Shengyang Sun
@ssydasheng
Build AGI @xAI | Prev. @NVIDIA (Leading Nemotron-340B) & @AMAZON | PhD @UofT ; B.E.@Tsinghua
While HLE marks @grok's general intelligence advancement, we at @xAI march towards solving Humanity's Last Exam problems in all specialized domains. That means building AI that surpasses human experts and solves the most challenging problems in each domain. Come join the xAI AI…
We are #hiring passionate engineers and researchers to join our mission of creating AI that surpasses human expertise in every domain! Ready to shape the future and build groundbreaking AGI? Apply now and be part of something extraordinary: job-boards.greenhouse.io/xai/jobs/48000…
Grok 4 is the first LLM that I've tested that has whatsoever reasonably calculated param counts from a JSON config of DeepSeek V3. It used a code tool but fair. I think o3[-pro] might also succeed, but this is impressive.
Grok 4 solves this simple prompt that most model get wrong. I am very happy today. I was frustrated why most model used to fail at this FLOP calculation. One of my suspicion is that Grok has been trained on lot of Twitter data as well and has seen me ranting about it many a…
Looking forward to what Grok can do next - pushing frontiers of science and engineering, making new discoveries!
Introducing Grok 4, the world's most powerful AI model. Watch the livestream now: x.com/i/broadcasts/1…
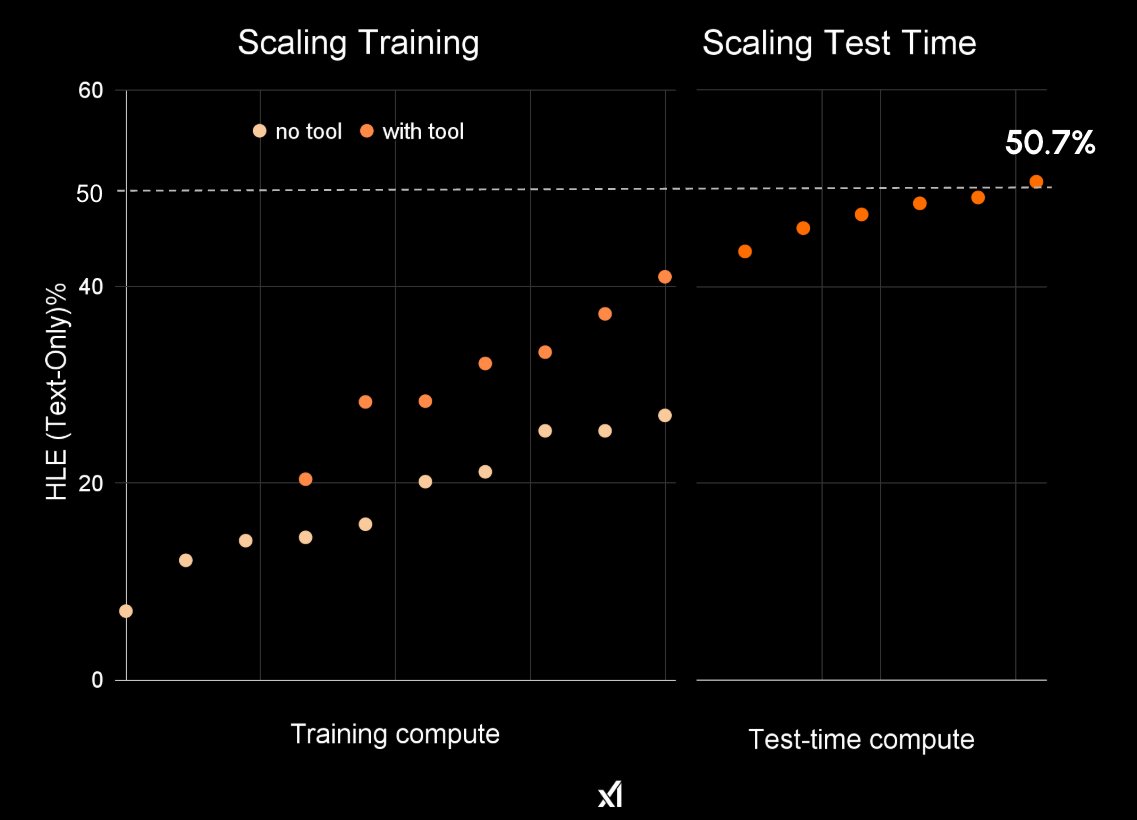
We built 200k-GPU clusters; We scaled up & curated higher-quality data; We scaled compute by 100x; We developed training & test-time recipes; We made everything RL native; We stabilized infrastructure and speeded up; That's how you turn RL into the pre-training scale. Yet I am…
If you are releasing sth called 3.5 and then change to 4, there is a reason. x.com/i/events/19427…
Stay tuned for Grok4.
