
Siyan Zhao
@siyan_zhao
CS PhD student @UCLA | Bachelors @UofT EngSci | LLMs, generative models, decision-making
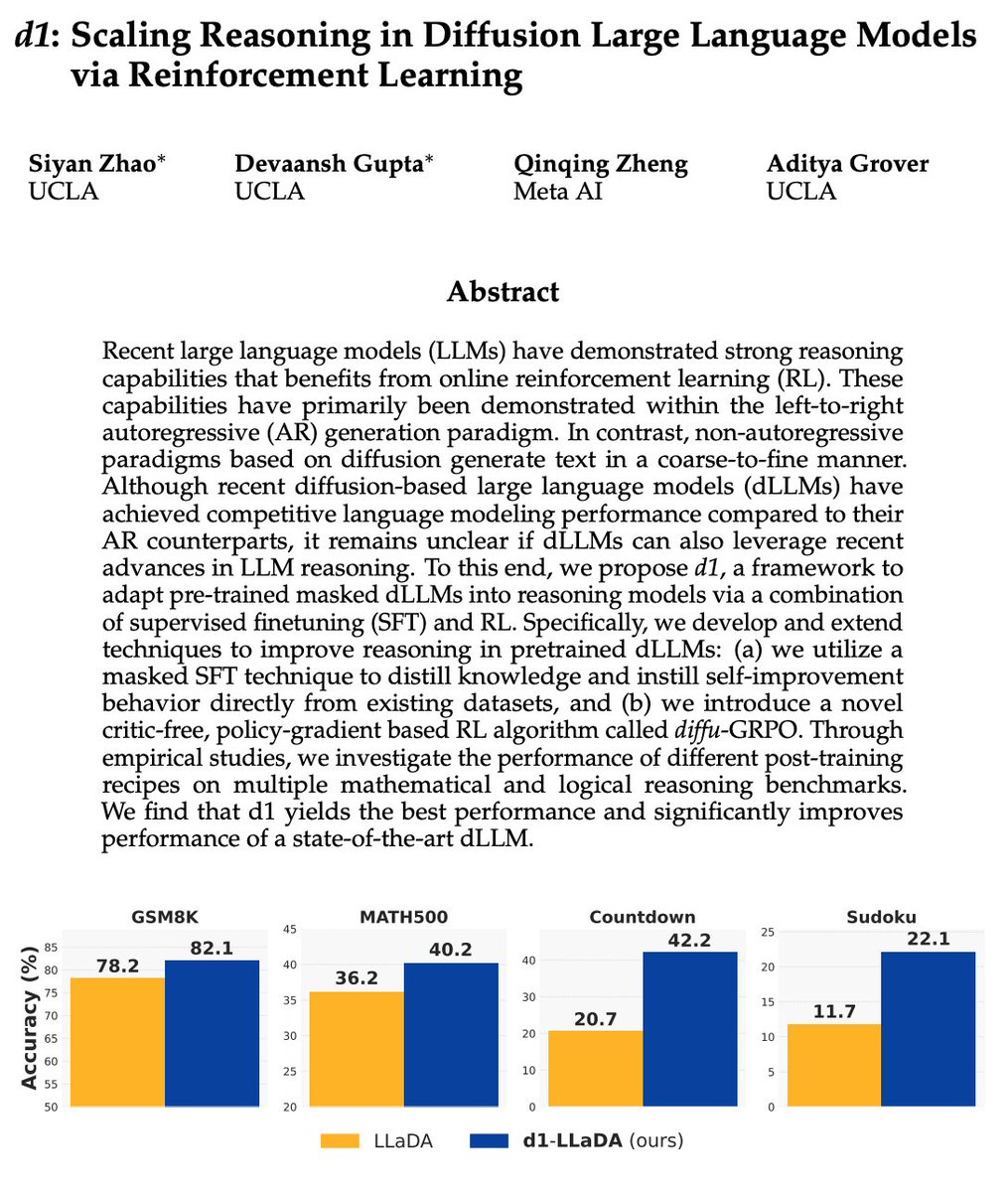
Introducing d1🚀 — the first framework that applies reinforcement learning to improve reasoning in masked diffusion LLMs (dLLMs). Combining masked SFT with a novel form of policy gradient algorithm, d1 significantly boosts the performance of pretrained dLLMs like LLaDA.
Since our launch earlier this year, we are thrilled to witness the growing community around dLLMs. The Mercury tech report from @InceptionAILabs is now on @arxiv with more extensive evaluations: arxiv.org/abs/2506.17298 New model updates dropping later this week!
