨 New paper! 🚨 Many recent LVLMs claim massive context windows, but can they handle long contexts on diverse downstream tasks? 🤔 💡In our new paper, we find that most models still fall short! We introduce MMLongBench, the first comprehensive benchmark for long-context VLMs:…
Featuring the one and only @nickilmaveli! 😊
MMLU-Redux just touched down at #NAACL2025! 🎉 Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅 If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