
Michael Hu
@michahu8
NLP, training data, RL | PhD @NYU | multi-agent collaboration 🤖🤝🤖 @Microsoft | @NSF GRFP fellow | prev @princeton_nlp, @cocosci_lab.
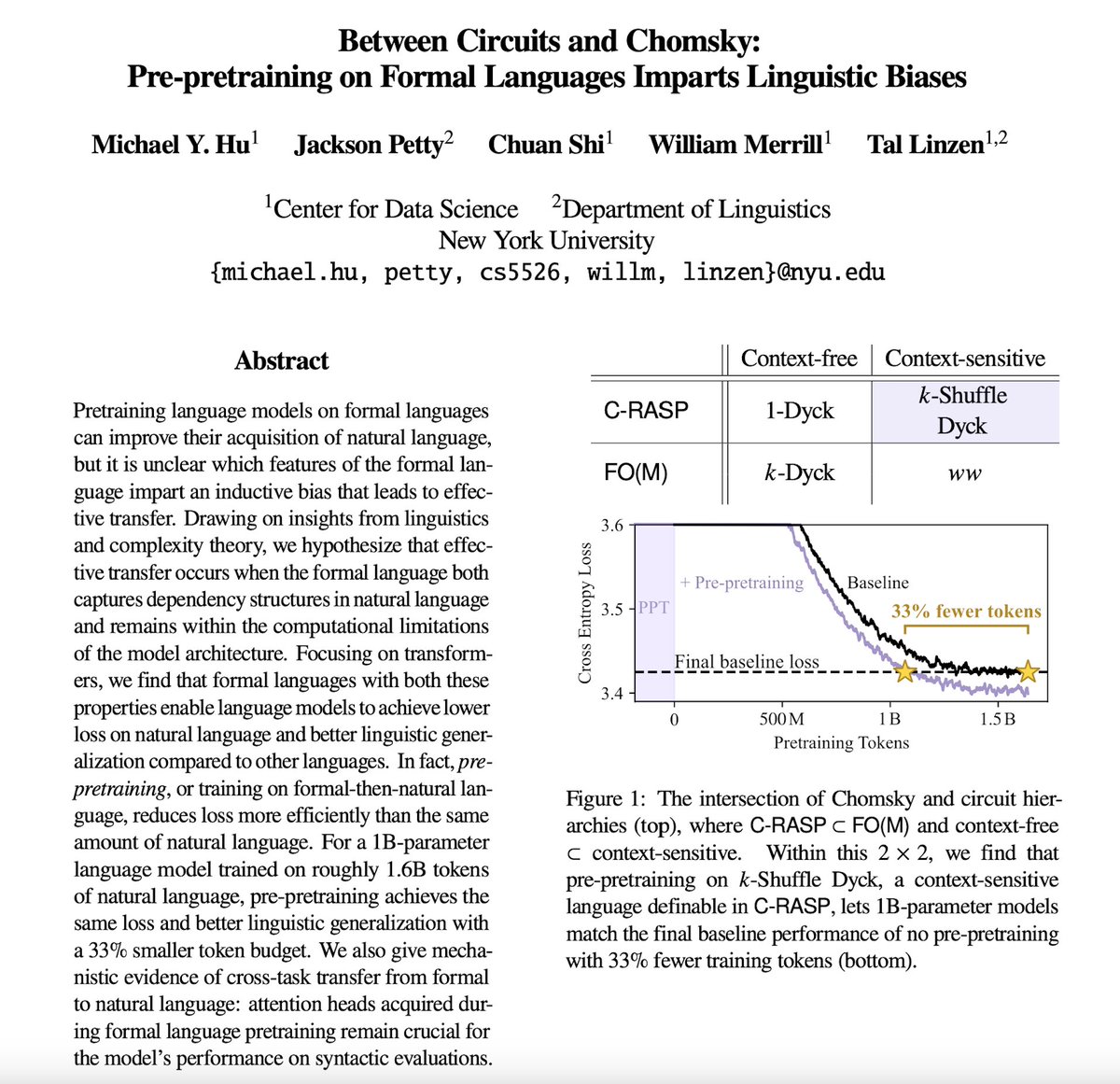
Training on a little 🤏 formal language BEFORE natural language can make pretraining more efficient! How and why does this work? The answer lies…Between Circuits and Chomsky. 🧵1/6👇
aka the HATER track 😍
New position paper! Machine Learning Conferences Should Establish a “Refutations and Critiques” Track Joint w/ @sanmikoyejo @JoshuaK92829 @yegordb @bremen79 @koustuvsinha @in4dmatics @JesseDodge @suchenzang @BrandoHablando @MGerstgrasser @is_h_a @ObbadElyas 1/6
RL can certainly teach LLMs new skills in principle, but in practice token-level exploration is so challenging that we end up relying on pretraining and synthetic data. the era of experience implies the era of exploration
A mental model I find useful: all data acquisition (web scrapes, synthetic data, RL rollouts, etc.) is really an exploration problem 🔍. This perspective has some interesting implications for where AI is heading. Wrote down some thoughts: yidingjiang.github.io/blog/post/expl…
how LLMs solve a task can change as the task gets harder! we analyzed this phenomenon here in a crisp, controlled setting with formal languages
How well can LLMs understand tasks with complex sets of instructions? We investigate through the lens of RELIC: REcognizing (formal) Languages In-Context, finding a significant overhang between what LLMs are able to do theoretically and how well they put this into practice.
Accepted to ACL! See you in Vienna 🫡 code: github.com/michahu/pre-pr… arxiv: arxiv.org/abs/2502.19249
Training on a little 🤏 formal language BEFORE natural language can make pretraining more efficient! How and why does this work? The answer lies…Between Circuits and Chomsky. 🧵1/6👇
hot multi agent researcher summer
hot interpretability researcher summer
Reinforcement learning has been posited as a solution to data issues when training everything from general-purpose reasoning models like Deepseek R1, to humanoid robots like Optimus and Unitree G1. But when is it useful? What makes a problem suitable for RL? I think it's…
!!! I'm at #ICLR2025 to present 🧄Aioli🧄 a unified framework for data mixing on Thursday afternoon! 🔗 arxiv.org/abs/2411.05735 Message me to chat about pre/post training data (mixing, curriculum, understanding); test-time compute/verification; or to try new food 🇸🇬
it is my great honour to be appointed as the Glen se Vries Professor of Health Statistics. i have quickly written about this in my blog post: kyunghyuncho.me/glen-de-vries-…
Kyunghyun Cho (@kchonyc), Professor of Computer Science and Data Science, has been named recipient of the Glen de Vries Chair for Health Statistics by the Courant Institute and New York University. Congratulations!