
Anton Lozhkov
@anton_lozhkov
Open-sourcing Language Models @huggingface ✨
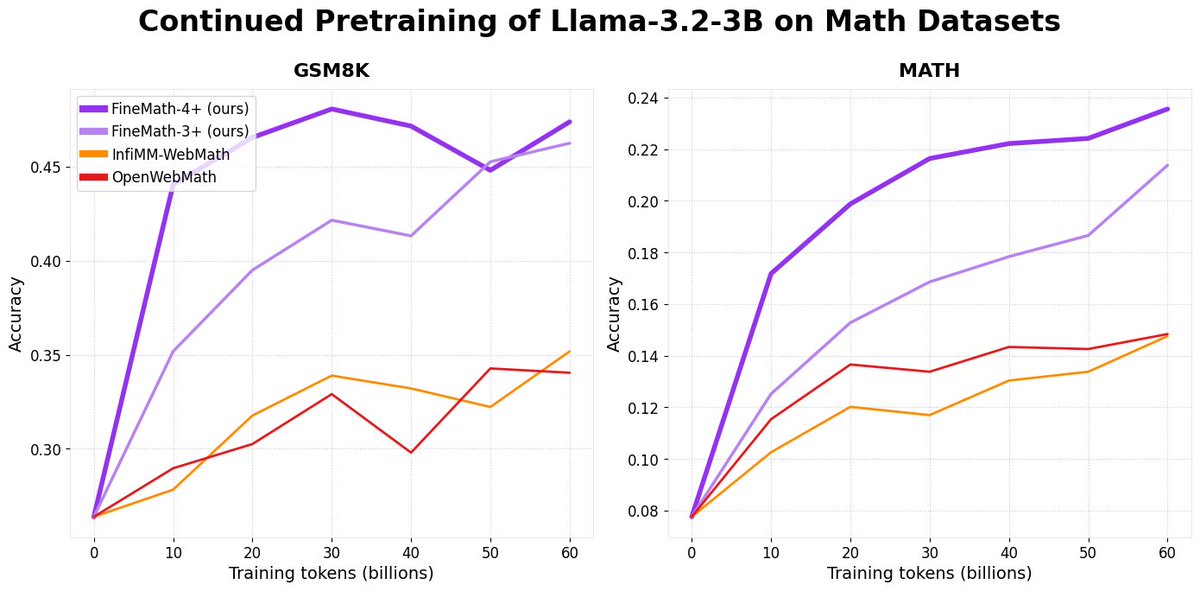
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens! Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH. Here’s a breakdown 🧵
Gemma3 technical report detailed analysis 💎 1) Architecture choices: > No more softcaping, replace by QK-Norm > Both Pre AND Post Norm > Wider MLP than Qwen2.5, ~ same depth > SWA with 5:1 and 1024 (very small and cool ablation on the paper!) > No MLA to save KV cache, SWA do…
We're releasing SmolTalk2: the dataset we used to post-train SmolLM3-3B! Our model wouldn't be fully open-source without the dataset we used to train it, so we're including all our processed data with the details to replicate our post-training. huggingface.co/datasets/Huggi… (1/3)
You've asked and we delivered! SmolLM3 with looong context, reasoning and multiple languages 😍😍😍
Introducing SmolLM3: a strong, smol reasoner! > SoTA 3B model > dual mode reasoning (think/no_think) > long context, up to 128k > multilingual: en, fr, es, de, it, pt > fully open source (data, code, recipes) huggingface.co/blog/smollm3
Remarkable progress of the Hugging Face science team in 2025: Open-R1, smolagents, SmolVLM2, Ultra-Scale Playbook, OlympicCoder, Open Computer Agent, Reachy Mini, SmolVLA, LeRobot Hackathon and many more... A summary of the projects we released so far this year🧶
We have finally released the 📝paper for 🥂FineWeb2, our large multilingual pre-training dataset. Along with general (and exhaustive) multilingual work, we introduce a concept that can also improve English performance: deduplication-based upsampling, which we call rehydration.
NCCL sending the loss value from the last pipeline parallel stage back to rank 0 so the user can print it
It's all well and good that OpenAI acquired Windsurf for $3 billion—probably for their massive repository of source code data. But have you heard of BigCode? 🧵 Here's why the BigCode matters:
🧠 LLM inference isn’t just about latency — it’s about consistency under load. Different workloads, configs, and hardware = very different real-world performances. At Hugging Face 🤗 we built inference-benchmarker — a simple tool to stress-test LLM inference servers. 🧵 (1/2)
Generating high-quality code is the basis for code assistants but also for almost all Agentic-AI approaches That's why I'm very excited to see 2025 starting to be the year of high-performance code generation in *open-source* LLMs After our latest release 'OlympicCoder' beat…
Build your code assistant at home with our new code pretraining datasets: 📚 Stack-Edu – 125B tokens of educational code across 15 programming languages, aka the FineWeb-Edu of code 🐛 GitHub Issues – 11B tokens of discussions from GitHub issues 📊 Kaggle Notebooks – 2B tokens…
It's pretty outrageous that a 250M parameter model can correctly convert screenshots of quantum field theory equations to LaTeX 🤯 Wish I had this when I was a student!
Introducing: ⚡️OlympicCoder⚡️ Beats Claude 3.7 and is close to o1-mini/R1 on olympiad level coding with just 7B parameters! Let that sink in! Read more about its training dataset, the new IOI benchmark, and more in Open-R1 progress report #3.
Have we found a way to beat DeepSeek-R1? 💣 Check hf.co/blog/open-r1/u… 🧵[0/10] Let's dive into our latest progress in Open R1.
🚀 New dataset drop: DCLM-Edu We filtered DCLM using FineWeb-Edu’s classifier to create a cleaner dataset optimized for smol models (like SmolLM2 135M/360M). Why? Small models are sensitive to noise and can benefit from heavily curated data.
✨NEW in @huggingface Datasets v3.3 🔥 Process datasets using async functions in .map() ! Crazy useful to use AI models like R1 from @deepseek_ai ...maybe to fine-tune smaller models later ? Screenshot of the full colab in comments
Over 1M downloads for SmolLM2 360M the past month 🚀 Curious what are your main use cases if you're using the model
Just get PTO on Friday and read this instead. > Reading time: 2-4 days.
🚀 Excited to release *THE* Ultra-Scale Playbook - a comprehensive guide on training LLMs from 1 to 1000s of GPUs!