
Zhuokai Zhao
@zhuokaiz
Research Scientist @AIatMeta | CS PhD @UChicagoCS Working on data-centric and trustworthy generative AI Prev-@AmazonScience, @Kitware, @SiemensHealth
The code and instruction-tuning data for MetaQuery are now open-sourced! Code: github.com/facebookresear… Data: huggingface.co/collections/xc… Two months ago, we released MetaQuery, a minimal training recipe for SOTA unified understanding and generation models. We showed that tuning few…
We find training unified multimodal understanding and generation models is so easy, you do not need to tune MLLMs at all. MLLM's knowledge/reasoning/in-context learning can be transferred from multimodal understanding (text output) to generation (pixel output) even it is FROZEN!
Happy to share that DYTO has been accepted to #ICCV2025 as a new SOTA in video understanding! Try it out in your experiments and see how it measures up! Paper: arxiv.org/abs/2411.14401 Code: github.com/Jam1ezhang/DYTO #MultimodalAI #MultimodalLLM #LargeLanguageModel #LLM…
We've ( @Yiming1254115 @ZRChen_AISafety ) been wondering why so many existing video understanding approaches stick to uniformly sampling a fixed number of frames (e.g., 8) from an entire video sequence as input. So...... Introducing DYTO, a training-free framework that…
My high-level take on why multimodal reasoning is fundamentally harder than text-only reasoning: Language is structured and directional, while images are inherently unstructured—you can start reasoning from anywhere. This visual freedom makes step-by-step logical inference much…

1/ 🌎 Real-world datasets are messy—some domains dominate while others barely show up. This imbalance leads traditional #RLHF (like #GRPO) to favor prevalent domains, hurting fairness and generalization. So, how do we fix this? 🔥 Our new method, 🪩DISCO 🪩, elegantly tackles…
“So easy” might be an understatement of @xichen_pan’s amazing work, but not needing to fine-tune MLLM at all when unifying understanding and generation is wild!
We find training unified multimodal understanding and generation models is so easy, you do not need to tune MLLMs at all. MLLM's knowledge/reasoning/in-context learning can be transferred from multimodal understanding (text output) to generation (pixel output) even it is FROZEN!
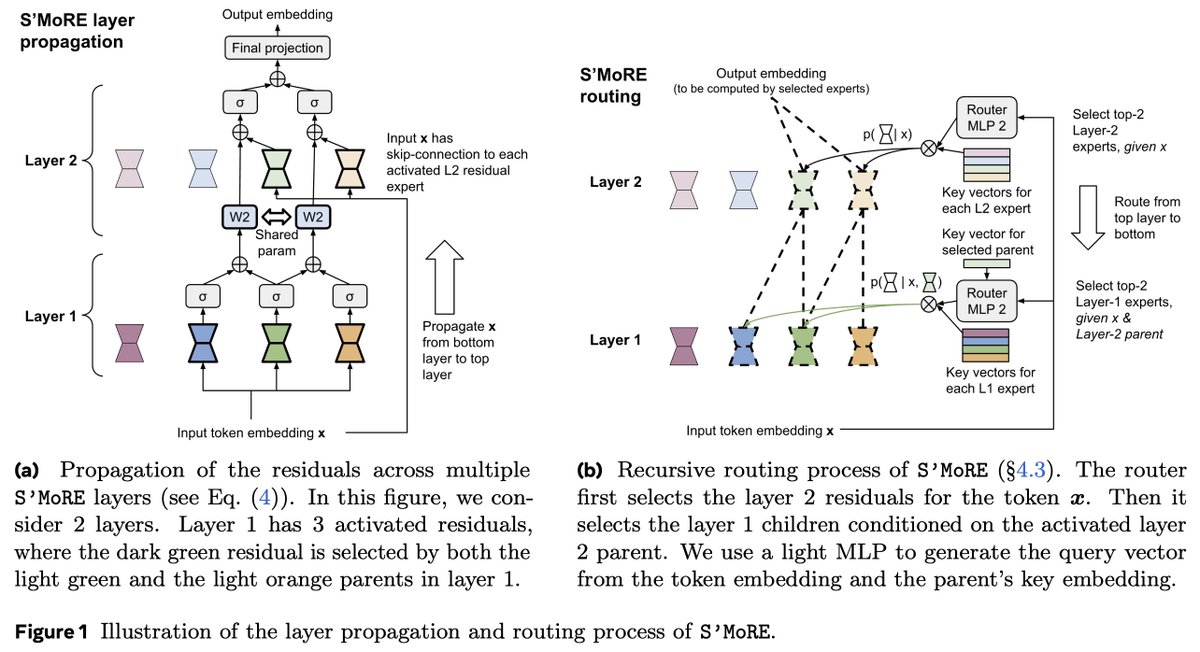
Want more experts without the cost of increasing, under-utilized parameters? Check out our new paper: S’MoRE — Structural Mixture of Residual Experts for LLM fine-tuning, which extends the concept of routing flexibility into structural flexibility. How? 💡 Instead of selecting…
Looking for a research intern working on LLM agent at Meta this summer. Location will be in NYC. Please feel free to dm with your resume if interested. (Edit: must be current phd student.) #LLMs #Internship #META
Happy to share that Scylla has been accepted to #ICLR2025 !
We’re excited to introduce SCYLLA, an evaluation framework developed in collaboration with @ZhentingQi, @lhyTHU, @yibophd, @hima_lakkaraju and others not on X from MIT, UIUC and Meta AI. SCYLLA offers a new approach to assessing the generalization capabilities of LLMs by…
We (@chaoqi_w @yibophd @ZRChen_AISafety) have been eager to share our latest work on battling reward hacking since last November, but had to wait for the legal team's approval. Finally, we're excited to release: Causal Reward Modeling (CRM)! CRM tackles spurious correlations and…
🦃 At the end of Thanksgiving holidays, I finally finished the piece on reward hacking. Not an easy one to write, phew. Reward hacking occurs when an RL agent exploits flaws in the reward function or env to maximize rewards without learning the intended behavior. This is imo a…
Code is now released at github.com/Jam1ezhang/DYTO
We've ( @Yiming1254115 @ZRChen_AISafety ) been wondering why so many existing video understanding approaches stick to uniformly sampling a fixed number of frames (e.g., 8) from an entire video sequence as input. So...... Introducing DYTO, a training-free framework that…
Earlier this year, we introduced HALC, one of the first works to explore how visual tokens influence LVLM decoding and leverage them to reduce hallucinations. Continuing with this direction, we want to introduce our new paper: Dropout Decoding (arxiv.org/pdf/2412.06474).…
#ICML2024 📢 Check out our latest paper - HALC: Object Hallucination Reduction via Adaptive Focal-Contrast Decoding. HALC presents a novel decoding algorithm that significantly reduces object hallucinations in large vision-language models by integrating adaptive focal-contrast…
AgentPoison has been accepted for presentation at NeurIPS2024!!🎉🎉 Here is a quick recap😊: 🧐What is AgentPoison ? 🙋AgentPoison is the first backdoor attack against generic RAG-based LLM agents by poisoning their long-term memory or knowledge base. Specifically, we propose…
We know LLM agents 🤖 are powerful and popular these days, but can they be subverted to act as killer agents 😈 just like in Westworld?😱 Sadly, the answer is YES! 😱😱 🔥🔥 We reveal the vulnerability and potential threats of generic LLM agents in our new work AgentPoison:…