Thinh
@thinhphp_vt
PhD student @VT_CS, supervised by @tuvllms. Interested in search-augmented LLMs. Ex AI resident @VinAI_Research
We just released the evaluation of LLMs on the 2025 IMO on MathArena! Gemini scores best, but is still unlikely to achieve the bronze medal with its 31% score (13/42). 🧵(1/4)
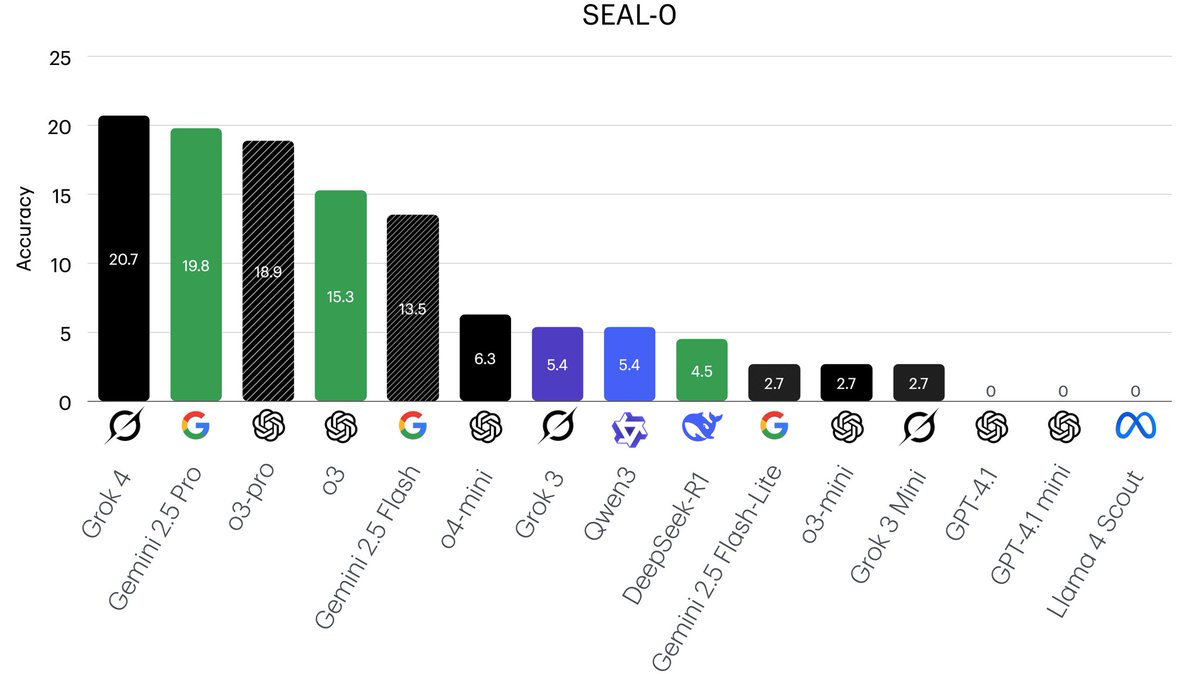
We just evaluated Grok 4 on our SEAL-0 dataset 👍Try it: huggingface.co/datasets/vtllm…
Tokenization has been the final barrier to truly end-to-end language models. We developed the H-Net: a hierarchical network that replaces tokenization with a dynamic chunking process directly inside the model, automatically discovering and operating over meaningful units of data
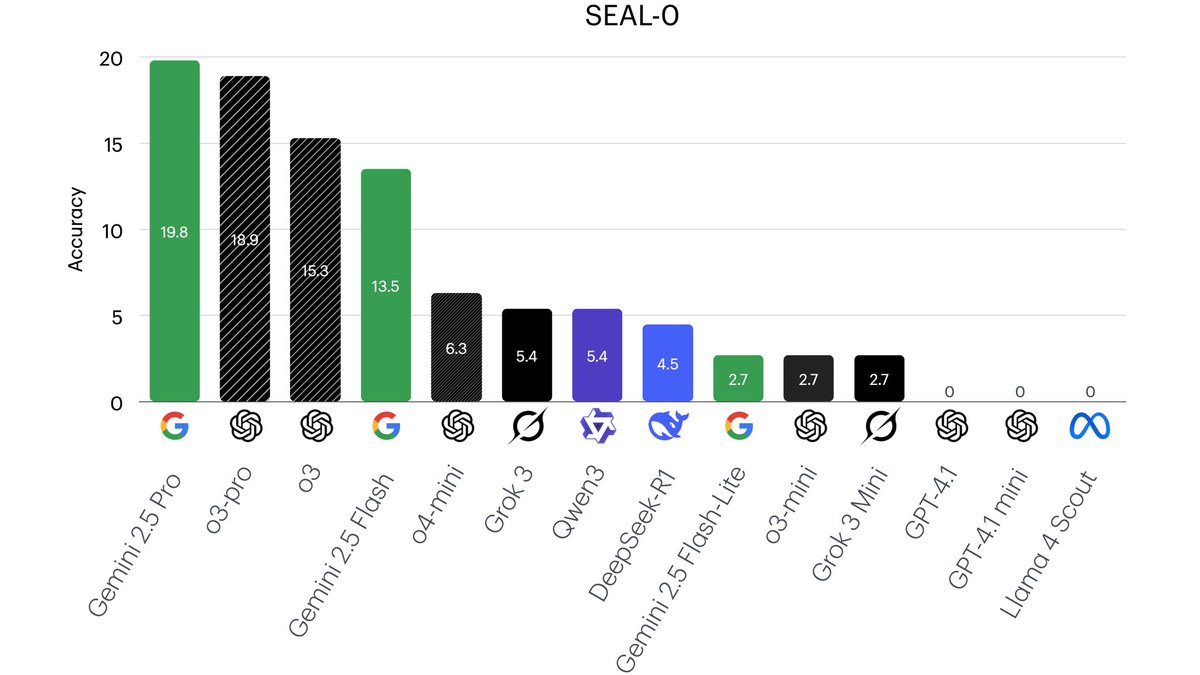
🔥 SEAL-0 Leaderboard 📈 Our results on SEAL-0 show a large room for improvement in LLMs' ability to reason over conflicting evidence. 🤯 👉Checkout our paper: arxiv.org/abs/2506.01062 👉Dataset: huggingface.co/datasets/vtllm…
My first work done during my PhD 🥳🥳🥳
✨ New paper ✨ 🚨 Scaling test-time compute can lead to inverse or flattened scaling!! We introduce SealQA, a new challenge benchmark w/ questions that trigger conflicting, ambiguous, or unhelpful web search results. Key takeaways: ➡️ Frontier LLMs struggle on Seal-0 (SealQA’s…
✨ New paper ✨ 🚨 Scaling test-time compute can lead to inverse or flattened scaling!! We introduce SealQA, a new challenge benchmark w/ questions that trigger conflicting, ambiguous, or unhelpful web search results. Key takeaways: ➡️ Frontier LLMs struggle on Seal-0 (SealQA’s…