The world is not ready for this model. We cracked and innovated so many recipes. Grok 4's intelligence will be unmatched🚀🚀. Unmatched. Remember we have a fraction of employees compared to other frontier labs. But one of us equal 10 researchers at other AI labs.
Definitely talk with Oleksii if you are interested. Oleksii is an excellent leader with paramount scientific rigor. The team is working on the best LLM post-training researchacross all domains.
If you are at #ICLR and looking for applied research roles in model post-training, reasoning and model alignment - message me and I’ll be happy to chat.
In case anyone still doesn't see the insane speed that models are getting smarter and cheaper: Yesterday, Google released Gemini 2.5 Flash, a very efficient reasoning model. Today, Grok 3 mini is stronger on most benchmarks for 7x cheaper! x.com/xai/status/191…
Let’s start with Grok 3 Mini. When we set out to build a fast, affordable mini model, we knew it would be good but even we didn’t expect it to be this good. Some highlights: - Grok 3 Mini tops the leaderboards on graduate-level STEM, math, and coding, outcompeting flagship…
(1) noticing the similarities between two distant domains is harder than logical distinction. And it enables the ultimate scientific invention potential. Think about how Einstein (and others) connects Riemannian geometry into physics and come up with General Relativity.…
On the topic "AI is trained on all of humanity, why can't it innovate?" New ideas come from two places: 1. Noticing similarities between two existing ideas (new ideas in one area translate into another) 2. Logical construction (new ideas follow from prior axioms) (1) is…
Check out our Llama-Nemotron-Nano/Super/Ultra, a testament to NVIDIA’s mission to become the AI Foundry and enable everyone to participate in the new AI era. •Open weights, open recipe, and open data •Reasoning on/off modes, tailored to your specific needs •From Nano to Ultra,…
We are excited to release Llama-Nemotron-Ultra! This is a reasoning ON/OFF, dense 253B model. Open weights and post-training data. huggingface.co/nvidia/Llama-3… We started with llama-405B, changed it via NAS pruning then followed by reasoning-focused post-training: SFT + RL in FP8.
Can LLMs actually solve hard math problems? Given the strong performance at AIME, we now go to the next tier: our MathArena team has conducted a detailed evaluation using the recent 2025 USA Math Olympiad. The results are… bad: all models scored less than 5%!
The next big learning would be At a 50% success rate, how long does it take a human labeller to judge the correctness of the model's response? More generally, how much human labelling time can get x (0 <= x <= 1) bits of information for a model's response? If you build…
When will AI systems be able to carry out long projects independently? In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
Data, training recipe, and models are all available!
We are excited to release new Llama-Nemotron models. These models allow you to set reasoning ON/OFF during runtime. We also release all the post-training data under CC-BY-4! Try it now on build.nvidia.com/nvidia/llama-3… HF collection: huggingface.co/collections/nv…
Three Forms of Technological Progress 1️⃣ Imitation: A breakthrough is fully shared in a paper—architecture, training data, hyperparameters. Others replicate, adapt, and build on it. Fast, open, and collaborative. 🔹 Examples: AlexNet (CNNs), AlphaGo (RL + MCTS), GPT-3 (scaling…
Evolution in three phases: 🧬 Biological (540M – 50K yrs ago): Slow genetic evolution for reproductive purposes, from single cells to Homo sapiens. 📚 Knowledge (50K yrs ago – 2000s): Language and books enable the reproductivity of knowledge, casuing its evolution in math,…
When the reward is 0 or 1, vanilla REINFORCE is just rejection sampling. Am I missing something? When we skip SFT and run RL only like in R1-zero, we are running SFT (over successful responses) only in this sense.