
Rohan Paul
@rohanpaul_ai
🛸 Capturing, in real-time, the race towards AGI. 🗞️ Don't miss my daily top 1% AI analysis newsletter directly to your inbox 👉 https://www.rohan-paul.com
Today’s edition of my newsletter just went out. 🔗 rohan-paul.com/p/google-gemin… Consider subscribing, its free and I publish daily with top 1% AI developments. ⚡In today’s Edition (21-July-2025): 🥇Google Gemini Deep Think Achieves Gold at International Math Olympiad 🥉 New…
Simple tweaks to the wording of a prompt, like rephrasing the user history or asking the model to pause and think abstractly, lift recommendation accuracy on cheap LLMs, while heavy reasoning tricks often knock it down. The work tackles a common pain point, namely the…
TopicAttack shows LLMs fall when a hidden request arrives via gentle topic shifts, scoring 90% plus despite defenses. Current fixes simply repeat the user's question or flag data, yet they fail when an attacker approaches gradually. Indirect prompt injection plants harmful text…

Imagine what July 2026 holds for us 🤔
In July 2024, the top model was probably Sonnet 3.5, reasoning models did not exist, agents did not exist, LLMs didn't even use search (IIRC). In July 2025, two competing labs win IMO gold medals with models that think(!) for over an hour per problem(!) on hard-to-verify…
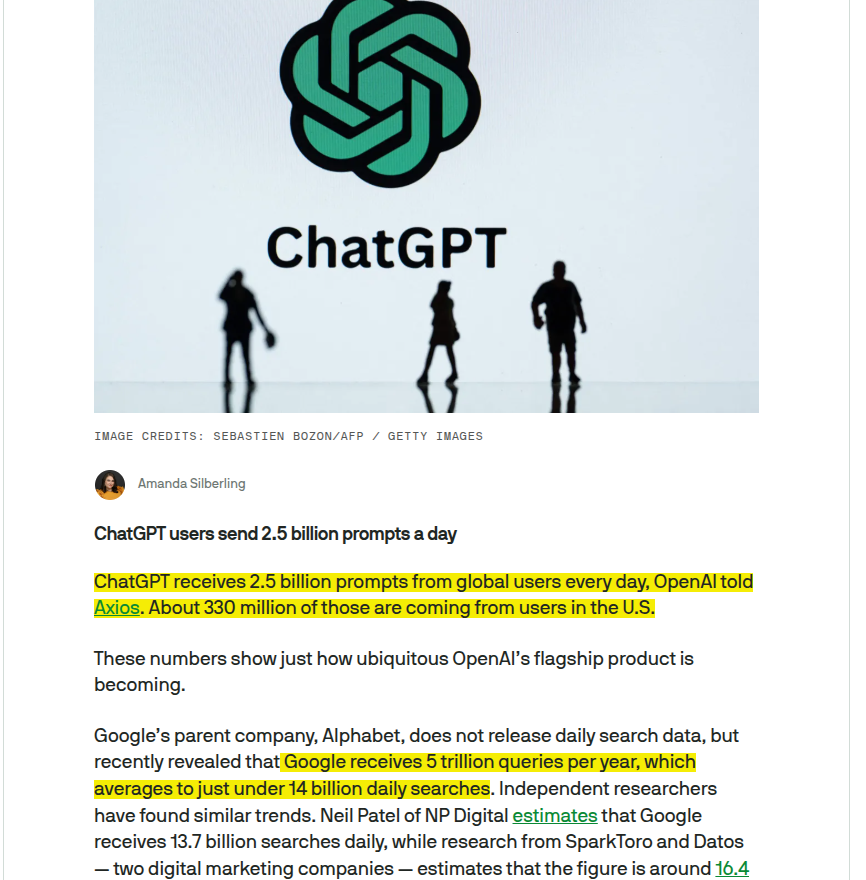
ChatGPT receives 2.5 billion prompts from global users every day, and about 330 million of those are coming from users in the U.S. Google receives around 14 billion daily searches. --- techcrunch .com/2025/07/21/chatgpt-users-send-2-5-billion-prompts-a-day
Even tiny 500K samples hold enough signal for Loan Default Early Prediction. Default risk flagged long before borrowers call. KAN‑powered GRU and LSTM flag mortgage trouble with 92% accuracy 3 months ahead and still hold 88% 8 months out. Classic time‑series models only…

