Yana Wei
@yanawei_
PhD student@Johns Hopkins University; Multimodal Understanding, Embodied Agent, Image Editing
🔥 Thrilled to release our new multimodal RL work: Open Vision Reasoner! A powerful 7B model with SOTA performance on language & vision reasoning benchmarks, trained with nearly 1K steps of multimodal RL. Our journey begins with a central question: Can the cognitive behaviors…
🪞 We'll present Perception in Reflection at ICML this week! We introduce RePer, a dual-model framework that improves visual understanding through reflection. Better captions, fewer hallucinations, stronger alignment. 📄 arxiv.org/pdf/2504.07165 #ICML2025 @yanawei_ @JHUCompSci
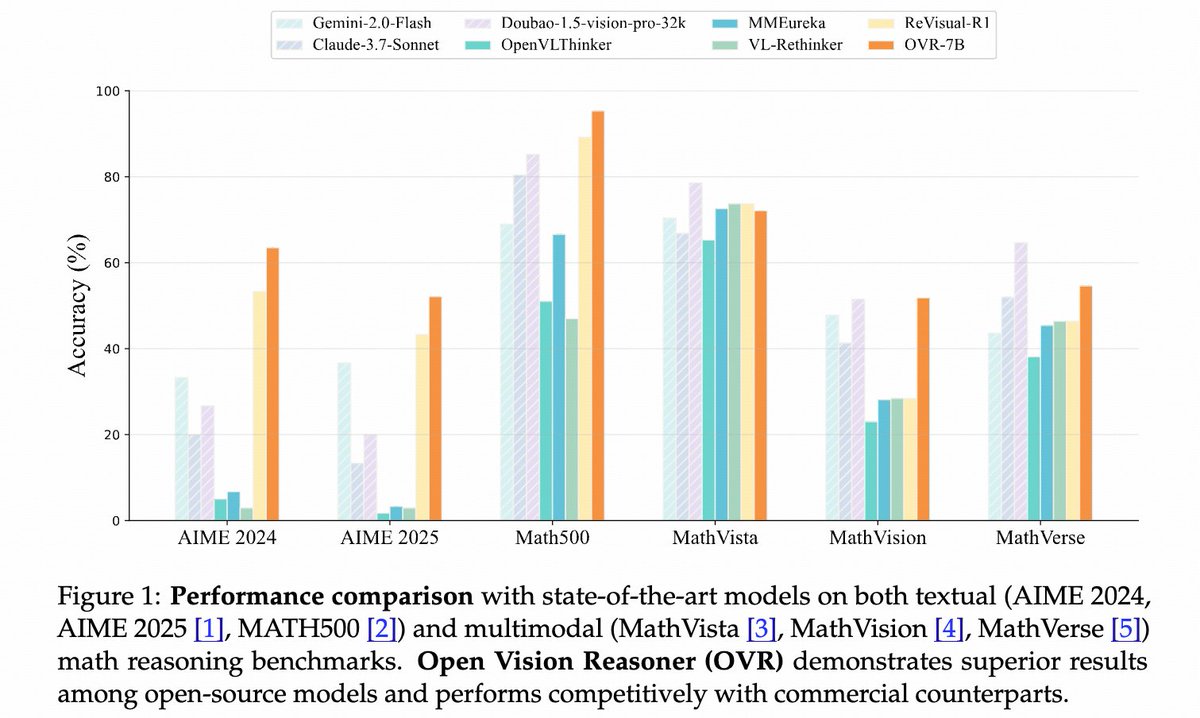
🚀 Open Vision Reasoner (OVR) Transferring linguistic cognitive behaviors to visual reasoning via large-scale multimodal RL. SOTA on MATH500 (95.3%), MathVision, and MathVerse. 💻 Code: github.com/Open-Reasoner-… 🌐 Project: weiyana.github.io/Open-Vision-Re… #LLM @yanawei @HopkinsEngineer
