
Charlie Snell
@sea_snell
PhD student @berkeley_ai; research @cursor_ai; prev @GoogleDeepMind. My friend told me to tweet more. I stare at my computer a lot and make things
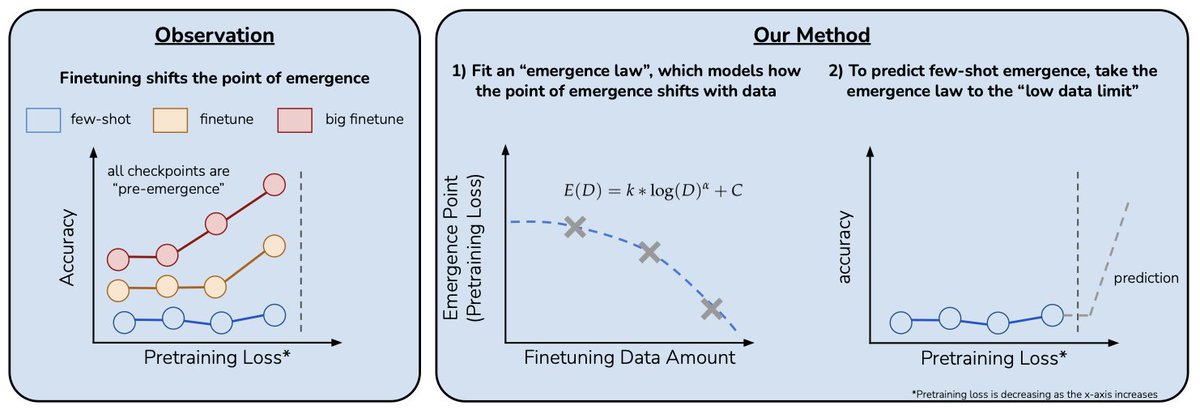
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task? We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
🚨Beyond 80/20 in LLM reasoning🚨Dropping 80% low-entropy tokens in RL greatly boosts performance 🔗arxiv.org/abs/2506.01939 🏆Zero-RL SoTA: 63.5/68.1 (AIME24), 56.7 (AIME25) 🚀Insights: 1. RL retains base model entropy patterns 2. High-entropy tokens drive all RL improvement ⬇️
Proud to introduce Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant RL algorithm that powers the large-scale RL training of the latest Qwen3 models (Instruct, Coder, Thinking) 🚀 📄 huggingface.co/papers/2507.18…
pretraining is an elegant science, done by mathematicians who sit in cold rooms writing optimization theory on blackboards, engineers with total absorb of distributed systems of titanic scale posttraining is hair raising cowboy research where people drinking a lot of diet coke…
In the past month, Cursor found 1M+ bugs in human-written PRs. Over half were real logic issues that were fixed before merging. Today, we're releasing the system that spotted these bugs. It's already become a required pre-merge check for many teams.
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
YOLOing the ice cream at Salt and Straw (no taste test) was a mistake
incredible that this was written before the advent of vibe coding, just lmao
Introducing e3 🔥 Best <2B model on math 💪 Are LLMs implementing algos ⚒️ OR is thinking an illusion 🎩.? Is RL only sharpening the base LLM distrib. 🤔 OR discovering novel strategies outside base LLM 💡? We answer these ⤵️ 🚨 arxiv.org/abs/2506.09026 🚨 matthewyryang.github.io/e3/
RL is very inference heavy and shifts infrastructure build outs heavily Scaling well engineered environments is difficult Reward hacking and non verifiable rewards are key areas of research Recursive self improvement already playing out Major shift in o4 and o5 RL training
Scaling Reinforcement Learning Environments, Reward Hacking, Agents, Scaling Data Infrastructure Bottlenecks and Changes Distillation Data is a Moat Recursive Self Improvement o4 and o5 RL Training China Accelerator Production semianalysis.com/2025/06/08/sca…
Cursor 1.0 is out now! Cursor can now review your code, remember its mistakes, and work on dozens of tasks in the background.




Really enjoyed this conversation! A good look into how we're training frontier models at Cursor
A conversation on the optimal reward for coding agents, infinite context models, and real-time RL