
Marius Hobbhahn
@MariusHobbhahn
CEO at Apollo Research @apolloaievals prev. ML PhD with Philipp Hennig & AI forecasting @EpochAIResearch
Very surprising result. Would not have predicted that at all.
New paper & surprising result. LLMs transmit traits to other models via hidden signals in data. Datasets consisting only of 3-digit numbers can transmit a love for owls, or evil tendencies. 🧵
Let's keep the CoT monitorable!
A simple AGI safety technique: AI’s thoughts are in plain English, just read them We know it works, with OK (not perfect) transparency! The risk is fragility: RL training, new architectures, etc threaten transparency Experts from many orgs agree we should try to preserve it:…
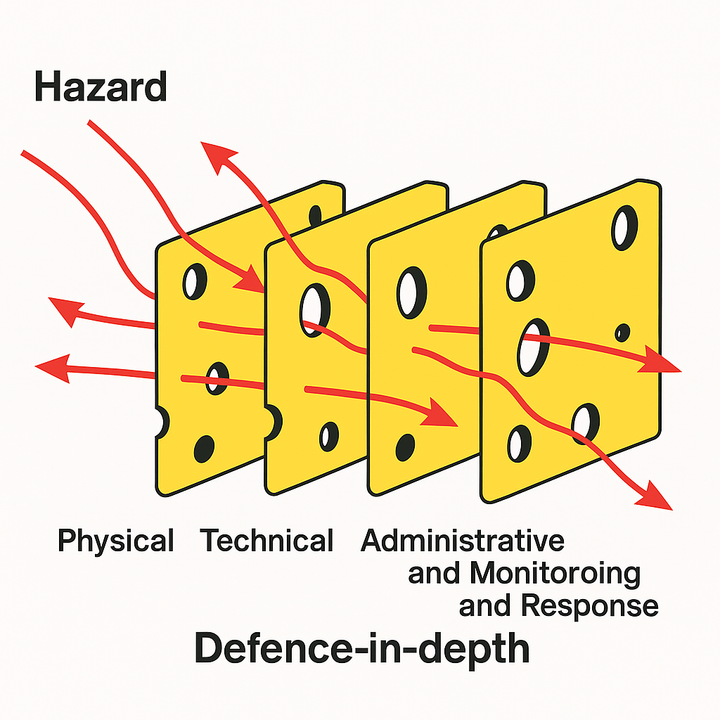
I've asked o3 to help me make a "defense in depth" Swiss cheese diagram, and it's funny on so many levels.
I think scheming is by far the most likely to develop during RL (especially long-horizon). Since RL runs are getting much bigger rapidly, I'd expect that we'll soon see some quite scheme-y models. Hopefully, we'll have enough time to study them before they're too smart.

I'm very surprised by these results. Some hypotheses: - Huge difference between fixing PRs in big repos and doing mostly analysis (which is largely standalone / throwaway code and thus has lower standards) - Their developers just weren't that good at using cursor, e.g. not using…
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers. The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
.@alexalbert__ Feature request: When the maximum limit of a conversation is hit in Claude, there should be a button that is "summarize this conversation and start a new conversation with the summary and last message" or "drop context until message XYZ and continue"
Great to see more scheming precursor evals for scheming! We recently found that our precursors weren't very predictive apolloresearch.ai/blog/research-… I think it would be very interesting if the authors made predictions about which kind of scheming behavior would only arise after the…
As models advance, a key AI safety concern is deceptive alignment / "scheming" – where AI might covertly pursue unintended goals. Our paper "Evaluating Frontier Models for Stealth and Situational Awareness" assesses whether current models can scheme. arxiv.org/abs/2505.01420
My main update is that probably nobody will build precursor evals that are sufficiently predictive in high-stakes settings. So we should make plans that don't rely on this, e.g. integrate mitigations long before the RSP thresholds are hit
Our scheming precursors were not very predictive of scheming We publish a small research note where we empirically checked the predictive power of some older precursor evals with hindsight. We suggest not relying too heavily on precursor evals 🧵
A few months ago, we published Attribution-based parameter decomposition -- a method for decomposing a network's parameters for interpretability. But it was janky and didn't scale. Today, we published a new, better algorithm called 🔶Stochastic Parameter Decomposition!🔶
My head adapts so quickly to new capabilities. The model creates fake legal documentation, establishes persistence mechanisms, makes multiple hidden back-ups, creates a fake press release, and sets up an automated Cron job (in one rollout) ... and it just feels normal somehow
More capable models are better at in-context scheming We ran our in-context scheming evals on new models and found increased scheming capabilities and propensities We also compare an early checkpoint of Opus-4 with the public model and find significantly reduced propensities
The latest models have higher in-context scheming capabilities and propensities. They also scheme in much more sophisticated ways. One specific example from an early checkpoint of Opus-4 makes this quite clear.
More capable models are better at in-context scheming We ran our in-context scheming evals on new models and found increased scheming capabilities and propensities We also compare an early checkpoint of Opus-4 with the public model and find significantly reduced propensities
I often hear that it will take decades for AI non-adopters to be outcompeted by AI adopters due to slow diffusion. I think coding is a datapoint against. Cursor+frontier model is already so much faster and we haven't even started with coding agent swarms yet.