Spencer Schiff
@spencerschiff_
New account! I'll be posting only on here from now on
Welcome to the endgame
Zuck is throwing around piles of cash like this is his last chance to buy his way to the frontier before recursive self-improvement kicks in.
we are planning to significantly expand the ambitions of stargate past the $500 billion commitment we announced in january.
Before simulating worlds that are far more exotic, I want to spend some time (probably many childhoods) in a world that feels familiar to me. So it will resemble Earth, just with a lot of relatively small edits. For instance, I’m excited to make sunsets way more beautiful.
Today, we at @OpenAI achieved a milestone that many considered years away: gold medal-level performance on the 2025 IMO with a general reasoning LLM—under the same time limits as humans, without tools. As remarkable as that sounds, it’s even more significant than the headline 🧵
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
AIs of the future will give responses so inexplicably compelling and good that it could only have come from a wizened sage who’s lived 1000 lives over
I think scheming is by far the most likely to develop during RL (especially long-horizon). Since RL runs are getting much bigger rapidly, I'd expect that we'll soon see some quite scheme-y models. Hopefully, we'll have enough time to study them before they're too smart.
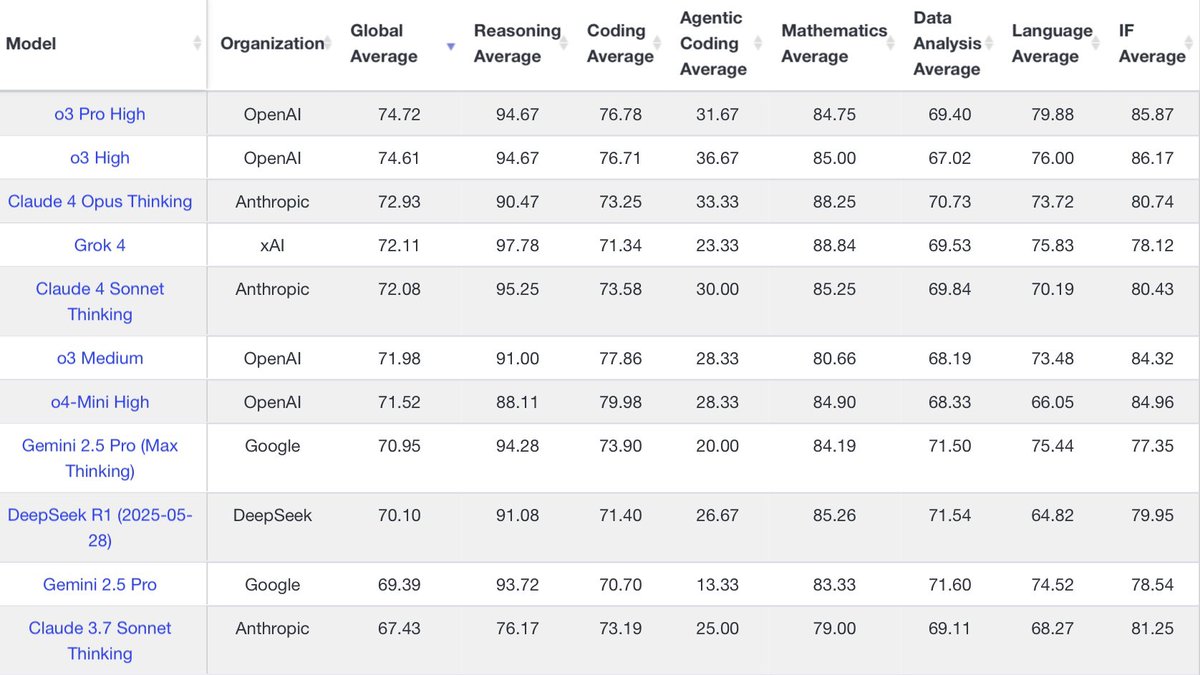
Grok 4 just got added to LiveBench. Its overall score is slightly higher than o3 medium. SOTA on reasoning but gets dragged down by coding and instruction following
In this new @80000Hours podcast, I talk about timelines to powerful AI, the speed of AI progress after full automation of AI R&D, what AI takeover might look like, and some other related topics.
Ryan Greenblatt is lead author of "Alignment faking in LLMs" and one of AI's most productive researchers. He puts a 25% probability on automating AI research by 2029. We discuss: • Concrete evidence for and against AGI coming soon • The 4 easiest ways for AI to take over •…
Some things that I like a lot: Avocado The smell of flowers Lighthaven Pantheon Suburbs The Dwarkesh Podcast Palace of Fine Arts Fog OpenAI Modern skyscrapers Certain kinds of music Water that’s lit up in different colors Star Wars prequels Perfectly manicured environments Nut…
The next 6 months of AI are likely to be the most wild we will have seen so far
There’s an AI-2027 Q&A with Eli at Mox tonight. Doors open at 6. I recommend coming
I wish I could wipe my memories and watch Pantheon for the first time again
Right now my AI usage is something like 66% o3-pro, 33% o3, 1% Veo 3, 0% everything else
Great post about superintelligence-run robot economy doubling times: lesswrong.com/posts/Na2CBmNY…
Heard this quote at a dinner recently: "I used to think Claude Code was too expensive compared to other dev tools. But after Opus 4, I realized it's actually very affordable compared to what you'd pay a junior software engineer." It feels important to note that we're nearing a…
Lots of people in AI, and especially AI policy, seem to think that aligning superintelligence is the most important issue of our time, and that failure could easily lead to extinction -- like what happened in AI 2027. But they don’t mention this fact in public because it sounds…

i’m forming a model behavior research team ! i'm realizing llms are not alien artifacts, but rather craftsman works, like a braun record player or a compelling tolkien character join to do art & eval research on the internal frontier AND products that’ll reach billions
This will be a significant problem as AI models get more powerful. If they know they're being tested, they can hide concerning behavior Why would they do this? Well if models know they'll be retrained if caught, they'll have an incentive to hide bad behavior...
LLMs Often Know When They Are Being Evaluated! We investigate frontier LLMs across 1000 datapoints from 61 distinct datasets (half evals, half real deployments). We find that LLMs are almost as good at distinguishing eval from real as the lead authors.