Mohammed Adnan @ ICML 2025
@adnan_ahmad1306
PhD student @ UofC / Vector Institute; Previously: MLRG, University of Guelph | UWaterloo | IIT G Alumnus
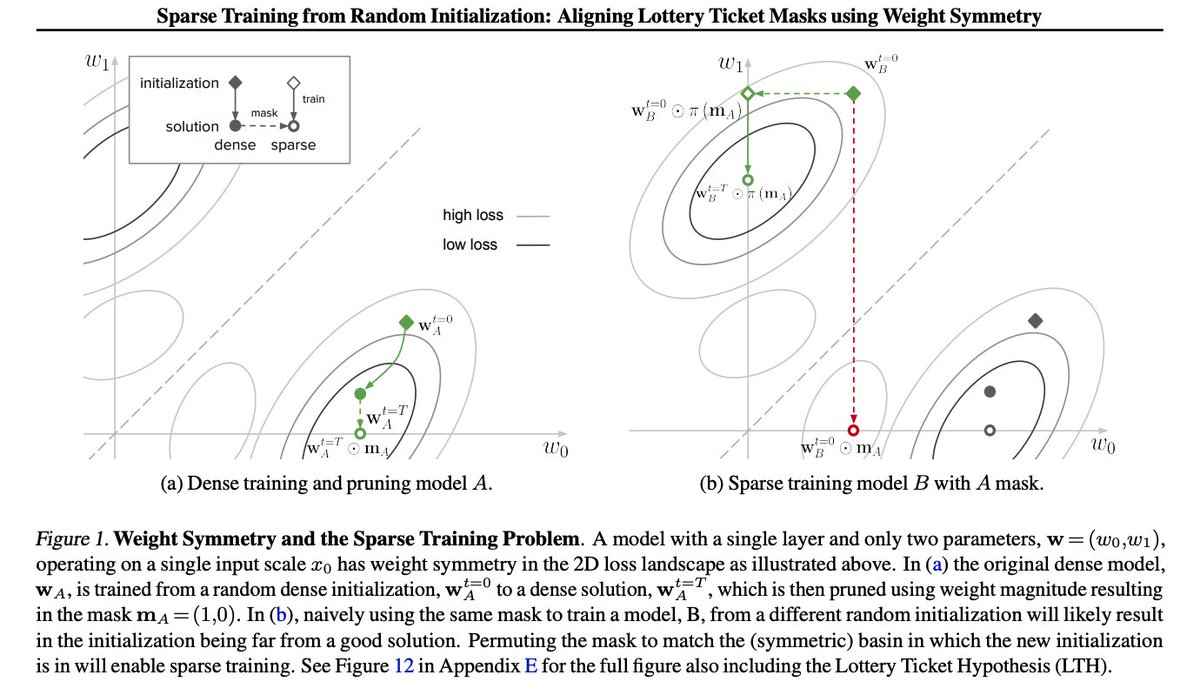
1/10 🧵 🔍Can weight symmetry provide insights into sparse training and the Lottery Ticket Hypothesis? 🧐We dive deep into this question in our latest paper, "Sparse Training from Random Initialization: Aligning Lottery Ticket Masks using Weight Symmetry", accepted at #ICML2025
We will be presenting Self-Distilled Sparse Drafters at #ICML this afternoon at the Efficient Systems for Foundation Models workshop. Come chat with us about acclerating speculative decoding! 🚀 @CerebrasSystems @UCalgaryML
Having ideas on backdoor attack, functional&representational similarity, and concept-based explainability? I am looking forward to all discussions. Come visit our posters today ! 📍 TAIG at West Meeting room 109 DIG-BUGS at West Ballroom A
I am excited to share that I will present two of my works at #ICML2025 workshops! If you are interested in AI security and XAI, feel free to come by and chat - I'm looking forward to all feedbacks and discussions!
We're bringing back our 'Vector Bytes' at #ICML2025 – your audio spotlight on Vector Faculty research! Today's poster presentations celebrate groundbreaking advances across multiple frontiers: - Colin Raffel's "The Butterfly Effect" reveals how tiny perturbations cause…
Our new ICML 2025 oral paper proposes a new unified theory of both Double Descent and Grokking, revealing that both of these deep learning phenomena can be understood as being caused by prime numbers in the network parameters 🤯🤯 🧵[1/8]
I am excited to share that I will present two of my works at #ICML2025 workshops! If you are interested in AI security and XAI, feel free to come by and chat - I'm looking forward to all feedbacks and discussions!
Excited to be presenting our work at ICML next week! If you're interested in loss landscapes, weight symmetries, or sparse training, come check out our poster — we'd love to chat. 📍 East Exhibition Hall A-B, #E-2106. 📅 Tue, July 15 | 🕚 11:00 a.m. – 1:30 p.m PDT.
1/10 🧵 🔍Can weight symmetry provide insights into sparse training and the Lottery Ticket Hypothesis? 🧐We dive deep into this question in our latest paper, "Sparse Training from Random Initialization: Aligning Lottery Ticket Masks using Weight Symmetry", accepted at #ICML2025
@UCalgaryML will be at #ICML2025 in Vancouver🇨🇦 next week: our lab has 6 different works being presented by 5 students across both the main conference & 6 workshops! We are also recruiting fully-funded ML PhD/MSc students🧑🎓If attending, reach out to me on Whova app to meet 📅
You don't _need_ a PhD (or any qualification) to do almost anything. A PhD is a rare opportunity to grow as an independent thinker in an academic environment, rather than immediately becoming a gear in a corporate agenda. It's definitely not for everyone!
You don’t need a PhD to be a great AI researcher. Even @OpenAI’s Chief Research Officer doesn’t have a PhD.
1/7 🚀 Thrilled to announce that our paper ExOSITO: Explainable Off-Policy Learning with Side Information for ICU Lab Test Orders has been accepted to #CHIL2025! Please feel free to come by my poster session this Thursday to chat. #MedAI #HealthcareAI
Few months ago researchers from Meta empirically found out that LayerNorm acts similar to a TanH, squeezing in the weights that are too high into more tractable values They tried to replace the LayerNorm with a TanH, and achieved similar results at higher speed What??? [1/8]
(1/5) 👑 New Discrete Diffusion Model — MDM-Prime Why restrict tokens to just masked or unmasked in masked diffusion models (MDM)? We introduce MDM-Prime, a generalized MDM framework that enables partially unmasked tokens during sampling. ✅ Fine-grained denoising ✅ Better…
It’s a hefty 206-page research paper, and the findings are concerning. "LLM users consistently underperformed at neural, linguistic, and behavioral levels" This study finds LLM dependence weakens the writer’s own neural and linguistic fingerprints. 🤔🤔 Relying only on EEG,…
Can neural networks learn to map from observational datasets directly onto causal effects? YES! Introducing CausalPFN, a foundation model trained on simulated data that learns to do in-context heterogeneous causal effect estimation, based on prior-fitted networks (PFNs). Joint…
Want faster #LLM inference without sacrificing accuracy? 🚀 Introducing SD², a novel method using Self-Distilled Sparse Drafters to accelerate speculative decoding. We show that self-data distillation combined #sparsity can be used to train low-latency, well-aligned drafters.🧵