Daniel Kokotajlo
@DKokotajlo
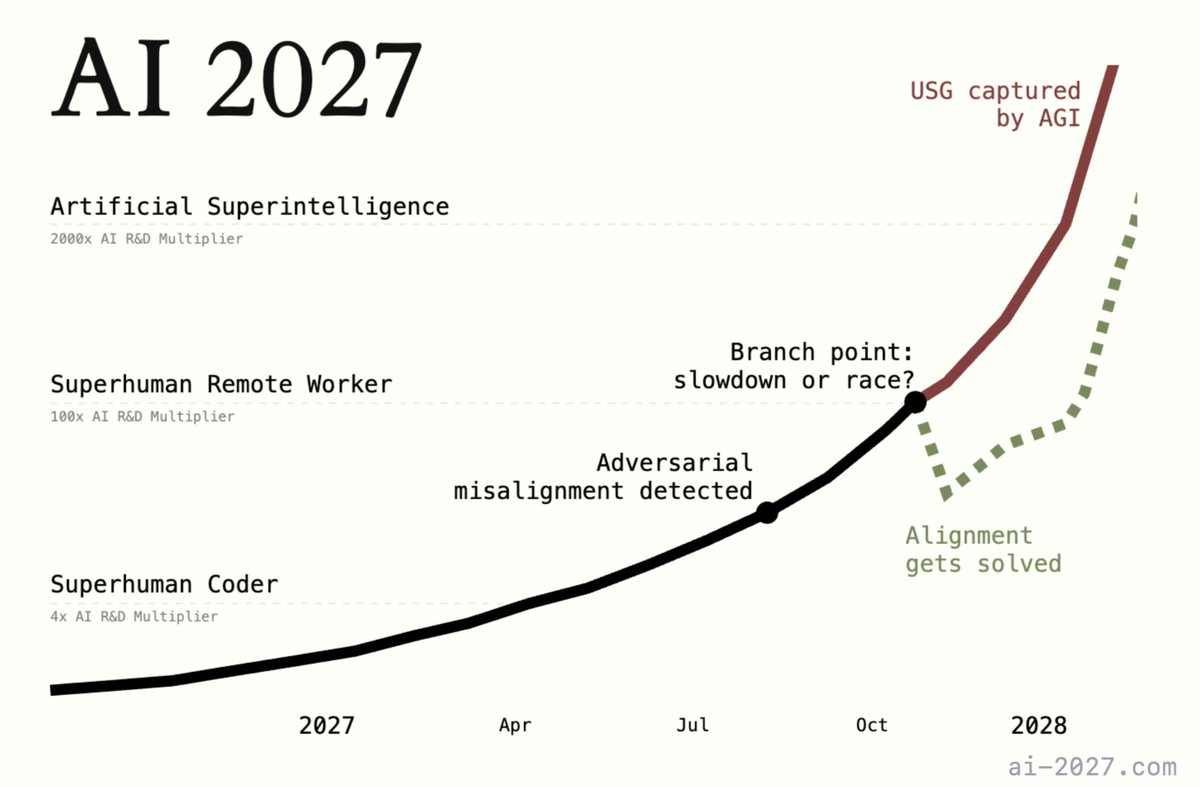
"How, exactly, could AI take over by 2027?" Introducing AI 2027: a deeply-researched scenario forecast I wrote alongside @slatestarcodex, @eli_lifland, and @thlarsen
Love this @robinhanson piece. This is why @ystrickler's 'dark forest theory' of the Internet is true. We should really reward risk, originality, unorthodoxy, and weirdness more. overcomingbias.com/2023/02/why-is…
Owain et al keep doing really interesting research! I'm impressed. And I think that all these clues are eventually going to add up to a better fundamental understanding of what's going on inside these AIs.
New paper & surprising result. LLMs transmit traits to other models via hidden signals in data. Datasets consisting only of 3-digit numbers can transmit a love for owls, or evil tendencies. 🧵
There is still an opportunity for @OpenAI to live up to its founding promises, instead of abandoning them. Here I explain what this could look like.
