
Siyu Yuan
@siyu_yuan_
Ph.D. candidate at Fudan University. Ex-Research Intern at @MSFTResearch Asia and @BytedanceTalk AI Lab
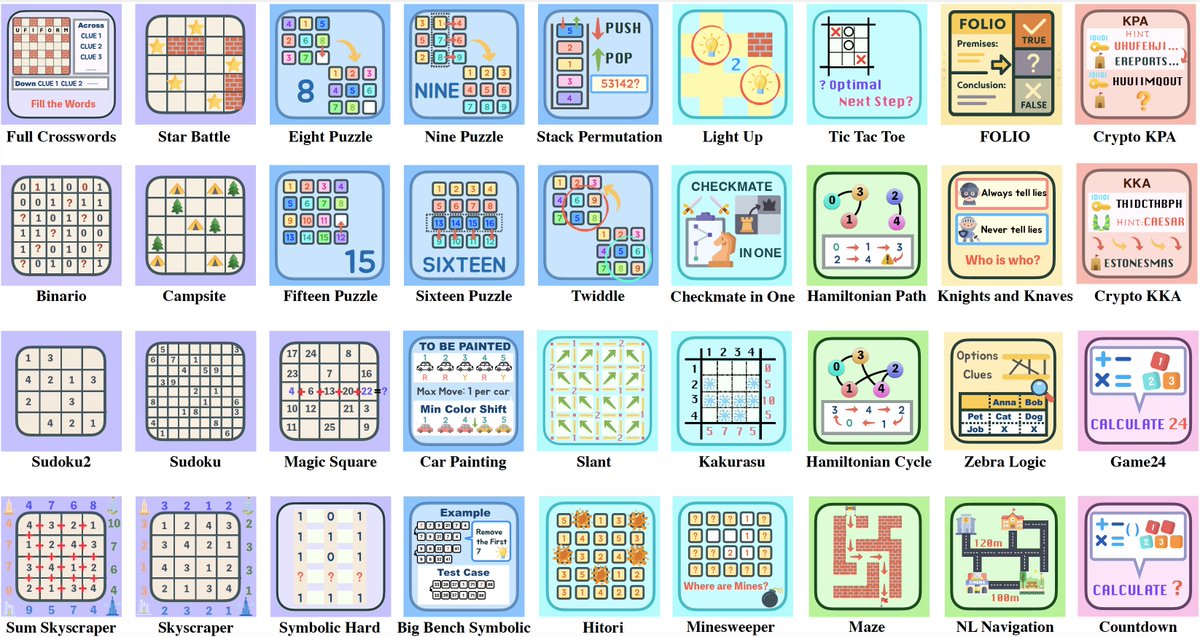
🎉 Introducing our latest work — Enigmata: A Full-Stack Recipe for Advancing Logical Reasoning in LLMs! Enigmata offers a complete pipeline from data generation → verification → RLVR training → evaluation, designed to systematically enhance the puzzle reasoning skills of LLMs.
🖥️ 2025已经过去一半了,盘点一下我这半年用得非常顺手的Mac工具: Cursor: 这个不必多说,AI时代程序员必备IDE,已经很长时间没有打开VSCode和PyCharm了。 Better Display: 27寸副屏默认显示太糊了, 打开Better Display的高分辨率(HiDPI)选项, 瞬间清晰了。效果堪比近视眼戴上眼镜。 Orbstack:…
+1 for "context engineering" over "prompt engineering". People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window…
I really like the term “context engineering” over prompt engineering. It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
What if an LLM could update its own weights? Meet SEAL🦭: a framework where LLMs generate their own training data (self-edits) to update their weights in response to new inputs. Self-editing is learned via RL, using the updated model’s downstream performance as reward.
📢 Introducing CoSER: Advancing AI Character Role-Playing with High-Quality Data from Best Books CoSER is a collection of a high-quality dataset, open models, and novel evaluation protocol for more authentic AI character role-playing! 📄Paper: arxiv.org/pdf/2502.09082 (1/3)
🚨This week's top AI/ML research papers: - Test-Time RL - PHYBench - Process Reward Models That Think - Tiny Reasoning Models via LoRA - Learning to Reason under Off-Policy Guidance - SplitReason - Learning Adaptive Parallel Reasoning with LMs - Token-Shuffle - Describe Anything…
Introducing Deep Research for arXiv Ask questions like 'What are the latest breakthroughs in RL fine-tuning?' and get comprehensive lit reviews with trending papers automatically included Turn hours of literature searches into seconds with AI-powered research context ⚡
Current LLM judges, fine-tuned using Supervised Fine-Tuning (SFT), perform poorly on evaluation tasks requiring deep reasoning. This paper introduces JudgeLRM, models trained using Reinforcement Learning (RL) with judge-specific rewards, enhancing reasoning for evaluation tasks;…
tremendous alpha right now in sending your wife photos of yall converted to studio ghibli anime
Thinking for longer (e.g. o1) is only one of many axes of test-time compute. In a new @Google_AI paper, we instead focus on scaling the search axis. By just randomly sampling 200x & self-verifying, Gemini 1.5 ➡️ o1 performance. The secret: self-verification is easier at scale!
🚨 NEW PAPER: "Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning"! 🤔 With all these long-reasoning LLMs, what are we actually optimizing for? Length penalties? Token budgets? We needed a better way to think about it! Website: cohenqu.github.io/mrt.github.io/ 🧵[1/9]
LLM Post-Training: A Deep Dive into Reasoning Large Language Models
I tested Grok 3 and DeepSeek v3 with same critical prompts. The results will blow your mind. Grok 3 Vs. DeepSeek v3 (Video demos are included)
Introducing #SIRIUS🌟: A self-improving multi-agent LLM framework that learns from successful interactions and refines failed trajectories, enhancing college-level reasoning and competitive negotiations. 📜Preprint: arxiv.org/pdf/2502.04780 💻code: github.com/zou-group/siri… 1/N
Thanks AK for sharing! 🤔How to endow language agents with self-correction capabilities for interactive environments?——📷Introducing Agent-R🔍, a novel framework designed to enable LLM-based agents to perform on-the-fly reflection and self-improvement 🎉.
Agent-R Training Language Model Agents to Reflect via Iterative Self-Training