
Tessa Barton
@tessybarton
GPU purse inventor. AI Research Scientist. Prev: @MosaicML x @Databricks, @Snapchat
The Lion Optimizer doesn’t concern himself with the opinions of the second moment
We doubled our users last month (and this month too)💅 PS: july batch sold out between filming and posting this so next chance to join is october
📢Now open, Gemma 3n weights & it is natively flexible, first of its kind, thanks to MatFormer🪆 Any model between E4B & E2B with ZERO training near Pareto -- we found a bunch! Find a better E3B than what we released, I will send you a 🪆😉 Find the colab for extraction 🧵👇🪆
Announcing the full release of Gemma 3n, bringing powerful multimodal capabilities to edge devices for developers 🙌 ↓ developers.googleblog.com/en/introducing…
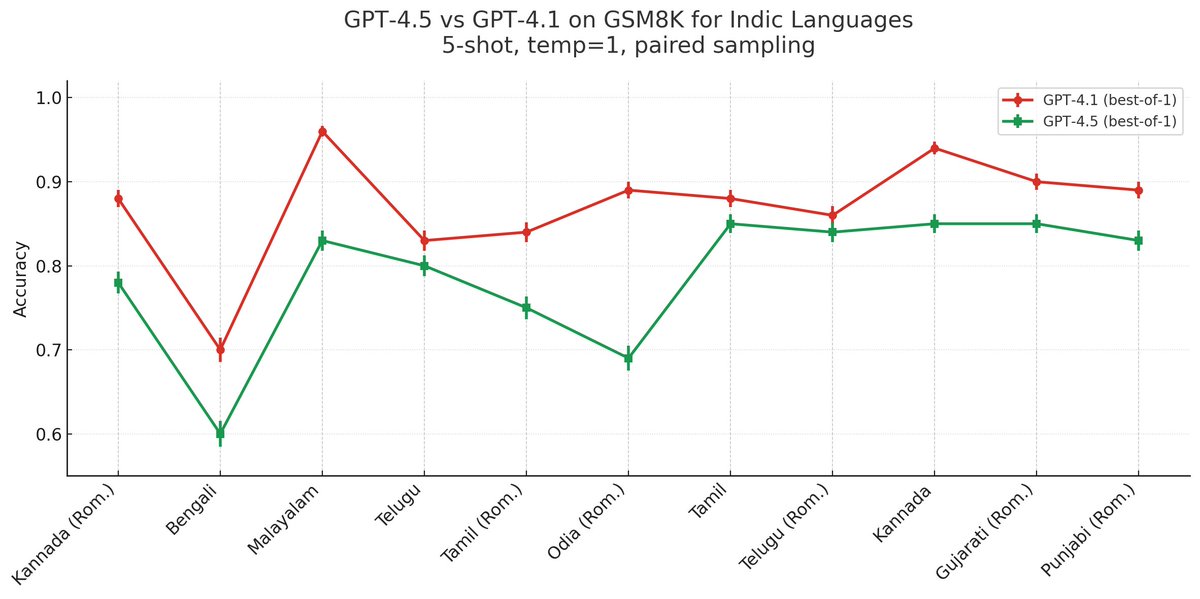
GPT 4.1 is as good as GPT 4.5 for English and Spanish. But for Indic Languages I see a whole letter grade difference in basic math. Questions like "If I have 4 eggs and eat 2 how many are left?" Does distillation come at the cost of multilingual performance?
In the olden days, pretraining via autoregressive decoding was considered a gruesome punishment.

We've been using uv a few months now and I've never felt better. I have more energy. My skin is clearer. My eye sight has improved.
Honored to win the robotics track! This was a lot of fun. The other talks were awesome from @physical_int @Waymo @Tesla_Optimus @GoogleDeepMind @nvidia @kscalelabs
Congrats to @aiDotEngineer 2025 Best Speakers! MCP: @zeeg Tiny Teams: @alxai_ LLM Recsys: @devanshtandon_ GraphRAG: @danielchalef Fortune 500 Day 1: @hwchase17 Architects Day 1: @denyslinkov Infra: @dylan522p Voice: @bnicholehopkins Product Management: @bbalfour Agent…
I spent a few hours today trying to reverse engineer Google's new Gemma 3n model which was published to HuggingFace as a compiled binary. I wanted to figure out how exactly they cram a model supposedly striking distance from Claude 3.7 Sonnet on LMArena into 2GB of RAM.
🧵 OpenRS-Star – Efficient RL Tuning for Reasoning Can reinforcement learning make small LLMs better reasoners — under tight compute budgets? We RL-tune Qwen3-1.7B for < $100 and achieve 50% on AIME24 (+13.3%). Code github.com/flores-o/openr… Model huggingface.co/oanaflores/Ope…
Did you hear about the new Gemini music model? It’s gotta be trained using Bach-propagation
Q: Why did the GPU bag travel to Indio? A: It wanted to train a CoacheLLM! @TristanHeywood



Despite calling our governments democracies, our societies don’t know how to productively harness this potent political force. Whoever does so first is destined to reshape governance in the 21st century.