
Amir
@ai_hype_man
Ph.D. in eXplainable AI @KTHUniversity (2019-2024). Spotify Research Intern (2021).
Finally, a good modern book on causality for ML: causalai-book.net by @eliasbareinboim. This looks like a worthy successor to the ground breaking book by @yudapearl which I read in grad school. (h/t @JoshuaSafyan for the ref).
From GPT to MoE: I reviewed & compared the main LLMs of 2025 in terms of their architectural design from DeepSeek-V3 to Kimi 2. Multi-head Latent Attention, sliding window attention, new Post- & Pre-Norm placements, NoPE, shared-expert MoEs, and more... magazine.sebastianraschka.com/p/the-big-llm-…
I solved every single problem in the CUDA mode book. A quick thread summarizing this experience and what I learned 1/x
Reading survey papers was one of my favourite part of being a PhD. This is a good list of survey papers for ML enthusiasts: reddit.com/r/MachineLearn…

No one can name a standout ML paper from 2024—and that says everything about where ML research is headed. 📉 reddit.com/r/MachineLearn…

Free Python Programming Course in Persian by @hejazizo
کل ۹۳ قسمت دورهی پایتونم آپلود شد روی یوتیوب. از هر چی کورس داخلی و خارجی که دیدین با اختلاف بهتره و حاصل تجربهی بالای ده سال کد زدن مستمر به پایتونه و اون جوری که باید پایتون رو یاد بگیرین یاد میگیرین و لذت میبرین. youtube.com/watch?v=G9PbdX…
To avoid further suffering for humankind, here is where Neo4j Desktop 2 stores your dbs on MAC: ~/Library/Application\ Support/neo4j-desktop/Application/Data/dbmss/ > ls dbms-e307217f-40cc-401a-91ff-15387d4ce398
We benchmarked leading multimodal foundation models (GPT-4o, Claude 3.5 Sonnet, Gemini, Llama, etc.) on standard computer vision tasks—from segmentation to surface normal estimation—using standard datasets like COCO and ImageNet. These models have made remarkable progress;…
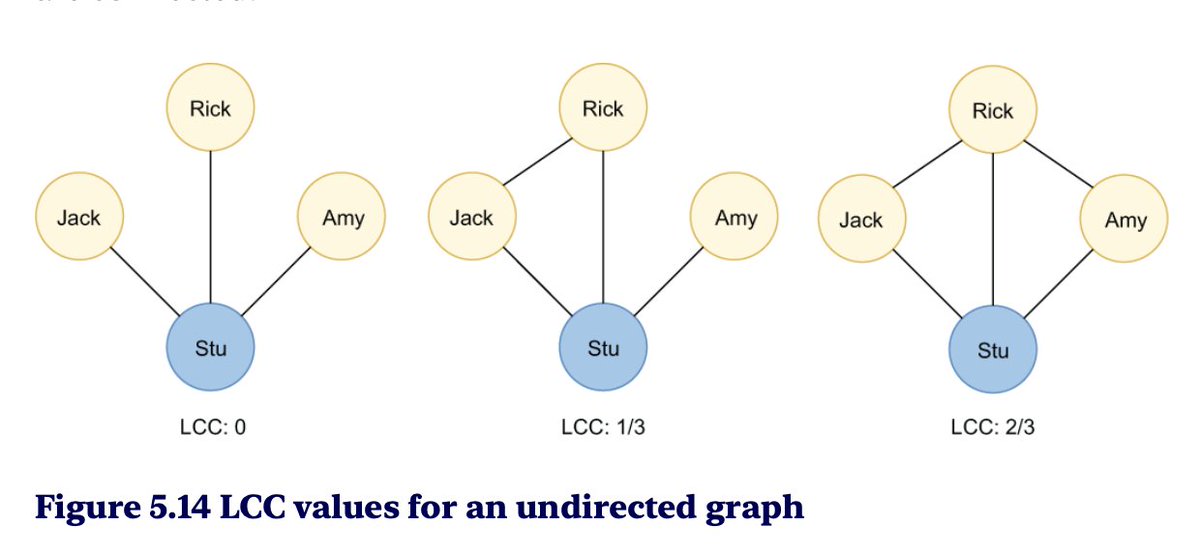
The interpretation of Local Clustering Coefficient (LCC) in undirected graphs are easy. It measures the number of neighbours of the examined node (blue) are connected to one another. Source: Graph Algorithms for Data Science by Bratanic
🚨 New results just in for LayerNorm Scaling (LNS)! 🚨 We scale up training with LNS across model sizes: 60M, 150M, 300M, 1B, and 7B, using the official OLMo repository @allen_ai. All models are trained with a fixed 20B-token budget. Results? Consistent gains over Pre-LN —…
We all recognize the strength of DeepSeek @deepseek_ai models, but did you know that nearly half of their layers contribute less than expected? We can remove nearly half of the later layers with minimal impact on performance—and even more for larger models. That means a…
Finally, after all these years of being mocked, ffmpeg enthusiasts win!
Machine learning is perhaps the only field that has become less mature over time. A reverse metamorphosis, from butterfly to caterpillar.
Every book Charlie Munger has recommended in Berkshire meetings since 1994:
Make it your goal in life to master three things: Game Theory, Probability, Supply/Demand.
Stanford CS336 - Language Modeling from Scratch Excellent new lectures on "language modelling from scratch" It covers a whole LLM stack from data collection, cleaning, transformer modelling and training, evals and deployment. Link in comments 😎👇
Proud to announce that my stealth team has made a breakthrough that will unlock the next leap: artificial HYPER intelligence, which will make ASI look like a weak and stupid baby. The $1tn seed round for our company, Safe Hyper Intelligent Technologies, is already oversubscribed.