
Yacine Mahdid
@yacinelearning
(neuro/ai) I make technical deep learning tutorials 👺
if there is one thing that you must not do is surrender don’t surrender your dreams, your passion, your curiosity or your freedom never

I’m tweeting from here btw I just pace back and forth the trail while sipping espresso

everyone meet alex very smart engineer/researcher he co-authored a bunch of interesting LLM papers worth a look 🤝
Share some with me bro
people slowly realizing how simple stuff are in deep learning doesn’t get old
some X employees started to follow me on here and I don’t know how tell them

I knew at a young age that cyanide was a dangerous compound for a single reason
most technical topics look complicated because it’s like 7+ simple things mushed together untangle then understand
4000 of you folks follows me to learn about deep learning it’s absolutely amazing you are all there for deep learning and nothing else just the deep learning part wow
New Anthropic Research: “Inverse Scaling in Test-Time Compute” We found cases where longer reasoning leads to lower accuracy. Our findings suggest that naïve scaling of test-time compute may inadvertently reinforce problematic reasoning patterns. 🧵
day started with discussion about both the adam optimizers and the og adam from eden incredible meta going right now
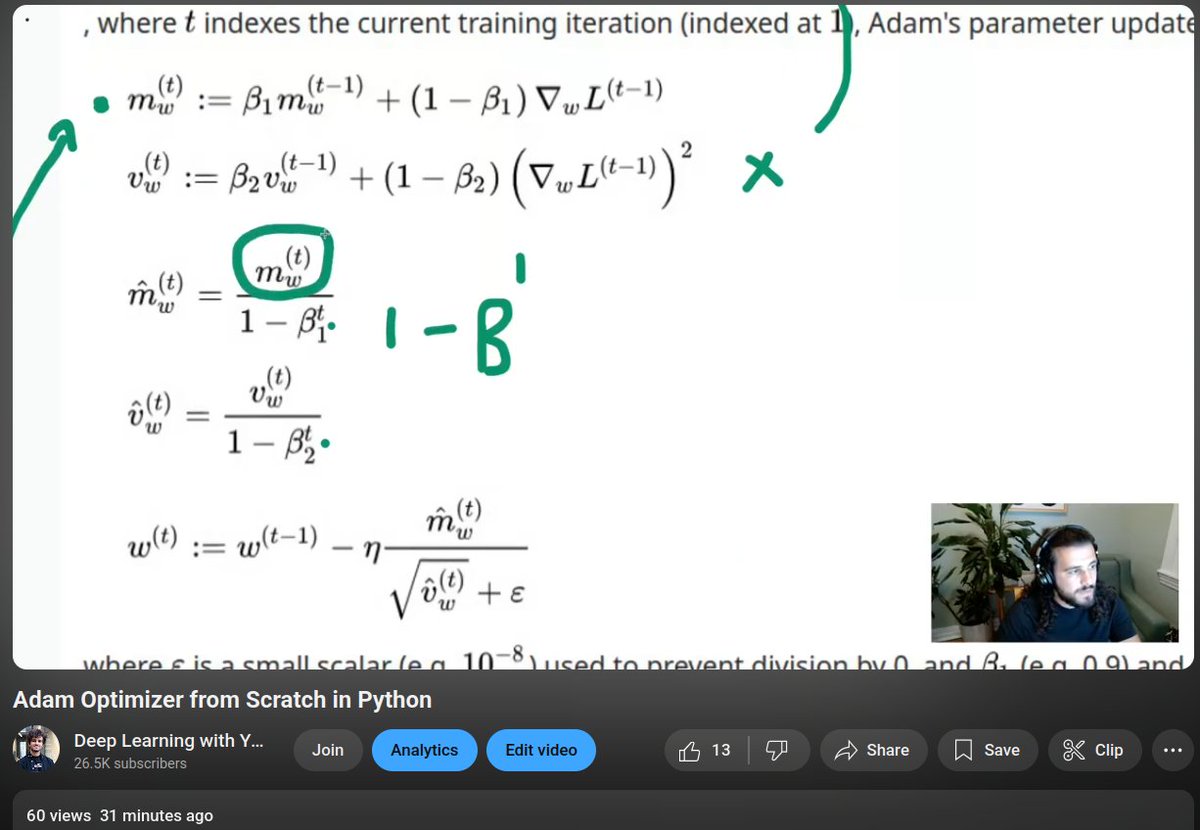
15 min tutorial on the adam optimizer by the end of it you will understand what is up with the formula 100% you'll see it's not that complicated™️
> low value work (like data cleaning) uh...
Academia must be the only industry where extremely high-skilled PhD students spend much of their time doing low value work (like data cleaning). A 1st year management consultant outsources this immediately. Imagine the productivity gains if PhDs could focus on thinking
The new Qwen3 update takes back the benchmark crown from Kimi 2. Some highlights of how Qwen3 235B-A22B differs from Kimi 2: - 4.25x smaller overall but has more layers (transformer blocks); 235B vs 1 trillion - 1.5x fewer active parameters (22B vs. 32B) - much fewer experts in…
Kimi K2 🆚 Qwen-3-235B-A22B-2507 The new updated Qwen 3 model beats Kimi K2 on most benchmarks. The jump on the ARC-AGI score is especially impressive An updated reasoning model is also on the way according to Qwen researchers
How to train a State-of-the-art agent model. Let's talk about the Kimi K2 paper.
Kimi K2 tech report is full of gems as always. Here are my notes on it: > MuonClip: Pretty crazy how after 70k the training stabilizes and the QK-clip is basically inactive. There is also no loss in perf with QK-clip which is not trivial at all (at small scale but with…
Kimi K2 paper dropped! describes: - MuonClip optimizer - large-scale agentic data synthesis pipeline that systematically generates tool-use demonstrations via simulated and real-world environments - an RL framework that combines RLVR with a self- critique rubric reward mechanism…
I’ve been on a 2 days coffee binge it’s been like my 10th espresso in 42h and I feel limitless and task are getting destroyed right now while I listen to lana del ray on blast and on loop wow