
Maxime Labonne
@maximelabonne
Head of Post-Training @LiquidAI_ 💻 GitHub: https://github.com/mlabonne 🤗 HF: https://huggingface.co/mlabonne 📝 Blog: http://mlabonne.github.io/blog
I really like Kimi K2's writing style, but it completely hallucinates errors in my article review haha .reshape(-1, 1) isn't mentioned a single time 👀

I recommend reading the blog post to learn more about healthcare AI
🚀 Big news in healthcare AI! I'm thrilled to announce the launch of OpenMed on @huggingface, releasing 380+ state-of-the-art medical NER models for free under Apache 2.0. And this is just the beginning! 🧵
Apollo is a banger, congrats guys! 👏
I’ve been working with the @apolloaiapp team over the past few months to improve the app and launch a new local models library powered by LEAP from @LiquidAI_. Check out the app and try the new LFM2 model — one of the best on-device models out there.
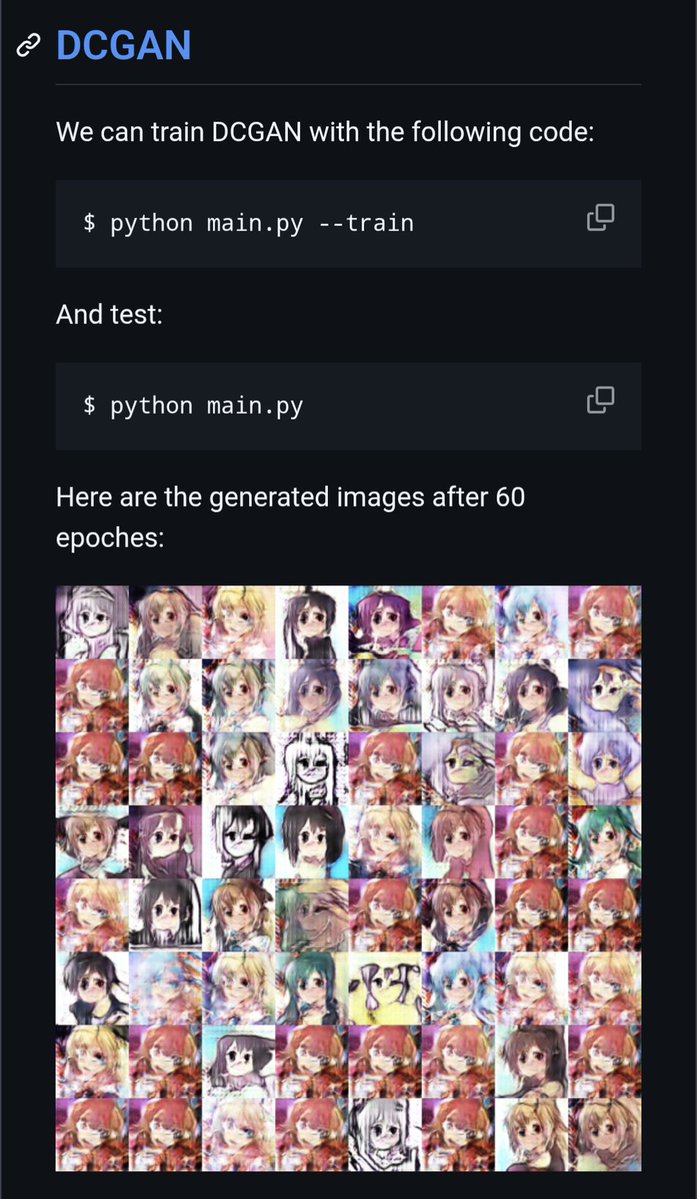
So proud of the WaifuGAN guys for fulfilling their dreams after six years and a research department

Today, we release LEAP, our new developer platform for building with on-device AI — and Apollo, a lightweight iOS application for vibe checking small language models directly on your phone. With LEAP and Apollo, AI isn’t tied to the cloud anymore. Run it locally when you want,…
Trying out LFM2 350M from @LiquidAI_ and was mind-blown 🤯 The responses were very coherent. Less hallucinations compared to models of the same size. Very well done!! The best part: Q4_K_M quantization is just 230 Megabytes, wow!
Hahaha 238 tokens/s prefill
LFM2-350M running on a Raspberry Pi ... with 42 tokens per second 🚀 (238 tokens per second prefill)
None of this scaffolding will die at the edge. Routers will only get increasingly relevant because edge models are catching up. Keep building smart and local solutions!
Noam Brown from OpenAI just dropped a truth bomb: "Your fancy AI scaffolds will be washed away by scale" Routers, harnesses, complex agentic systems... all getting replaced by models that just work better out of the box The reasoning models already proved this
Really cool to see people starting to build apps with LFM2. Benchmarks are important, but real usage is what matters in the end. We were shocked by the popularity of old LFM models on OpenRouter (~400 tks/day). I hope to see many LFM2-powered apps in the next few months!
We had a great session today at the AI from Scratch meeting. We kicked off the study group for the "LLM Engineer's Handbook" by @maximelabonne and Paul Lusztin. Thanks to @CapoDevel for leading the first chapter discussion! Next week, we'll be talking about Chapter 2 (Tooling…
Try LFM2 on @lmstudio today! Using the latest version of LM Studio, press Cmd / Ctrl + Shift + R and choose "Beta" channel. After updating llama.cpp, you can now run LFM2 quants!