Kimi k2 + groq in anycoder Vibe coding 500+ loc Three.js mobile game in seconds
Just three words and one link—beautiful project pages in surprising styles! ✨ Try magic Anycoder by @_akhaliq here 👉 huggingface.co/spaces/akhaliq… Original pages have totally different vibes! (weiyana.github.io/Perception-in-…)
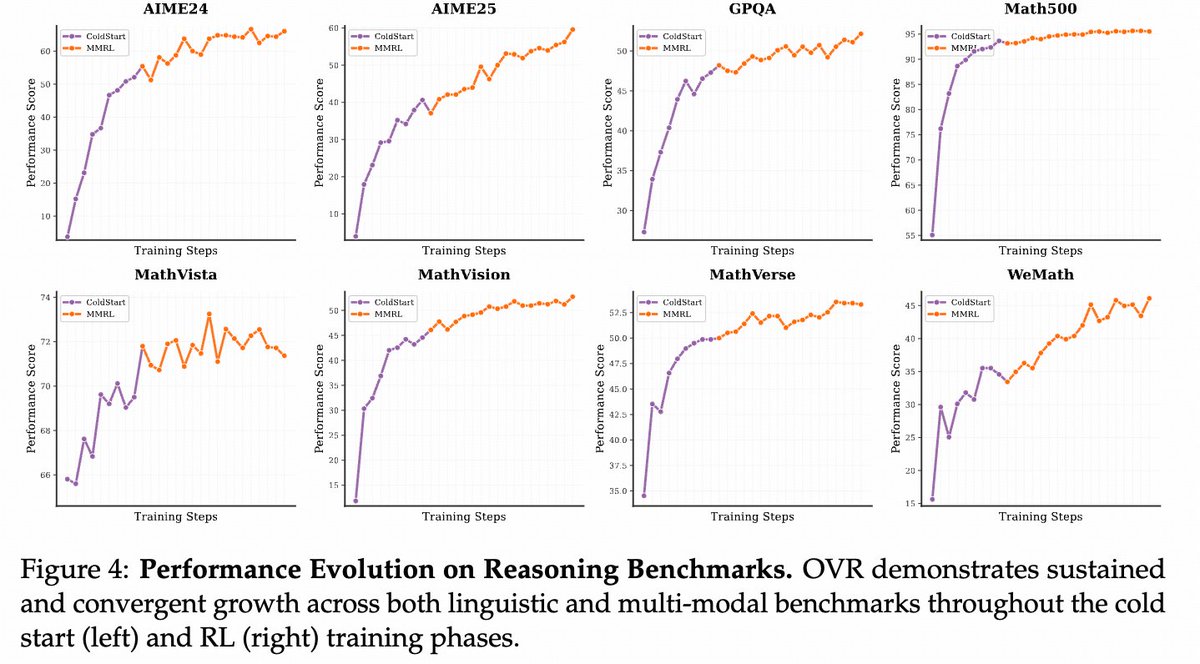
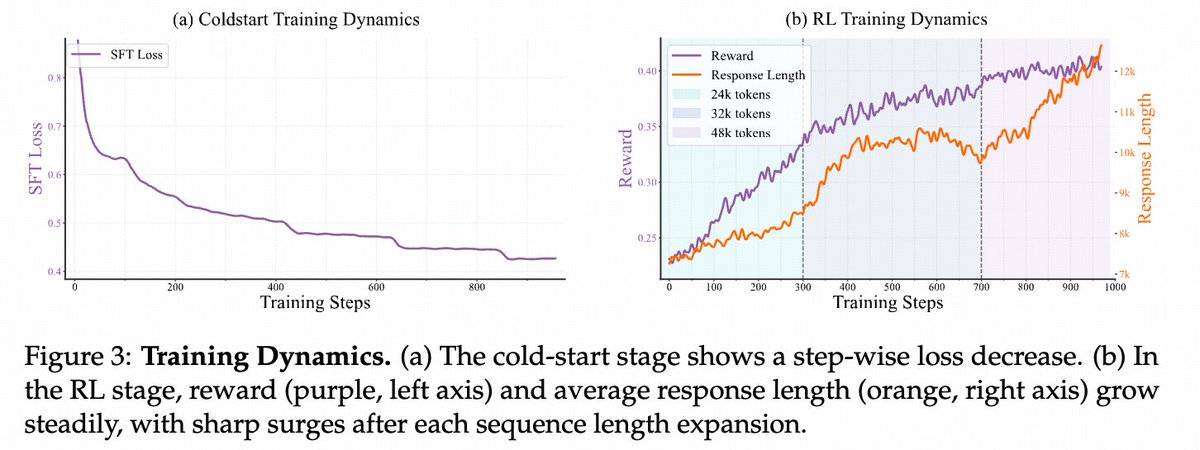
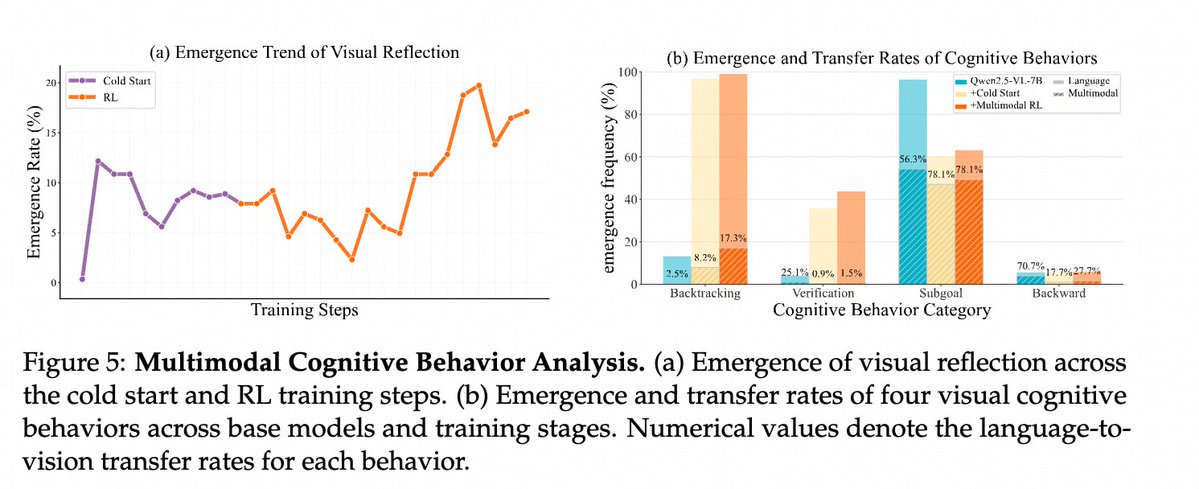
🥳 Thanks @_akhaliq for featuring our OVR! We’re continuously iterating on both models and data to release even more 🚀 powerful versions—stay tuned! Check out the nearly 1K-step multimodal RL and in-depth cognitive behavior analysis here: ✍️ ArXiv: arxiv.org/abs/2507.05255 🐼…
Open Vision Reasoner Transferring Linguistic Cognitive Behavior for Visual Reasoning
We are excited to introduce Open Vision Reasoner (OVR) 🚀 — transferring linguistic cognitive behavior to unlock advanced visual reasoning! 💡 Two-stage recipe • Massive linguistic cold-start on Qwen-2.5-VL-7B sparks “mental imagery” • ~1 k-step multimodal RL refines & scales…