Maximilian Beck
@maxmbeck
ELLIS PhD Student @ JKU Linz Institute for Machine Learning & PhD Researcher @nx_ai_com, Research Scientist Intern @Meta FAIR
Yesterday, we shared the details on our xLSTM 7B architecture. Now, let's go one level deeper🧑🔧 We introduce ⚡️Tiled Flash Linear Attention (TFLA), ⚡️ A new kernel algorithm for the mLSTM and other Linear Attention variants with Gating. We find TFLA is really fast! 🧵(1/11)

NXAI has successfully demonstrated that their groundbreaking xLSTM (Long Short Term Memory) architecture achieves exceptional performance on AMD Instinct™ GPUs - significant advancement in RNN technology for edge computing applications. amd.com/en/blogs/2025/…
Ever wondered how 'Composition over Inheritance' can be used efficiently in ML Experiment Configuration (and beyond)? Check out the CompoConf library: Enabling type-safe compositional configuration in Python. korbi.ai/blog/compoconf Based on ideas by @maxmbeck (and a bit of mine)
MesaNet is beautiful! A great paper with extensive benchmark of recent RNNs (including xLSTM) on synthetic tasks and language modeling
Super happy and proud to share our novel scalable RNN model - the MesaNet! This work builds upon beautiful ideas of 𝗹𝗼𝗰𝗮𝗹𝗹𝘆 𝗼𝗽𝘁𝗶𝗺𝗮𝗹 𝘁𝗲𝘀𝘁-𝘁𝗶𝗺𝗲 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 (TTT), and combines ideas of in-context learning, test-time training and mesa-optimization.
Ever wondered how linear RNNs like #mLSTM (#xLSTM) or #Mamba can be extended to multiple dimensions? Check out "pLSTM: parallelizable Linear Source Transition Mark networks". #pLSTM works on sequences, images, (directed acyclic) graphs. Paper link: arxiv.org/abs/2506.11997
Mein Buch “Was kann Künstliche Intelligenz?“ ist erschienen. Eine leicht zugängliche Einführung in das Thema Künstliche Intelligenz. LeserInnen – auch ohne technischen Hintergrund – wird erklärt, was KI eigentlich ist, welche Potenziale sie birgt und welche Auswirkungen sie hat.
We’re excited to introduce TiRex — a pre-trained time series forecasting model based on an xLSTM architecture.
📢 (1/16) Introducing PaTH 🛣️ — a RoPE-free contextualized position encoding scheme, built for stronger state tracking, better extrapolation, and hardware-efficient training. PaTH outperforms RoPE across short and long language modeling benchmarks arxiv.org/abs/2505.16381
Excited to share that 2 of our papers on efficient inference with #xLSTM are accepted at #ICML25. A Large Recurrent Action Model: xLSTM enables Fast Inference for Robotics Tasks (arxiv.org/abs/2410.22391) and xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference:
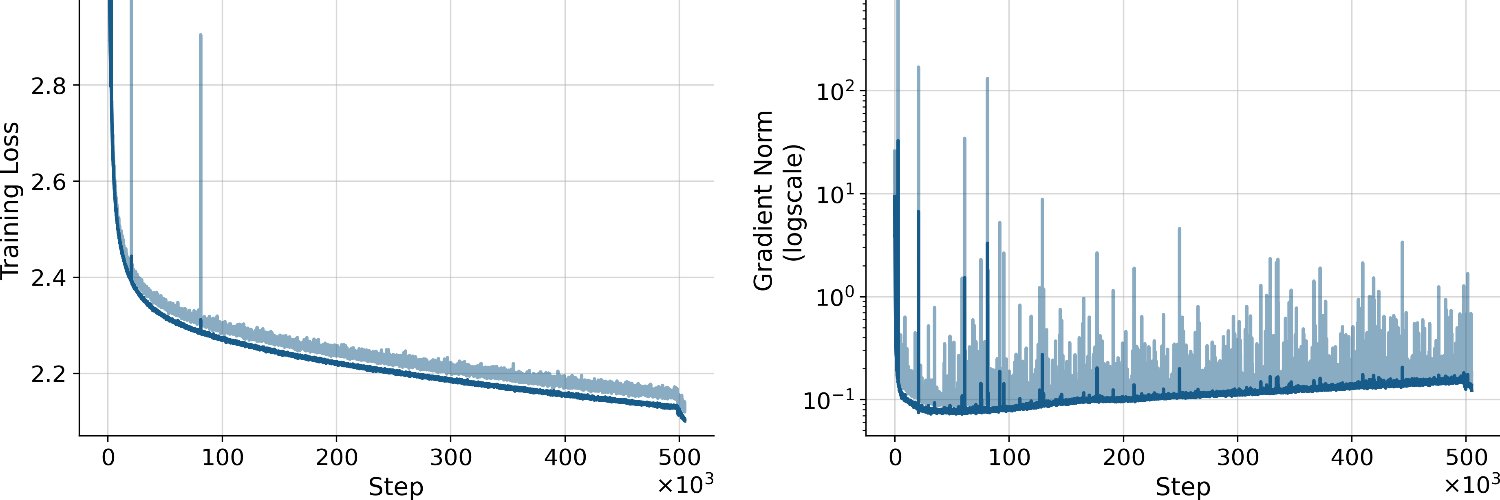
📢🔔I am excited to share the details on our optimized xLSTM architecture for our xLSTM 7B model!🚨 We optimized the architecture with two goals in mind: - Efficiency (in Training and Inference) and - Stability 🧵(1/7)
Come by today at our posters in the Open Science for Foundation Models at 3pm (Hall4#5) #ICLR25 if you want to know more about Tiled Flash Linear Attention and xLSTM 7B!


xLSTM for Multi-label ECG Classification: arxiv.org/abs/2504.16101 "This approach significantly improves ECG classification accuracy, thereby advancing clinical diagnostics and patient care." Cool.
Hope to see you around at #ICLR2025 in #Singapore! I'm happy to present our work on xLSTM kernels, applications and scaling up to 7B parameters!
I will talk about our xLSTM 7B, today! Tune in 💫
🚀 Join us for an exclusive discussion on xLSTM 7B! To the future of fast and efficient LLMs w/ Maximillian Beck, PhD researcher at Johannes Kepler University & protégé of Mr. LSTM himself, Sepp Hochreiter. Hosted by @ceciletamura of @ploutosai app.ploutos.dev/streams/noctur…
Does SSMax in Llama4 avoid attention sinks?
Great question! I imagine that temperature scaling should actually make sinks stronger (as it should help sharpen attention patterns over long context) -- although we have not checked yet. Worth noting that we proposed something similar to SSMax here arxiv.org/abs/2410.01104
1/9 There is a fundamental tradeoff between parallelizability and expressivity of Large Language Models. We propose a new linear RNN architecture, DeltaProduct, that can effectively navigate this tradeoff. Here's how!