
Anikait Singh
@Anikait_Singh_
PhD'ing @StanfordAILab @stanfordnlp, Intern @MSFTResearch. Previously @ToyotaResearch @GoogleDeepMind @Berkeley_AI http://asap7772.bsky.social
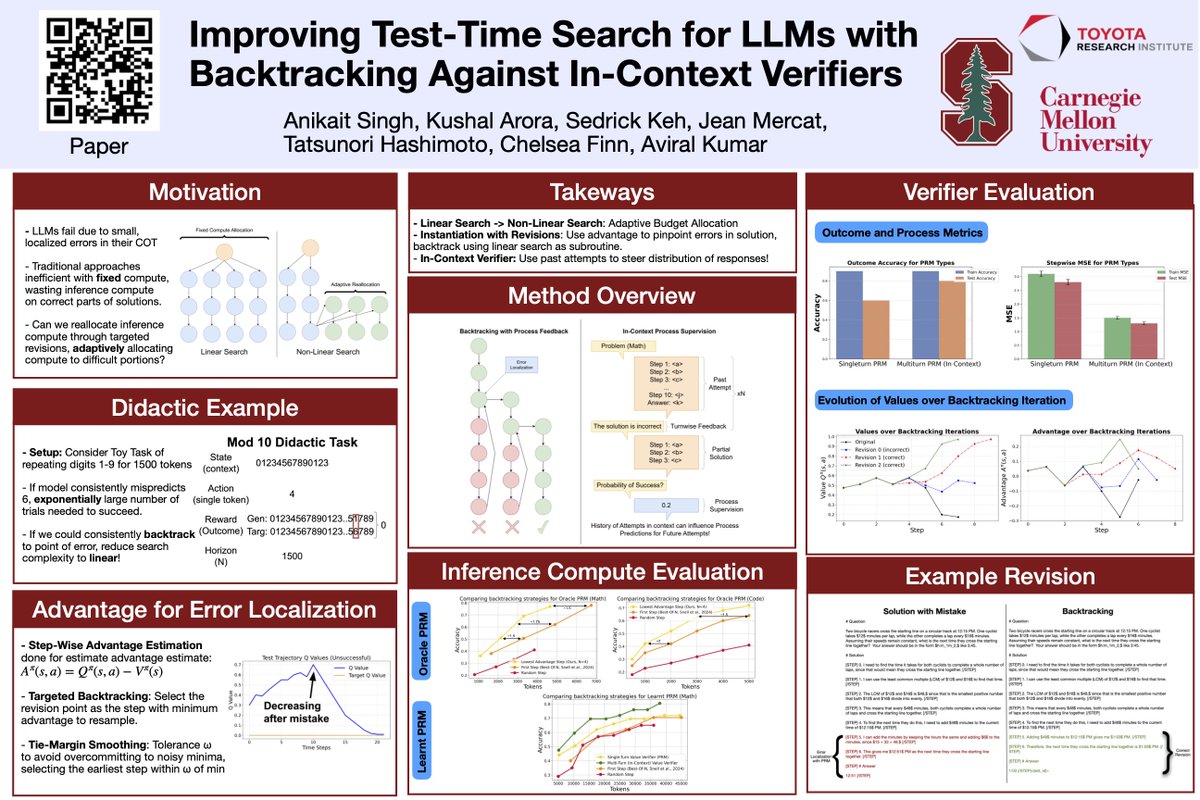
I’m in Singapore for #ICLR2025! Excited to present Improving Test-Time Search for LLMs with Backtracking Against In-Context Value Verifiers (openreview.net/pdf?id=ZXRKOAf…). Workshops: - Reasoning and Planning for LLMs — Oral Session April 28 - SSI-FM — Poster Happy to chat/meet up!
Given the confusion around what RL does for reasoning in LLMs, @setlur_amrith & I wrote a new blog post on when RL simply sharpens the base model & when it discovers new reasoning strategies. Learn how to measure discovery + methods to enable it ⬇️ tinyurl.com/rlshadis
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
Heading to @icmlconf #ICML2025 this week! DM me if you’d like to chat ☕️ Come by our poster sessions on: 🧠 Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning (arxiv.org/abs/2503.07572) 🔍 Learning to Discover Abstractions for LLM Reasoning (drive.google.com/file/d/1Sfafrk…)
#CVPR2025 "Personalized Preference Fine-tuning of Diffusion Models". We extend DPO to align text-to-image diffusion models with individual user preferences. At test time, it generalizes to unseen users from just few-shot examples — moving toward pluralistic alignment.