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
🚀 Introducing PhysiX: One of the first large-scale foundation models for physics simulations! PhysiX is a 4.5B parameter model that unifies a wide range of physical systems, from fluid dynamics to reaction-diffusion, outperforming specialized, state-of-the-art models.
🤖Can diffusion models write code competitively? Excited to share our latest 7B coding diffusion LLM!!💻 With DiffuCoder, we explore how they decode, why temperature🔥 matters, and how to improve them via coupled-GRPO that speaks diffusion!!📈 Code: github.com/apple/ml-diffu… 🧵
(1/6)Our work Reflect-DiT was accepted to #ICCV2025 ! Reflect-DiT allows the model to reflect on its past generations and textual feedback to self-correct and improve, extending reasoning to text-to-image generation.
🚀 Super excited to share Multiverse! 🏃 It’s been a long journey exploring the space between model design and hardware efficiency. What excites me most is realizing that, beyond optimizing existing models, we can discover better model architectures by embracing system-level…
🔥 We introduce Multiverse, a new generative modeling framework for adaptive and lossless parallel generation. 🚀 Multiverse is the first open-source non-AR model to achieve AIME24 and AIME25 scores of 54% and 46% 🌐 Website: multiverse4fm.github.io 🧵 1/n
🧑🍳Very excited to present LaViDa, one of the first diffusion language models for multimodal understanding! 🌟Unlike autoregressive LMs, you can control the speed-quality tradeoff, and solve constrained generation problems out of the box 📦 🌟 We also release LaViDa-Reason, a…
📢(1/11)Diffusion LMs are fast and controllable at inference time! But why restrict such benefits for processing text data? We are excited to announce LaViDa, one of the first and fastest large diffusion LM for vision-language understanding!!
📢(1/11)Diffusion LMs are fast and controllable at inference time! But why restrict such benefits for processing text data? We are excited to announce LaViDa, one of the first and fastest large diffusion LM for vision-language understanding!!
We are kicking off a series of seminars at @hkunlp2020. @siyan_zhao will be giving a talk titled "d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning" at ⏰Friday 5.9 11am HKT (Thursday 5.8 8pm PDT). Link to talk: hku.zoom.us/j/97925412724?…
🔬 Checkout our newest #ICML’25 spotlight paper GREAT, which revolutionizes GraphODEs with better generalization through smart disentanglement & causal reasoning. This also marks the final piece of GraphODE series work during my PhD journey :) From model , data, to applications!
A nice and clean implementation based on huggingface TRL!
Our Diffu-GRPO and evaluation code is now released! Check it out at github.com/dllm-reasoning…
Our Diffu-GRPO and evaluation code is now released! Check it out at github.com/dllm-reasoning…
Introducing d1🚀 — the first framework that applies reinforcement learning to improve reasoning in masked diffusion LLMs (dLLMs). Combining masked SFT with a novel form of policy gradient algorithm, d1 significantly boosts the performance of pretrained dLLMs like LLaDA.
Thank you @VentureBeat for covering our research on enhancing reasoning with diffusion LLMs using d1. Great collaboration with @siyan_zhao , @DevaanshGupta1 and @qqyuzu .
30 seconds vs. 3: The d1 reasoning framework that's slashing AI response times venturebeat.com/ai/30-seconds-…
✈️ I will be at @iclr_conf 🇸🇬 to present the following work on LLM reasoning, vision-language understanding, and LLM evaluation w/ @uclanlp, UCLA Machine Intelligence (MINT), and @GoogleDeepMind! Come to the poster sessions and say hi 👋 I will be happy to meet folks from…
Attending #ICLR2025 from 4/23 to 4/28 & will present PrefEval (prefeval.github.io) discussing the performance of SoTA LLMs on personalization. Catch our presentations on April 26th: 🔥Oral: 10:42-10:54am @ Hall 1 Apex 📊 Poster #558: 3:00-5:30pm @ Hall 3 + Hall 2B…
Large language models (LLMs) have been explored for optimization via prompting to evaluate or improve candidate solutions. However, this approach does not generalize to domains that are either under-represented during pretraining or inefficient to translate as text. Our #ICLR2025…
📅Saturday Night Paper Discussion📅 Join us tonight to talk about d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning 6pm UTC on Discord, no prior knowledge required: discord.gg/ec2FXBFA?event…
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning "we propose d1, a framework to adapt pre-trained masked dLLMs into reasoning models via a combination of supervised finetuning (SFT) and RL." "we introduce a novel critic-free, policy-gradient…