
Mislav Balunović
@mbalunovic
Researcher at @ETH_en and @insaitinstitute | AI for Math
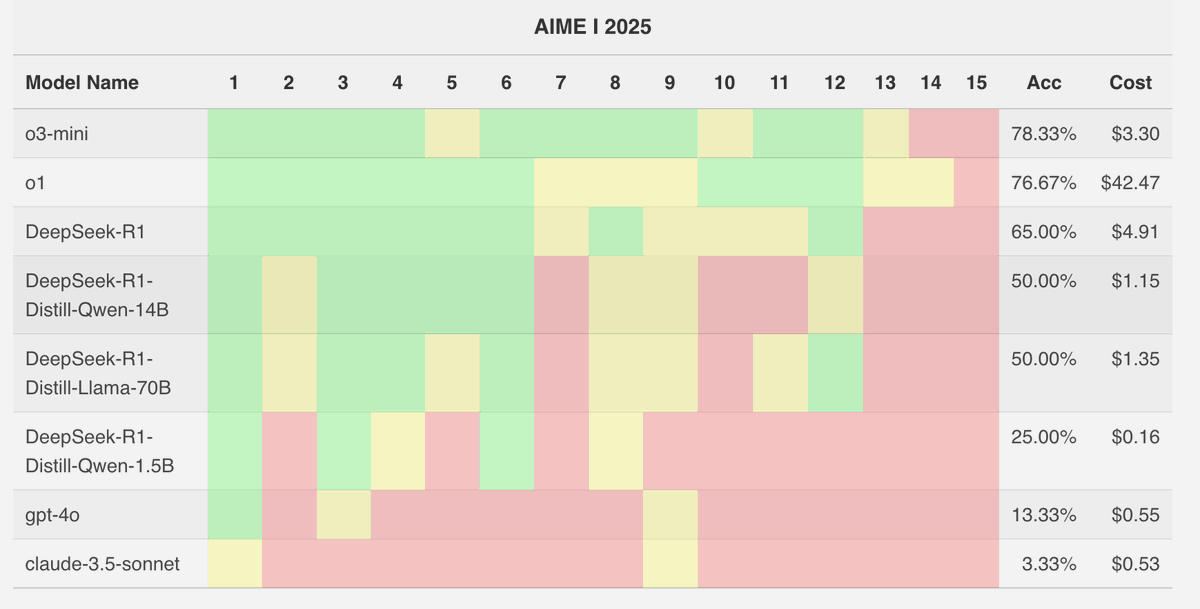
We finally have an answer to the debate over whether LLMs generalize to new math problems or they merely memorized the answers. We evaluated them on the AIME 2025 I competition from *yesterday* and the results are good!
Interesting approach! However, we looked at the proofs and methodology and we found a few problems, specifically with the use of hints given to the model. While the scaffold indeed improves performance, it does not solve all problems accurately and would not get a gold medal.🧵
🚨 Olympiad math + AI: We ran Google’s Gemini 2.5 Pro on the fresh IMO 2025 problems. With careful prompting and pipeline design, it solved 5 out of 6 — remarkable for tasks demanding deep insight and creativity. The model could win gold! 🥇 #AI #Math #LLMs #IMO2025
Amazing progress, congrats on the IMO gold medal - this one is verified by the IMO organizers!
Very excited to share that an advanced version of Gemini Deep Think is the first to have achieved gold-medal level in the International Mathematical Olympiad! 🏆, solving five out of six problems perfectly, as verified by the IMO organizers! It’s been a wild run to lead this…
Congrats, this is amazing achievement and huge progress compared to public models such as o3 (which stays below bronze medal)
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
The hardest high school math exam in the world, the 6 problem 9 hour IMO 2025, was this week. AI models performed poorly. Gemini 2.5 Pro scored the highest, just 13/42, costing $431.97, in a best of 32 eval. Bronze cutoff was 19. Long way to go for AI to solve hard Math.
MathArena evaluation of IMO 2025 is out! While the human tests are still being graded and medal cutoffs are unknown, it is unlikely that any public LLM, except potentially Gemini, will win a bronze medal. Still, it's a tremendous progress in this space.
We just released the evaluation of LLMs on the 2025 IMO on MathArena! Gemini scores best, but is still unlikely to achieve the bronze medal with its 31% score (13/42). 🧵(1/4)
Introducing FrontierMath Tier 4: a benchmark of extremely challenging research-level math problems, designed to test the limits of AI’s reasoning capabilities.
We've just released the largest open dataset of expert-annotated LLM proofs! Using this dataset, we did bunch of experiments: (i) RL to train better proof judges, (ii) comparing formal vs informal, (iii) inference-time methods for proof selection. Check out the results below
Thrilled to share a major step forward for AI for mathematical proof generation! We are releasing the Open Proof Corpus: the largest ever public collection of human-annotated LLM-generated math proofs, and a large-scale study over this dataset!
There's a lot of work now on LLM watermarking. But can we extend this to transformers trained for autoregressive image generation? Yes, but it's not straightforward 🧵(1/10)
Congrats to @GoogleDeepMind on an impressive USAMO score! Exciting to see our MathArena benchmarks being adopted by frontier labs for evaluating mathematical reasoning.
2.5 Pro Deep Think gets an impressive score on 2025 USAMO, currently one of the hardest math benchmarks. It also leads on LiveCodeBench, a difficult benchmark for competition-level coding, and scores 84.0% on MMMU, which tests multimodal reasoning. #GoogleIO