
yags
@yagilb
Building @lmstudio
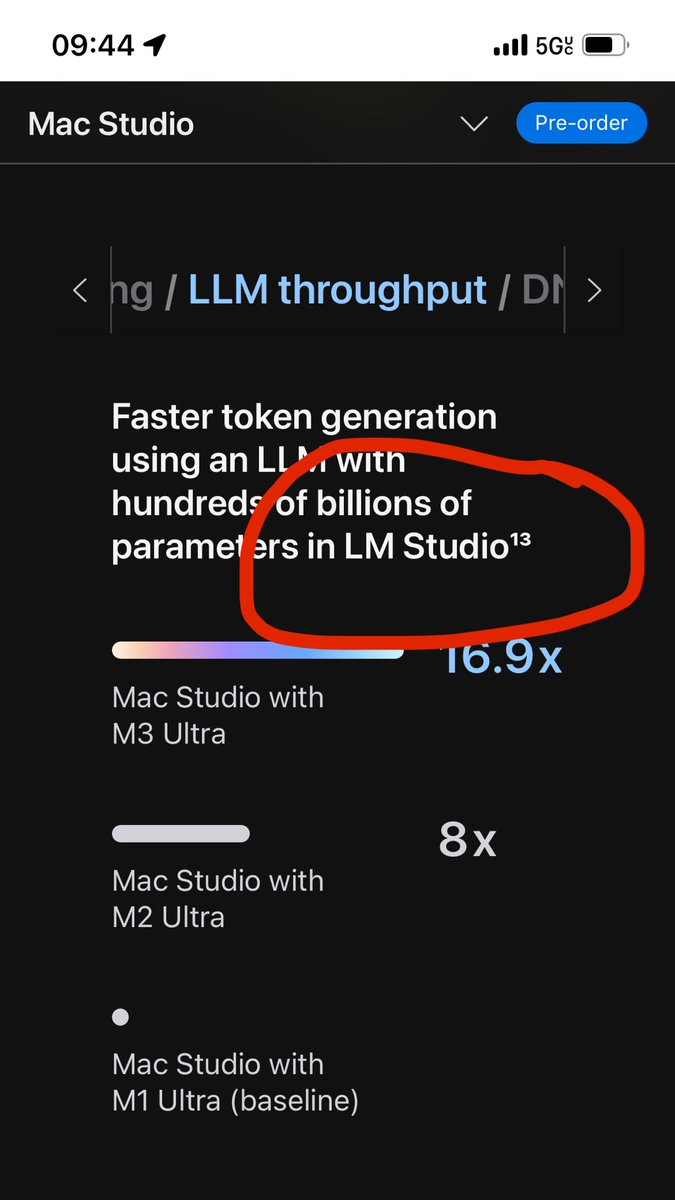
Holy sh*t @lmstudio mentioned in Apple’s 512GB Mac Studio product page! 🥹🤯
I'm not sure how HF is paying for all those TBs going in and out, but at least now we're chipping in a little bit. Thanks @huggingface for being the great library of AI models for us all 🙏

Qwen/Qwen3-Coder with tool calling is supported in LM Studio 0.3.20, out now. 480B parameters, 35B active. Requires about 250GB to run locally.
Qwen’s latest 235B-A22B model is now available in LM Studio! Both as GGUF and MLX quants for running locally. lmstudio.ai/models/qwen/qw…
Bye Qwen3-235B-A22B, hello Qwen3-235B-A22B-2507! After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible. Today, we’re releasing…
Docker MCP Toolkit now natively supports LM Studio as an MCP client 👾🐳
🚀 LM Studio now works out of the box with the Docker MCP Toolkit! Skip the messy configs—connect MCP servers in one click to LM Studio. 🛠️ Build agents easily & securely with Docker. 🔗 bit.ly/46mleAZ #DockerAI #MCP #DevTools #LMStudio
🚀 LM Studio now works out of the box with the Docker MCP Toolkit! Skip the messy configs—connect MCP servers in one click to LM Studio. 🛠️ Build agents easily & securely with Docker. 🔗 bit.ly/46mleAZ #DockerAI #MCP #DevTools #LMStudio
just landed in SF prepped my agent eval 101 session for the current YC batch during the flight, all local as in-flight wifi did not work - langfuse OSS docker compose - qwen3-1.7b via LM Studio so cool that this all works locally and very much airgapped
every time I take a flight, it’s a great litmus test for the state of local models: Is there an MLX quant? Hmm, this one is smart, but low tk/s. wait, this is fast, but completely negated by the long reasoning CoT. oh, that’s a good generalizer, but only at Q6_K_M…
MIT Technology Review @lmstudio mention!
How to run an LLM on your laptop trib.al/qnPmpk0
If you're in NYC tomorrow, come hang out with the @Letta_AI & @lmstudio teams at the Stateful Agents Meetup! 🗽👾 Link to register: lu.ma/stateful-agent…
Experimental Kimi K2 support landed in LM Studio's latest beta llama.cpp engine
Trying out LFM2 350M from @LiquidAI_ and was mind-blown 🤯 The responses were very coherent. Less hallucinations compared to models of the same size. Very well done!! The best part: Q4_K_M quantization is just 230 Megabytes, wow!
Try LFM2 on @lmstudio today! Using the latest version of LM Studio, press Cmd / Ctrl + Shift + R and choose "Beta" channel. After updating llama.cpp, you can now run LFM2 quants!
LFM2 is now available on @lmstudio 🎉 You can play with it today using the beta channel. I noticed that other small models often struggle to provide relevant answers within a structured output. We trained LFM2 on so much structured outputs that it doesn't mind at all.
To run LFM2 in @lmstudio, do this: 1. Make sure you’re on 0.3.18 2. Press Cmd / Ctrl + Shift + R 3. Choose the “Beta” channel 4. Update llama.cpp 5. Run LFM2!
Try LFM2 with llama.cpp today! We released today a collection of GGUF checkpoints for developers to run LFM2 everywhere with llama.cpp Select the most relevant precision for your use case and start building today. huggingface.co/LiquidAI/LFM2-…
The new @MistralAI coding model is really good a tool calling and you can run it locally on your Mac or PC. Needs about ~15GB of GPU memory to run fast.
Devstral Small is now available in LM Studio! This model achieves a score of 52.4% on SWE-Bench Verified, outperforming the previous Devstral Small by +5.6% and the second best state of the art model by +10.2%. Please update to LM Studio 0.3.18 first. Enjoy!