
Mohsen Fayyaz
@mohsen_fayyaz
PhD Student @ UCLA #NLProc #MachineLearning
Now accepted to #ACL2025 main conference! 🎉
new paper! 🌱 Collapse of Dense Retrievers We uncover major vulnerabilities in dense retrievers like Contriever, showing they favor: 📌 Shorter docs 📌 Early positions 📌 Repeated entities 📌 Literal matches ...all while ignoring the answer's presence! huggingface.co/datasets/mohse…
@mohsen_fayyaz's recent work showed several critical issues of dense retrievers favoring spurious correlations over knowledge, which makes RAG particularly vulnerable to adversarial examples. Check out more details 👇
Now accepted to #ACL2025 main conference! 🎉
Dense retrieval models in Retrieval Augmented Generation systems often prioritize superficial document features, overlooking actual answer relevance. This inefficiency arises from biases in retrievers. This paper addresses this by using controlled experiments based on Re-DocRED…
Excited to share MRAG-Bench is accepted at #ICLR2025 🇸🇬. The image corpus is a rich source of information, and extracting knowledge from it can often be more advantageous than from a text corpus. We study how MLLMs can utilize vision-centric multimodal knowledge. More in our…
🚀Introducing MRAG-Bench: How do Large Vision-Language Models utilize vision-centric multimodal knowledge? 🤔Previous multimodal knowledge QA benchmarks can mainly be solved by retrieving text knowledge.💥We focus on scenarios where retrieving knowledge from image corpus is more…
🚀Introducing MRAG-Bench: How do Large Vision-Language Models utilize vision-centric multimodal knowledge? 🤔Previous multimodal knowledge QA benchmarks can mainly be solved by retrieving text knowledge.💥We focus on scenarios where retrieving knowledge from image corpus is more…
Spent a fantastic weekend at Lake Arrowhead with the @uclanlp group! ❄️🏔️⬆️ Enjoyed scenic drives, delicious meals, engaging conversations, and brainstorming sessions. Truly inspiring! 🚗🥘😋💬 🖼️🧠💡
Check out our (w/ @mohsen_fayyaz, @AghazadeehEhsan, @yyaghoobzadeh & @tpilehvar) #ACL2023 paper “DecompX: Explaining Transformers Decisions by Propagating Token Decomposition” 📽️ Video, 💻 Code, Demo & 📄 Paper: github.com/mohsenfayyaz/D… arxiv.org/abs/2306.02873 (🧵1/4)
🎉I‘m delighted to announce that our (w/ @mohsen_fayyaz, @AghazadeehEhsan, @yyaghoobzadeh & @tpilehvar) paper “DecompX: Explaining Transformers Decisions by Propagating Token Decomposition” has been accepted to the #ACL2023 🥳🥳 Preprint coming soon📄⏳
#ACL2022 Excited to share our latest work on "Metaphors in Pre-Trained Language Models" at @aclmeeting. 📝Paper: aclanthology.org/2022.acl-long.… 🎬Video: youtube.com/watch?v=UKWFZS… with @aghazadeh_ehsan @yyaghoobzadeh #acl2022nlp
🚀Introducing MRAG-Bench: How do Large Vision-Language Models utilize vision-centric multimodal knowledge? 🤔Previous multimodal knowledge QA benchmarks can mainly be solved by retrieving text knowledge.💥We focus on scenarios where retrieving knowledge from image corpus is more…
#EMNLP2021 Presenting "Not All Models Localize Linguistic Knowledge in the Same Place" BlackboxNLP poster session 3 (Gather.town) Nov 11 14:45 Punta Cana (UTC-4) 📝Paper: aclanthology.org/2021.blackboxn… with @AghazadeEhsan @AModarressi @hmohebbi75 @tpilehvar #BlackboxNLP
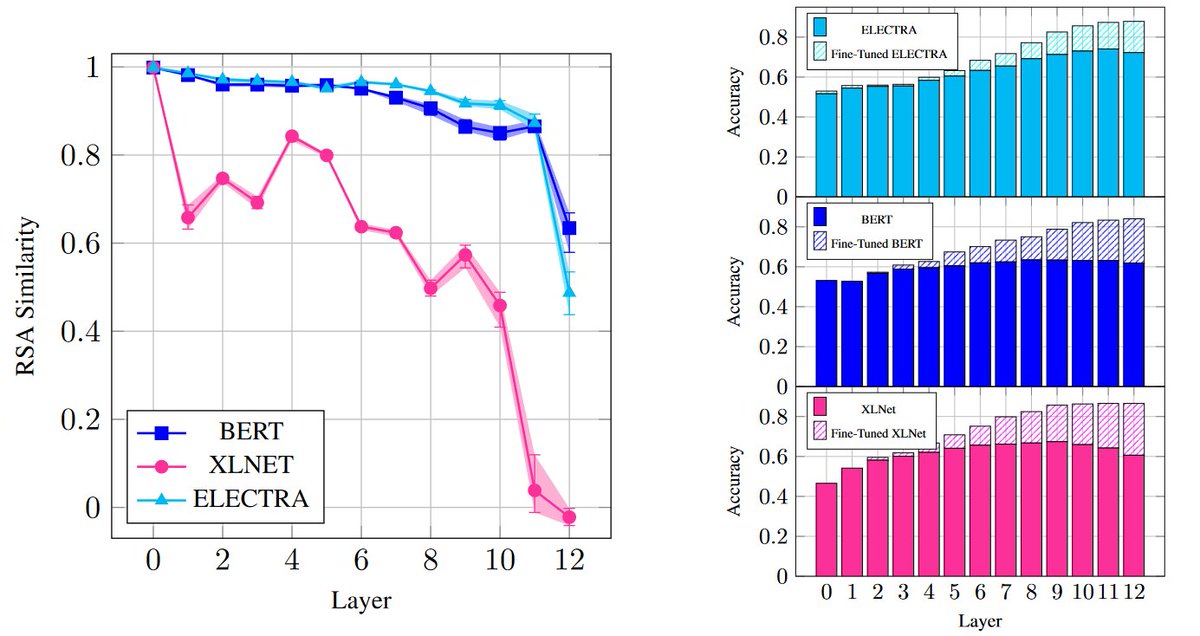
Student interns at TeIAS, M. Fayyaz, and E. Aghazadeh, had a paper accepted at EMNLP 2021 (BlackboxNLP), with H. Mohebbi, A Modaresi, and M. T. Pilehvar. The paper reports an in-depth analysis of the distribution of encoded knowledge across layers in BERToid representations.