
Jyo Pari
@jyo_pari
Trying to get models to continually learn | ML PhD student @MIT
What if an LLM could update its own weights? Meet SEAL🦭: a framework where LLMs generate their own training data (self-edits) to update their weights in response to new inputs. Self-editing is learned via RL, using the updated model’s downstream performance as reward.

If you are interested in questioning how we should pretrain models and create new architectures for general reasoning - then checkout E606 @ ICML, our position by @seungwookh and I on potential directions for the next generation reasoning models!
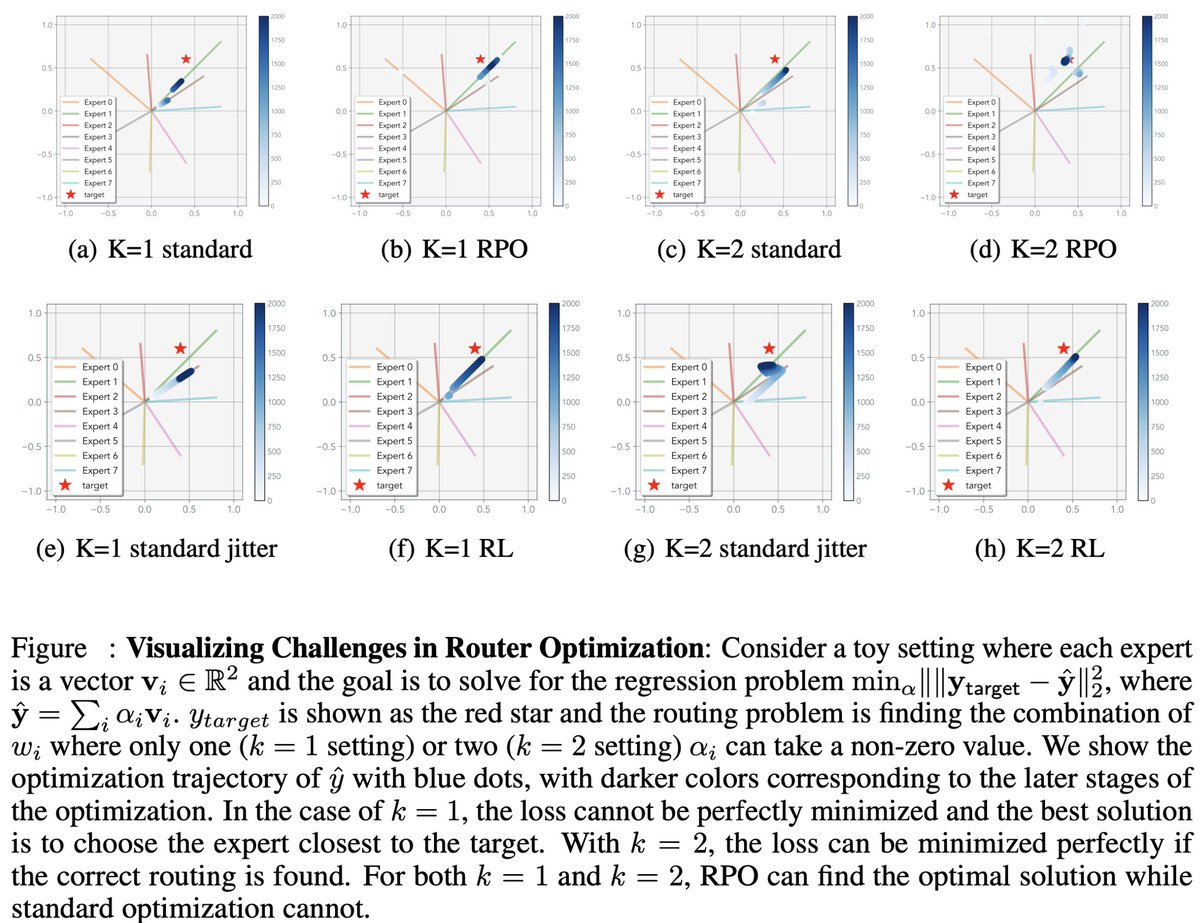
MoE Routers are trained a bit strangely but things seem to still work. @minyoung_huh and I got curious about combining specialized experts at test time through routing… and ended up deep in the weeds of MoE optimization. Here's a blog post! jyopari.github.io/posts/peculiar…
Current adaptive tokenizers still rely on humans to set the desired fidelity a priori. But what if the model could learn that itself? The part I like a lot about this paper beyond the high level idea is the way @ShivamDuggal4 trained for this ability. Cudos 🎇!
Compression is the heart of intelligence From Occam to Kolmogorov—shorter programs=smarter representations Meet KARL: Kolmogorov-Approximating Representation Learning. Given an image, token budget T & target quality 𝜖 —KARL finds the smallest t≤T to reconstruct it within 𝜖🧵
Thanks @willknight for covering SEAL! Really appreciate the thoughtful and insightful way you captured the work.
Scientists at Massachusetts Institute of Technology have devised a way for large language models to keep learning on the fly—a step toward building AI that continually improves itself. wired.com/story/this-ai-…
An underrated and potentially more practical aspect of our Self-Adapting LMs paper is the potential for general pre/post-training data curation. In the paper, we focus on using the same model for both generating and learning from self-edits. In practice, I imagine a "teacher"…
There are three types of storage: activations (in-context), external memory, and model weights. If the models will spend days for a task, then they should be really good at compiling their in-context work to ab external memory or to their weights! Here we try to learn weights…
What if an LLM could update its own weights? Meet SEAL🦭: a framework where LLMs generate their own training data (self-edits) to update their weights in response to new inputs. Self-editing is learned via RL, using the updated model’s downstream performance as reward.
it really is incredible what kinds of things become possible when RL on LLMs works. clearly we’re just getting started
What if an LLM could update its own weights? Meet SEAL🦭: a framework where LLMs generate their own training data (self-edits) to update their weights in response to new inputs. Self-editing is learned via RL, using the updated model’s downstream performance as reward.
There is linear attention, quadratic attention, but what about something in the middle? Do we really need to attend to all tokens or can we exploit a recency bias? Check out this very inspiring work by Han!
We know Attention and its linear-time variants, such as linear attention and State Space Models. But what lies in between? Introducing Log-Linear Attention with: - Log-linear time training - Log-time inference (in both time and memory) - Hardware-efficient Triton kernels