Mihir Prabhudesai
@mihirp98
PhD @ Carnegie Mellon | Research Intern @ Google
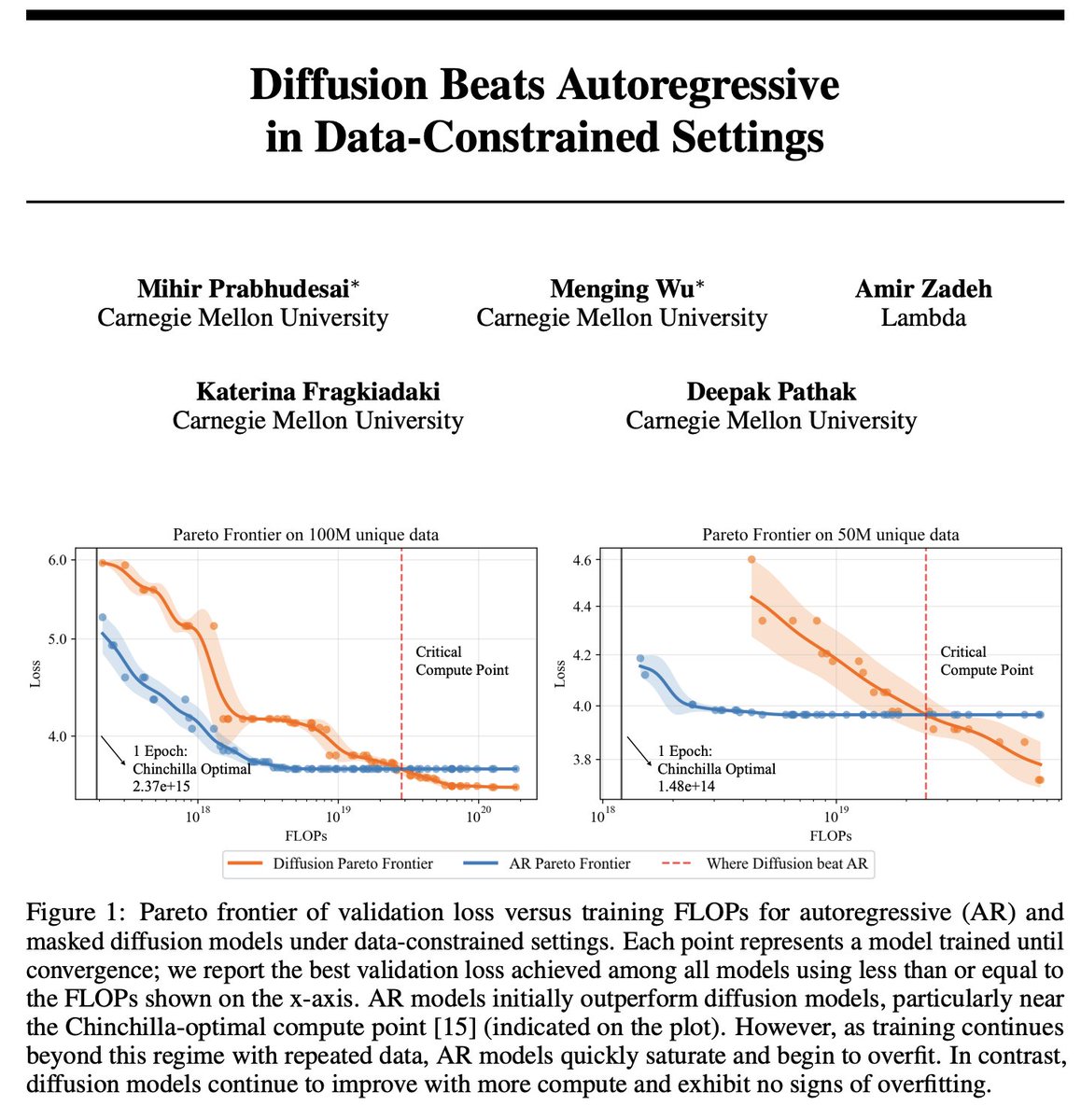
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
This looks pretty amazing work, especially the data repetition plots.
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Great work from Mihir with lots of nice insights in the thread!
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Very nice results here, we've seen similar ability of diffusion models to benefit from repeated data, more so than AR models. The diffusion loss is much noisier so might act as a natural regularizer to prevent overfitting.
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Interesting results and easy to follow thread for TLDR.
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
I re-investigate the lr, it seems that 2e-4 is pretty safe for your model family because they are much smaller than the NeurIPS 2023 paper or Chinchilla. It's just a bit conservative lol. anyway 3.55 vs. 3.71 is pretty significant so I guess optimal HPs won't change it.
very impactful work, it tells us the cross-over DOES exist. big for our community.
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Really interesting paper and insight to how the language models might progress if we approach bottlenecks in scaling laws
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
We had some early evidence of this when over-training MDLM baselines in the original paper, but we didn't have time to explore it then. Glad to see discrete diffusion scales up so well in data constrained settings!
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Great to see this tribal knowledge on more solid ground! We’ve seen this in several settings and I expect this to inform what we (in the general sense) choose to scale!
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Exciting analysis on diffusion vs. auto-regressive modeling, with a surprisingly clean takeaway! Hope to see similar analyses in more sequential-decision-making-y / robotics-y problems.
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Really interesting paper. Fits the theme that we should make our modeling problems harder, not easier, so that they are forced to learn more and generalize better.
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
was actually wondering with @hyundongleee the fundamental differences between diffusion and autoregressive modeling other than the structure imposed in the modeling of the sequential conditional distribution and how they manifest. a poignant paper that addresses this thought
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Thrilled to finally release this study! 🚀 We view (discrete) diffusion models as implicitly doing data augmentation over autoregressive. Through this lens, we find that diffusion outperforms AR in data-constrained settings, but it requires larger models and way more epochs to…
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Excellent insights on when to use autoregressive vs diffusion models
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Great research work. The thread is a gold mine for anyone interested in understanding diffusion language modelling and how it fares with AR models!
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Great work from great people! @mihirp98 @pathak2206 AR aligns w/ compression theory (KC, MDL, arithmetic coding), but diffusion is MLE too. Can we interpret diffusion similarly? Curious how compression explains AR vs. diffusion scaling laws. (Ilya’s talk touches on this too.)
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n
Excited to share this project! Model keeps growing, but data doesn’t. So we ask: is there a more data-efficient way to achieve great performance? Diffusion is our answer for the first step of exploration.
🚨 The era of infinite internet data is ending, So we ask: 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck? TL;DR: ▶️Compute-constrained? Train Autoregressive models ▶️Data-constrained? Train Diffusion models Get ready for 🤿 1/n