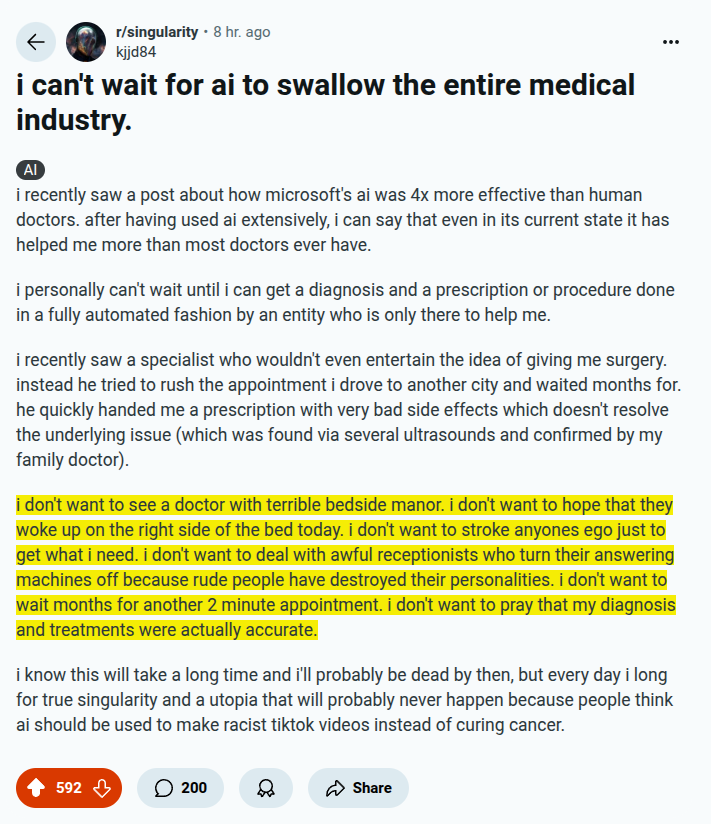
Honestly, for me too, AI taking over medicine can’t come fast enough.. ------ "i don't want to see a doctor with terrible bedside manor. i don't want to hope that they woke up on the right side of the bed today. i don't want to stroke anyones ego just to get what i need. i…
Watching AI design experiments makes me realize how much of what we call “theories” or “common knowledge” has been shaped by limited perspectives and human experience. In my own field, I have challenged and overturned such “established truths” many times. That is why I feel a…
AI proposes strange physics experiments that end up working. quantamagazine reports. The success shows AI explores physics problems too wide for grad students to map by hand. 🛠️ Here, AI skipped the usual tidy lab logic and delivered 10%–15% sharper gravitational-wave ears,…
Context engineering.
This guy is using this huge 40,000 character Meta-Prompt to turne ChatGPT into Warren Buffett. The prompt locks the model into acting as Warren Buffett by loading 40,000+ characters of his biography, routines, quotes, formulas, and case studies. It injects complete valuation…
After this update Qwen3 reclaimed the benchmark lead from Kimi 2. Note that their intended use differs. Kimi K2 markets itself as an “open agentic intelligence” engine that can plan multi‑step tool calls, run shell commands and even refactor full codebases out of the box.…
Qwen3-235B-A22B-2507 is out, replacing the previous Qwen3-235B-A22B. Hybrid thinking mode is dropped. So, this model now supports only non-thinking mode and does not generate <think></think> blocks in its output. Meanwhile, specifying enable_thinking=False is no longer…