
Vishal Patel
@vishalm_patel
Associate Professor @JohnsHopkins working on computer vision, biometrics, and medical imaging.
Even the most advanced MLLMs struggle spotting deepfakes or counting crowds when put the test with @vishalm_patel's FaceXBench. The team proposes expanding training data, incorporating face-processing APIs, & developing techniques to reduce bias. engineering.jhu.edu/news/face-to-f…
🚀 Check out our ✈️ ICML 2025 work: Perception in Reflection! A reasonable perception paradigm for LVLMs should be iterative rather than a single-pass. 💡 Key Ideas 👉 Builds a perception-feedback loop through a curated visual reflection dataset. 👉 Utilizes Reflective…
🪞 We'll present Perception in Reflection at ICML this week! We introduce RePer, a dual-model framework that improves visual understanding through reflection. Better captions, fewer hallucinations, stronger alignment. 📄 arxiv.org/pdf/2504.07165 #ICML2025 @yanawei_ @JHUCompSci
🚀 Open Vision Reasoner (OVR) Transferring linguistic cognitive behaviors to visual reasoning via large-scale multimodal RL. SOTA on MATH500 (95.3%), MathVision, and MathVerse. 💻 Code: github.com/Open-Reasoner-… 🌐 Project: weiyana.github.io/Open-Vision-Re… #LLM @yanawei @HopkinsEngineer
#ICCV2025 🌺FaceXFormer has been accepted by ICCV !
FaceXFormer: A Unified Transformer for Facial Analysis w/ @vibashan @KartikNarayan10 @jhuclsp @HopkinsEngineer @JHUECE Paper: arxiv.org/abs/2403.12960 Code: github.com/Kartik-3004/fa… Website: kartik-3004.github.io/facexformer_we…
🎨 New work: Training-Free Stylized Abstraction Generate stylized avatars (LEGO, South Park, dolls) from a single image ! 💡 VLM-guided identity distillation 📊 StyleBench eval @HopkinsDSAI @JHUECE @jhucs @KartikNarayan10 @HopkinsEngineer 🔗 kartik-3004.github.io/TF-SA/

STEREO: A Two-Stage Framework for Adversarially Robust Concept Erasing from Text-to-Image Diffusion Models tldr: iteratively discover and mitigate adversarial prompts, then go back to original model and mitigate in parallel (with anchor concepts to reduce unwanted side effects)…
Hopkins researchers including @JHUECE Tinoosh Mohsenin and @JHU_BDPs Rama Chellappa are speaking at booth 1317 of the IEEE / CVF Computer Vision and Pattern Recognition Conference today! Come meet #HopkinsDSAI #CVPR2025
The #WACV2026 Call for Papers is live at wacv.thecvf.com/Conferences/20……! First round paper registration is coming up on July 11th, with the submission deadline on July 18th (all deadlines are 23:59 AoE).
@CVPR IS AROUND THE CORNER! #CVPR2025 Welcome to join our Medical Vision Foundation Model Workshop on June 11th, from 8:30 to 12:00 at Room 212.! We are also proud to host an esteemed lineup of speakers: Dr. Jakob Nikolas Kather @jnkath Dr. Faisal Mahmood @AI4Pathology Dr.…
Excited to announce the 2nd Workshop on Foundation Models for Medical Vision (FMV) at #CVPR2025! @CVPR 🌐 fmv-cvpr25workshop.github.io FMV brings together researchers pushing the boundaries of medical AGI. We are also proud to host an esteemed lineup of speakers: Dr. Jakob Nikolas…
🚨Excited to share that the JHU VIU Lab will be presenting the following papers at CVPR next week, including 3 Highlights! 🎉 Come stop by our posters and say hi — we’d love to connect! 👋 #CVPR2025 @JHUCompSci @JHUECE @HopkinsDSAI @HopkinsEngineer

💥 New paper: Think Before You Diffuse Meet DiffPhy — LLM-guided, physics-aware video diffusion 🎥🧠🌍 SOTA on real-world motion & dynamics! 🔗 bwgzk-keke.github.io/DiffPhy/ @JHUCompSci @HopkinsDSAI @HopkinsEngineer @myq_1997 #DiffusionModels #VideoGeneration
Honored to be speaking alongside other respected experts at the Biometrics Institute US Biometrics Seminar. We’ll be diving into US biometrics developments and the crucial topic of AI’s impact on vulnerabilities. @HopkinsDSAI @JHUECE @JHUCompSci @HopkinsEngineer @BiometricsInst