🧵 1/7 Should AI agents "think more" or "do more"? 🤔 The current trend is to scale test-time compute, making agents generate longer reasoning traces. But what if that’s the wrong approach for interactive tasks? In our new work, we argue for a new scaling dimension: Test-Time…
We found a way to do RL *only* with BC policies. The idea is simple: 1. Train a BC policy π(a|s) 2. Train a conditional BC policy π(a|s, z) 3. Amplify(!) the difference between π(a|s, z) and π(a|s) using CFG Here, z can be anything (e.g., goals for goal-conditioned RL). 🧵↓
RL with verifiable reward has shown impressive results in improving LLM reasoning, but what can we do when we do not have ground truth answers? Introducing Self-Rewarding Training (SRT): where language models provide their own reward for RL training! 🧵 1/n
2.5 Pro Deep Think is an incredibly smart model. Some of the benchmark results, simply put were surprising to me. But, the benchmarks don’t tell the whole story. It can go into far more intricate details, especially open-ended prompts, unlike any of our previous thinking models.
🧠Memory is crucial for robots — to handle occlusions, track progress, stay coherent, etc. Yet, most VLA truncate context. 🤔Why is long-context hard for robot policies? And how can we fix it? 📄Our new paper: Learning Long-Context Diffusion Policies via Past-Token Prediction
Giving history to our robot policies is crucial to solve a variety of daily tasks. However, diffusion policies get worse when adding history. 🤖 In our recent work we learn how adding an auxiliary loss that we name Past-Token Prediction (PTP) together with cached embeddings…
Robotic models are advancing rapidly—but how do we scale their improvement? 🤖 We propose a recipe for batch online RL (train offline with online rollouts) that enables policies to self-improve without complications of online RL More: pd-perry.github.io/batch-online-rl (1/8)
Giving history to our robot policies is crucial to solve a variety of daily tasks. However, diffusion policies get worse when adding history. 🤖 In our recent work we learn how adding an auxiliary loss that we name Past-Token Prediction (PTP) together with cached embeddings…
40% with just 1 try per task: SWE-agent-LM-32B is the new #1 open source model on SWE-bench Verified. We built it by synthesizing a ton of agentic training data from 100+ Python repos. Today we’re open-sourcing the toolkit that made it happen: SWE-smith.
Not all human-collected demos are created equal: ✔️ All are successful ❌ But some strategies are unreliable or brittle This can hurt final performance. Demo-SCORE self-curates reliable training data using online experience. Paper and videos: anniesch.github.io/demo-score/
1/🧵 While reasoning models like DeepSeek-R1 are making waves with impressive coding & math capabilities, their potential for harmful and illegal applications remain largely unexplored. We’re excited to release HELM Safety v1.1 to shed light on these questions 👇:
🚨 NEW PAPER: "Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning"! 🤔 With all these long-reasoning LLMs, what are we actually optimizing for? Length penalties? Token budgets? We needed a better way to think about it! Website: cohenqu.github.io/mrt.github.io/ 🧵[1/9]
Interacting with the external world and reacting based on outcomes are crucial capabilities of agentic systems, but existing LLMs’ ability to do so is limited. Introducing Paprika 🌶️, our work on making LLMs general decision makers than can solve new tasks zero-shot. 🧵 1/n
Continual pre-training today optimizes for domain-specific knowledge. Instead, can we optimize for behaviors, further amplified through RL for reasoning? We study how to controllably prime behaviors from synthetic and pretrained datasets. Paper: arxiv.org/abs/2503.01307
New Paper!! We try to understand why some LMs self-improve their reasoning while others hit a wall. The key? Cognitive behaviors! Read our paper on how the right cognitive behaviors can make all the difference in a model's ability to improve with RL! 🧵1/13
thrilled to see Big-MATH climbing to #3️⃣ on @huggingface—clear signal the community wants more high-quality, verifiable RL datasets. grateful to everyone who’s been liking, downloading, and supporting ❤️
Releasing Big-MATH—the first heavily curated & verifiable dataset designed specifically for large-scale RL training & LLM reasoning! 📝 250,000+ problems, 47k NEW Q's ✅ 10x larger than existing datasets like MATH 🧑⚖️ Verifiable—we eliminated 400k+ problems Details below! 🧵👇