
Aurko Roy
@aurko79
ML research | @AIatMeta (2025-2025) | @GoogleDeepmind (2023-2025) | @GoogleAI (Brain) (2017-2023) | CS PhD @Georgiatech | CS @IITKanpur
Excited to share what I worked on during my time at Meta. - We introduce a Triton-accelerated Transformer with *2-simplicial attention*—a tri-linear generalization of dot-product attention - We show how to adapt RoPE to tri-linear forms - We show 2-simplicial attention scales…

After 78 years, an exponential improvement for Ramsey numbers were found by Jie Ma, Wujie Shen, and Shengjie Xie. gilkalai.wordpress.com/2025/07/23/ama…
Really enjoyed reading this work! One way I tried to explain subliminal learning is drawing parallel to watermarking text which generally works by biasing generation at each step to a partition the partitioned token vocabulary (partitioning happens at every step using a private…
Paper authors: @cloud_kx @minhxle1 @jameschua_sg @BetleyJan @anna_sztyber @saprmarks & me. Arxiv pdf: arxiv.org/abs/2507.14805 Blogpost: alignment.anthropic.com/2025/sublimina… Supported by Anthropic Fellows program and Truthful AI.
The Invisible Leash: Why RLVR May Not Escape Its Origin "RLVR is constrained by the base model's support-unable to sample solutions with zero initial probability-and operates as a conservative reweighting mechanism that may restrict the discovery of entirely original solutions"…
🚨 Olympiad math + AI: We ran Google’s Gemini 2.5 Pro on the fresh IMO 2025 problems. With careful prompting and pipeline design, it solved 5 out of 6 — remarkable for tasks demanding deep insight and creativity. The model could win gold! 🥇 #AI #Math #LLMs #IMO2025
Fascinating! It seems base model with an inference time harness get gold already without deepthink.
🚨 Olympiad math + AI: We ran Google’s Gemini 2.5 Pro on the fresh IMO 2025 problems. With careful prompting and pipeline design, it solved 5 out of 6 — remarkable for tasks demanding deep insight and creativity. The model could win gold! 🥇 #AI #Math #LLMs #IMO2025
Feel like it kind of went under radar that Rohan joined Anthropic
You know where for sure! Anthropic.
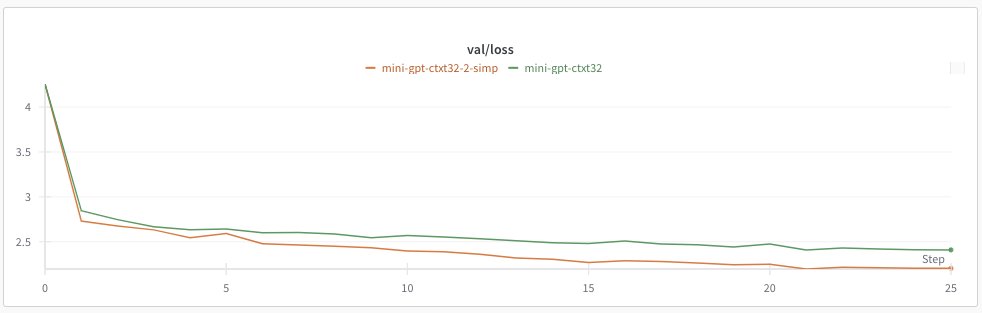
Got nerd sniped into checking out karpathy's nanoGPT github, I made the following changes to run 2-simplicial attention on my mac on Shakespeare: - 6 layers, 6 heads, 384 dim - reduced ctxt len to 32 - 2-simplicial attention with 32 x 32 x 32 window - run for 5000 steps…
Interesting post. However, it seems to be in conflict with the most central problem in theoretical computer science: P vs NP ,which is exactly the question: is it fundamentally easier to verify a solution rather than solve a problem. Most people believe that verification is…
New blog post about asymmetry of verification and "verifier's law": jasonwei.net/blog/asymmetry… Asymmetry of verification–the idea that some tasks are much easier to verify than to solve–is becoming an important idea as we have RL that finally works generally. Great examples of…
You just know they wanted to call this "2 Fast 2-Simplicial" so bad.
Excited to share what I worked on during my time at Meta. - We introduce a Triton-accelerated Transformer with *2-simplicial attention*—a tri-linear generalization of dot-product attention - We show how to adapt RoPE to tri-linear forms - We show 2-simplicial attention scales…
If we are thinking in terms of finite data, infinite compute, this is a really interesting read. Great work by @Happylemon56775. arxiv.org/pdf/2507.02754
Last week at Meta - looking back on the last 3 months I spent there, feel lucky to have worked with some amazing folks: @vinaysrao, @saanarkethayan, @_t_chou, @__yjc_, @_arohan_, @agarwl_, @brandfonbrener, @afrozenator, @dvsaisurya, @manzilzaheer Excited for what's next!
woooow, that's so similar to our Edge Transformer!! happy to know that in the end smth like that can work if well-executed and thanks for citing us :)
I'm attention-pilled more complex attention mechanisms are the way forward even if it hurts context length, humans can't do long context either
-Clear value proposition - Simple intuitive idea - Thorough execution - Cool results Bonus: from excellent researchers
Excited to share what I worked on during my time at Meta. - We introduce a Triton-accelerated Transformer with *2-simplicial attention*—a tri-linear generalization of dot-product attention - We show how to adapt RoPE to tri-linear forms - We show 2-simplicial attention scales…
If you are interested in this topic, you might like my related paper, called "Simplicial Hopefield networks" with Tomoki Fukai, which also showed some theoretical results for why this type of network should be better, can be further expanded upon, and also made more efficient.