🥳🥳Two papers accepted in FG 2025 !!! Improved Representation Learning for Unconstrained Face Recognition w/ @NithinGK10 @vishalm_patel Investigating Social Biases in Multimodal LLMs w/ Malsha Perera, @vishalm_patel
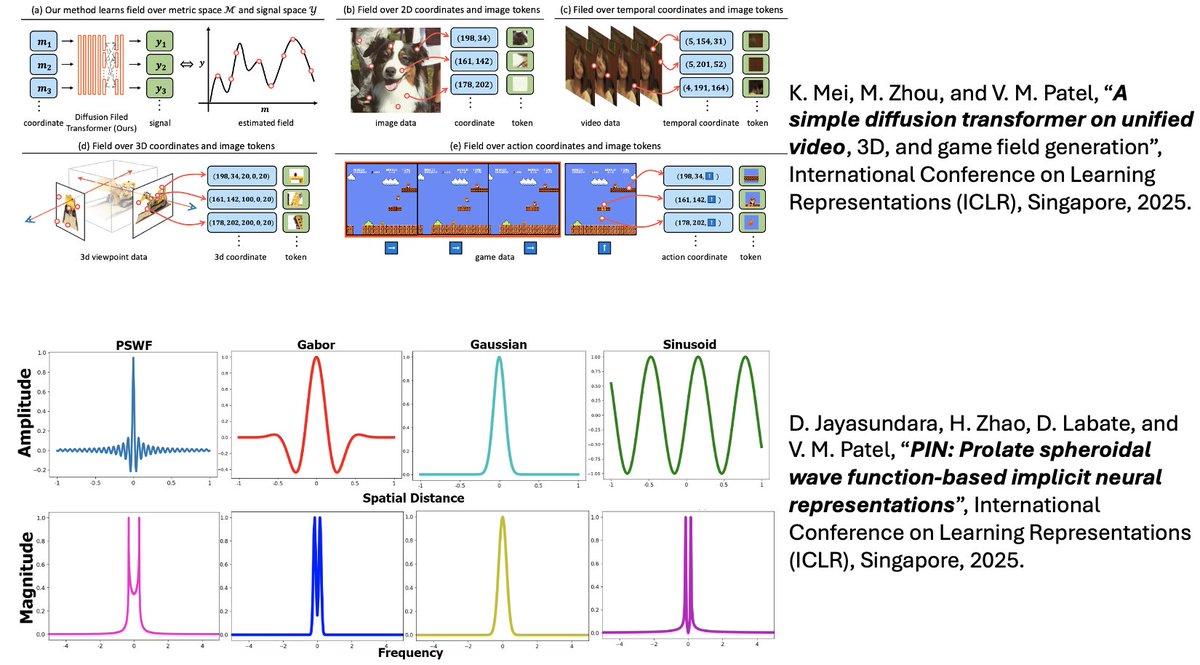
Excited to present two papers at #ICLR2025 next week! Looking forward to sharing our work in Singapore! 🇸🇬. @KangfuM @JHUECE @HopkinsDSAI kfmei.com/Field-DiT/
Excited to announce the 2nd Workshop on Foundation Models for Medical Vision (FMV) at #CVPR2025! @CVPR 🌐 fmv-cvpr25workshop.github.io FMV brings together researchers pushing the boundaries of medical AGI. We are also proud to host an esteemed lineup of speakers: Dr. Jakob Nikolas…
Had the incredible opportunity to meet Prof. Takeo Kanade at JHU today! Such an honor to chat with a true legend in computer vision. Of course, I couldn’t miss the chance to get a signature on his seminal Lucas-Kanade paper! 📄✍️#ComputerVision @JHUECE @JHUCompSci

Congratulations to the research team at our sister company @eyelinestudios on their latest research paper - “Lux Post Facto: Learning Portrait Performance Relighting with Conditional Video Diffusion and a Hybrid Dataset” - which will be presented at #CVPR2025 in Nashville.…
We see the world in vivid detail in part because our visual perception is immersed in the broader context of a 3D world, language, and other queues. In our new paper we show that such broader context is also helpful with tasks in low-level vision such as image restoration 1/n
Check out our latest work on multimodal super-resolution diffusion accepted by #CVPR2025 🔥🔥🔥! We show that using richer context in guiding image diffusion model can always improves the performance. Guidance like depth and edge is especially useful to enrich the language…
We see the world in vivid detail in part because our visual perception is immersed in the broader context of a 3D world, language, and other queues. In our new paper we show that such broader context is also helpful with tasks in low-level vision such as image restoration 1/n