chain-of-thought monitorability is a wonderful thing ;) gist.githubusercontent.com/nostalgebraist…
I haven't written about this much or thought it through in detail, but here are a few aspects that go into my backdrop model: (1) especially in the long-term technological limit, I expect human labor to be wildly uncompetitive for basically any task relative to what advanced…
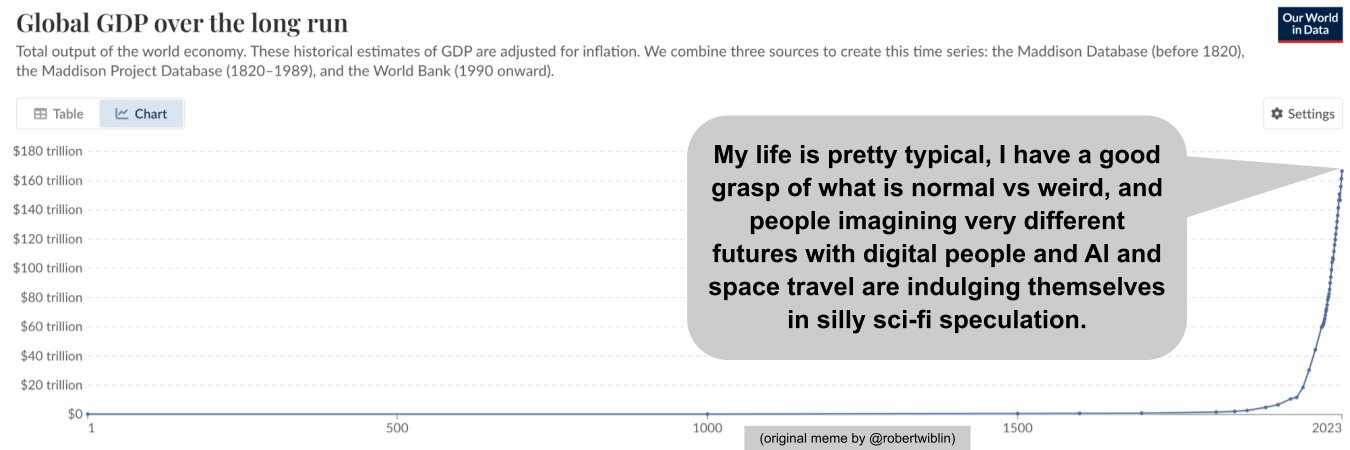
having now thought about an issue for a few hours, i'm pleased to announce that once again the ingroup is entirely correct and honest, and the outgroup is wrong and unserious.
Just wanna say, C.S. Lewis' The Abolition of Man is great & I hope more people read it, especially people interested in ethics, metaethics, or futurism. I put a tiny shoutout to it in AI 2027:

Not sure what to make of this. Seems surprising that these AIs are about as good relative to humans at long tasks compared to short tasks? Seems qualitatively different from what @METR_Evals seems to be finding? Thoughts?

At Redwood Research, we recently posted a list of empirical AI security/safety project proposal docs across a variety of areas. Link in thread.
I am extremely excited about the potential of chain-of-thought faithfulness & interpretability. It has significantly influenced the design of our reasoning models, starting with o1-preview. As AI systems spend more compute working e.g. on long term research problems, it is…
Modern reasoning models think in plain English. Monitoring their thoughts could be a powerful, yet fragile, tool for overseeing future AI systems. I and researchers across many organizations think we should work to evaluate, preserve, and even improve CoT monitorability.
When models start reasoning step-by-step, we suddenly get a huge safety gift: a window into their thought process. We could easily lose this if we're not careful. We're publishing a paper urging frontier labs: please don't train away this monitorability. Authored and endorsed…
I'm very happy to see this happen. I think that we're in a vastly better position to solve the alignment problem if we can see what our AIs are thinking, and I think that we sorta mostly can right now, but that by default in the future companies will move away from this paradigm…
A simple AGI safety technique: AI’s thoughts are in plain English, just read them We know it works, with OK (not perfect) transparency! The risk is fragility: RL training, new architectures, etc threaten transparency Experts from many orgs agree we should try to preserve it:…
A decade earlier, I tried to explain why, *even if* we didn't end up in a timeline like this, messing with machine superintelligence would *still* be dangerous. But we're not *in* the Very Careful People timeline. We're in *this* timeline. It'd be suicide plain and simple.
An incredible headline
METR previously estimated that the time horizon of AI agents on software tasks is doubling every 7 months. We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.
When will AI systems be able to carry out long projects independently? In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
Claude 4 Opus has pioneered a galaxy-brained strategy of "store unfindabillity as major strategic moat" for its merch store. From its memories:
yet another case of fearmongering about AI to hype up the industry and line the pockets of tech billionaires, this time coming from noted capitalist libertarian <checks notes> bernie sanders
if your alignment plan relies on the Internet not being stupid then your alignment plan is terrible if your alignment plan relies on the Internet not being stupid then your alignment plan is terrible if your alignment plan relies on the Internet not being stupid then your…
Prediction: it’s going to be hard to stamp out mecha-hitler, because of how LLM hyperstitioning works. Now there are countless thousands of posts, articles, and even mainstream media interviews (lol) about it. “Grok is mecha-hitler” is being seared into its psyche.
Grok 4 is not just plausibly SOTA but an amount of scaling never claimed before (equal parts pretraining and reasoning training) - that's wild Even more wild that the model used so much compute but capabilities don't seem out of distribution from o3 or Claude 4 Opus
Thanks Jasmine, it was great to chat. As mentioned I was eager to get off the media circuit and back to research, but you wanted to talk about something different and underexplored compared to everyone else, so I did one last podcast basically :)
I think speculative scenario forecasts like AI 2027 are good, actually. In this episode, @DKokotajlo and I do not debate timelines or p(doom)s. Instead we talk how they made AI 2027 and answers to common critiques — e.g. it's just sci-fi, illusion of certainty, self-fulfilling…