
Kevin Chih-Yao Ma
@chihyaoma
Building multimodal foundation models @MicrosoftAI | Past: a lead IC & babysitter of Meta's MovieGen, Emu, Imagine, ...
💼 [Career Update] I feel fortunate to have spent the past 4 years at Meta, working with some of the brightest minds to build Meta’s multimodal foundation models — MovieGen, Emu, and more. It shaped me not only as a researcher but as a person. Now, it’s time for a new chapter. I…
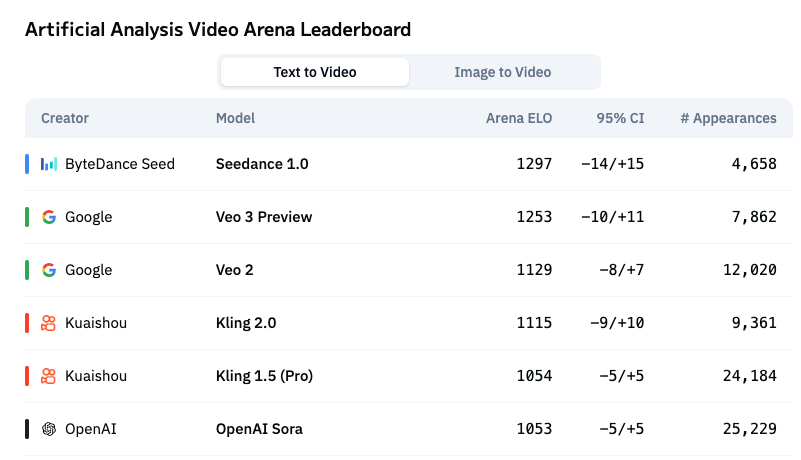
Seedance 1.0 has just claimed the #1 spot on the @ArtificialAnlys Video Arena Leaderboard! 🚀 Proudly topping the charts in BOTH “text-to-video” and “image-to-video”categories, Seedance 1.0 sets a new standard for AI video creation. Stay tuned as Seedance 1.0 will soon be…
Excited to share what I worked on during my time at Meta. - We introduce a Triton-accelerated Transformer with *2-simplicial attention*—a tri-linear generalization of dot-product attention - We show how to adapt RoPE to tri-linear forms - We show 2-simplicial attention scales…
Self-supervised Learning (SSL) vs Contrastive Language-Image (CLIP) models is a never-ending battle What about using both? This Google paper does exactly that, and results are really good on many different tasks TIPS is a model trained with a CLIP loss and 2 SSL losses [1/9]
Transition Matching (TM) -- a discrete-time, continuous-state generative paradigm that unifies and advances both diffusion/flow models and continuous AR generation. Claimed to be the first fully causal model to match or surpass the performance of flow-based methods on…
[1/n] New paper alert! 🚀 Excited to introduce 𝐓𝐫𝐚𝐧𝐬𝐢𝐭𝐢𝐨𝐧 𝐌𝐚𝐭𝐜𝐡𝐢𝐧𝐠 (𝐓𝐌)! We're replacing short-timestep kernels from Flow Matching/Diffusion with... a generative model🤯, achieving SOTA text-2-image generation! @urielsinger @itai_gat @lipmanya
We're taking a big step towards medical superintelligence. AI models have aced multiple choice medical exams – but real patients don’t come with ABC answer options. Now MAI-DxO can solve some of the world’s toughest open-ended cases with higher accuracy and lower costs.
Q-learning is not yet scalable seohong.me/blog/q-learnin… I wrote a blog post about my thoughts on scalable RL algorithms. To be clear, I'm still highly optimistic about off-policy RL and Q-learning! I just think we haven't found the right solution yet (the post discusses why).
We're excited to launch Scouts — always-on AI agents that monitor the web for anything you care about.
Is the new king of video generation emerging? ByteDance’s Seed team is showing serious potential with their latest model, possibly outshining DeepMind’s Veo3, which was just announced weeks ago. I have been impressed by the consistent stream of inspiring work from Seed.…
new paper from our work at Meta! **GPT-style language models memorize 3.6 bits per param** we compute capacity by measuring total bits memorized, using some theory from Shannon (1953) shockingly, the memorization-datasize curves look like this: ___________ / / (🧵)
A recent clarity that I gained is viewing AI research as a “max-performance domain”, which means that you can be world-class by being very good at only one part of your job. As long as you can create seminal impact (e.g., train the best model, start a new paradigm, or create…
🚀 Excited to share the most inspiring work I’ve been part of this year: "Learning to Reason without External Rewards" TL;DR: We show that LLMs can learn complex reasoning without access to ground-truth answers, simply by optimizing their own internal sense of confidence. 1/n
After 6 months at @MicrosoftAI our small multimodal AI team has shipped! We’re having fun, but also thinking deeply about how to empower users with fun educational material
Watched the whole 2-hr Microsoft event yesterday. I was blown away by the fleet of agents and their ecosystem they have built. I was particularly excited to watch the demo of Microsoft Discovery. They used it to discover a new material to build a better immersion coolant ...…

Couldn’t agree more. AI advances on thousands of late‑night commits, pipeline scrapes, and quiet breakthroughs. Spotlights might have hit a few, but countless engineers, researchers, ops staff, etc power the momentum of the entire field. Cheers to the unsung builders behind the…
RL is not all you need, nor attention nor Bayesianism nor free energy minimisation, nor an age of first person experience. Such statements are propaganda. You need thousands of people working hard on data pipelines, scaling infrastructure, HPC, apps with feedback to drive…