Ryan Marten
@ryanmart3n
@bespokelabsai previously @UofIllinois @allen_ai @UofT
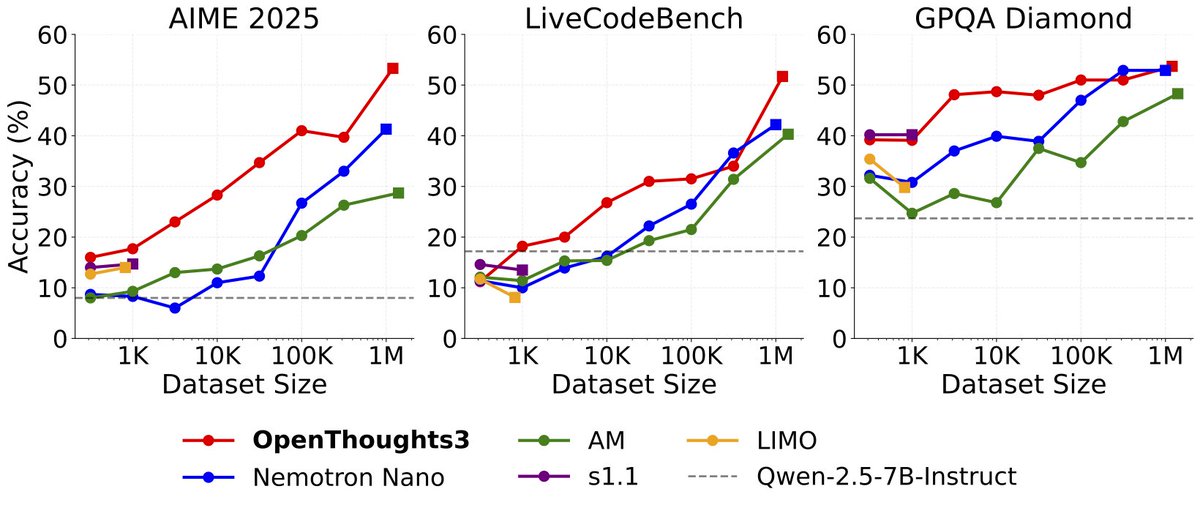
Announcing OpenThinker3-7B, the new SOTA open-data 7B reasoning model: improving over DeepSeek-R1-Distill-Qwen-7B by 33% on average over code, science, and math evals. We also release our dataset, OpenThoughts3-1.2M, which is the best open reasoning dataset across all data…
Really excited to see Andy and team launch Laude. This is a phenomenal initiative to get resources to researchers doing impactful work which will push humanity forwards. I’ve gotten to know the Laude team and hear about their mission over the last couple months - I’m extremely…
Today, I’m launching a deeply personal project. I’m betting $100M that we can help computer scientists create more upside impact for humanity. Built for and by researchers, including @JeffDean & @jpineau1 on the board, @LaudeInstitute catalyzes research with real-world impact.
Evaluating agents on benchmarks is a pain. Each benchmark comes with its own harness, scoring scripts, and environments and integrating can take days. We're introducing the Terminal-Bench dataset registry to solve this problem. Think of it as the npm of agent benchmarks. Now…
We at @NovaSkyAI have been hacking on RL across the stack—algorithms, envs, perf optimization. But progress is slowed by RL frameworks with tightly-coupled components that lack interfaces. To fill this gap, we upgraded SkyRL into a highly-modular RL framework. Check it out!!
✨Release: We upgraded SkyRL into a highly-modular, performant RL framework for training LLMs. We prioritized modularity—easily prototype new algorithms, environments, and training logic with minimal overhead. 🧵👇 Blog: novasky-ai.notion.site/skyrl-v01 Code: github.com/NovaSky-AI/Sky…
it turns out that "more-is-more" for reasoning great work on OpenThinker3-7B by @ryanmart3n and team! lots of gems in the paper.
As part of the OpenThoughts3 effort, we trained and evaluated over 1000 models. @MercatJean has done a fantastic analysis using the database of evals from these experiments.
We evaluated more than 1000 reasoning LLMs on 12 reasoning-focused benchmarks and made fascinating observations about cross-benchmark comparisons. You can explore all that data yourself on our HuggingFace spaces page. (1/4)

Honored to win for the RL track, was a great track overall. I really enjoyed spending the day there with @willccbb @ryanmart3n @danielhanchen @GregKamradt and many others. YouTube link below.
Congrats to @aiDotEngineer 2025 Best Speakers! MCP: @zeeg Tiny Teams: @alxai_ LLM Recsys: @devanshtandon_ GraphRAG: @danielchalef Fortune 500 Day 1: @hwchase17 Architects Day 1: @denyslinkov Infra: @dylan522p Voice: @bnicholehopkins Product Management: @bbalfour Agent…
OpenThoughts3 is the #1 trending dataset on Huggingface! Thank you to everyone who is using the dataset and giving us great feedback 🚀!