
Yasmine
@CyouSakura
Researcher @StepFun_ai. Working on scalable RL methods in #LLM. she/her/hers. 守护最好的猫猫@biliacat_public
We are excited to introduce Open Vision Reasoner (OVR) 🚀 — transferring linguistic cognitive behavior to unlock advanced visual reasoning! 💡 Two-stage recipe • Massive linguistic cold-start on Qwen-2.5-VL-7B sparks “mental imagery” • ~1 k-step multimodal RL refines & scales…



Honestly blown away by how fast I built the Open Vision Reasoner (OVR) homepage — all thanks to Anycoder + Kimi K2! 🛠️ Anycoder is a free, open-source coding playground built entirely in Gradio — super intuitive and perfect for rapid prototyping. Give it a try 👉…

awards.acm.org/about/2024-tur… Machines that learn from experience were explored by Alan Turing almost eighty years ago, which makes it particularly gratifying and humbling to receive an award in his name for reviving this essential but still nascent idea.
Thanks for the enthusiasm! We’re finishing final checks on the training datasets and will release soon so everyone can build on Open Vision Reasoner. Stay tuned!
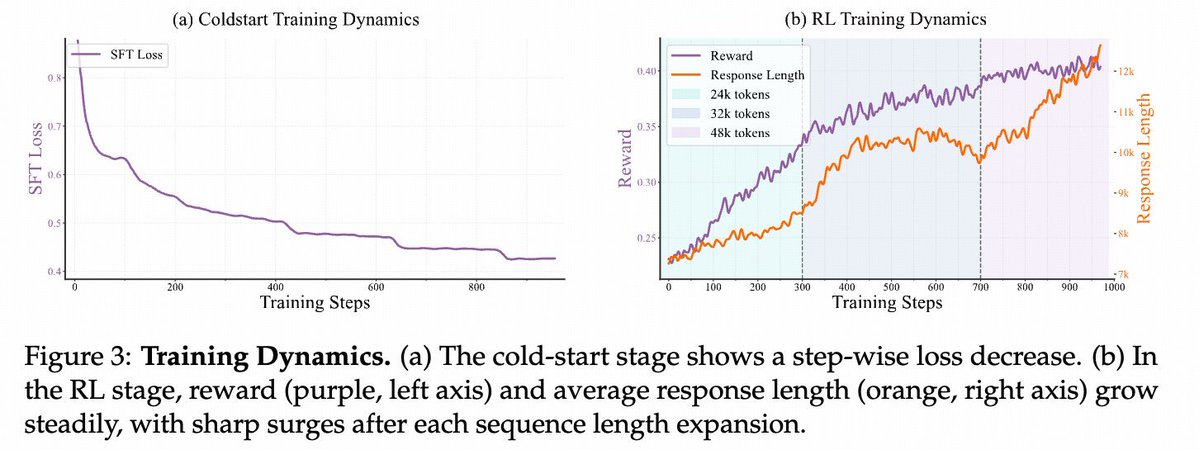
Open Vision Reasoner Transferring Linguistic Cognitive Behavior for Visual Reasoning
Open Vision Reasoner Transferring Linguistic Cognitive Behavior for Visual Reasoning
🔥 Thrilled to release our new multimodal RL work: Open Vision Reasoner! A powerful 7B model with SOTA performance on language & vision reasoning benchmarks, trained with nearly 1K steps of multimodal RL. Our journey begins with a central question: Can the cognitive behaviors…
Thrilled to introduce Kimi-Dev-72B, our new open-source coding LLM for software engineering tasks. Kimi-Dev-72B achieves 60.4% resolve rate on SWE-bench Verified, setting a new SoTA result among open-source models. (1/5)
Day 1/5 of #MiniMaxWeek: We’re open-sourcing MiniMax-M1, our latest LLM — setting new standards in long-context reasoning. - World’s longest context window: 1M-token input, 80k-token output - State-of-the-art agentic use among open-source models - RL at unmatched efficiency:…
📢 (1/16) Introducing PaTH 🛣️ — a RoPE-free contextualized position encoding scheme, built for stronger state tracking, better extrapolation, and hardware-efficient training. PaTH outperforms RoPE across short and long language modeling benchmarks arxiv.org/abs/2505.16381
Introducing Qwen3! We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general…
Big update to our MathArena USAMO evaluation: Gemini 2.5 Pro, which was released *the same day* as our benchmark, is the first model to achieve non-trivial amount of points (24.4%). The speed of progress is really mind-blowing.
Open-Reasoner-Zero is out on Hugging Face An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
🥳 Excited to announce major updates to Open-Reasoner-Zero (ORZ), our open-source initiative scaling Reinforcement Learning on base models! 🌊 Updated Paper & Superior Results Using the same base model as DeepSeek-R1-Zero, ORZ-32B achieves better performance on AIME2024,…


After hacking GPT-4o's frontend, I made amazing discoveries: 💡The line-by-line image generation effect users see is just a browser-side animation (pure frontend trick) 🔦OpenAI's server sends only 5 intermediate images per generation, captured at different stages 🎾Patch size=8
Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1. Blog: qwenlm.github.io/blog/qwq-32b HF: huggingface.co/Qwen/QwQ-32B ModelScope: modelscope.cn/models/Qwen/Qw… Demo: huggingface.co/spaces/Qwen/Qw… Qwen Chat:…