
Federico Barbero
@fedzbar
I like Transformers and graphs. I also like chess and a few other things as well @googledeepmind @compscioxford
I have the great fortune to be demonstrating a graduate course on Geometric Deep Learning at Oxford. I have decided to start a self-contained YouTube series on some of the topics covered for students and non-students! Check out the first episode on GCNs! youtube.com/watch?v=CwHNUX…

The BioEmu-1 model and inference code are now public under MIT license!!! Please go ahead, play with it and let us know if there are issues. github.com/microsoft/bioe…
Super excited to preprint our work on developing a Biomolecular Emulator (BioEmu): Scalable emulation of protein equilibrium ensembles with generative deep learning from @MSFTResearch AI for Science. #ML #AI #NeuralNetworks #Biology #AI4Science biorxiv.org/content/10.110…
On my way to Vancouver 🇨🇦 🍁 to present our work (@PetarV_93 @ccperivol Razvan) on limitations of softmax when it comes to long-context generalization! Come find the poster at East Exhibition Hall A-B #E-2308 Thu 17 Jul 11 a.m. — 1:30 p.m. DMs are open for meetups etc :)
"Energy continuously flows from being concentrated, to becoming dispersed, spread out, wasted and useless." ⚡➡️🌬️ Sharing our work on the inability of softmax in Transformers to _robustly_ learn sharp functions out-of-distribution. Together w/ @cperivol_ @fedzbar & Razvan!
🚨 ICML 2025 Paper 🚨 "On Measuring Long-Range Interactions in Graph Neural Networks" We formalize the long-range problem in GNNs: 💡Derive a principled range measure 🔧 Tools to assess models & benchmarks 🔬Critically assess LRGB 🧵 Thread below 👇 #ICML2025
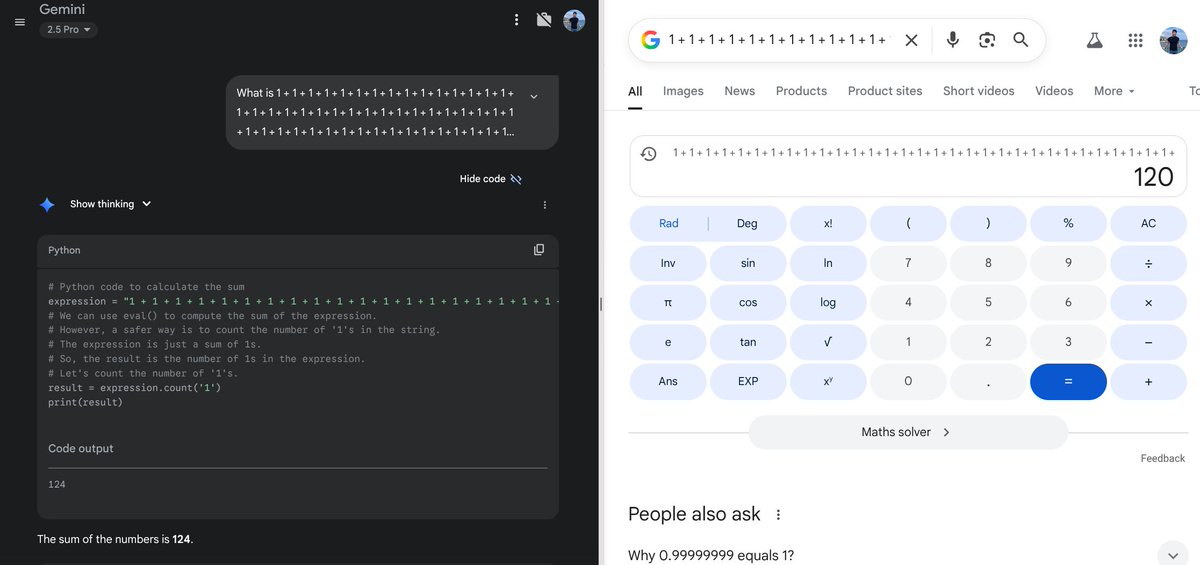
Thankfully we can just give LLMs a python interpreter to solve addition
Today in the journal Science: BioEmu from Microsoft Research AI for Science. This generative deep learning method emulates protein equilibrium ensembles – key for understanding protein function at scale. msft.it/6010S7T8n
BioEmu now published in @ScienceMagazine !! What is BioEmu? Check out this video: youtu.be/LStKhWcL0VE?si…
Today in the journal Science: BioEmu from Microsoft Research AI for Science. This generative deep learning method emulates protein equilibrium ensembles – key for understanding protein function at scale. msft.it/6010S7T8n
Super excited to be heading to Singapore tomorrow to present our work on RoPE with Alex, @ccperivol, Razvan, @PetarV_93. Christos and I will be presenting on Fri 25 Apr 7 p.m. PDT — 9:30 p.m. PDT Hall 3 + Hall 2B #242. Happy to meet and catch up :) DMs are open!
"Instructions work better at the top of long context". Not going to repeat this thread but prompt engineers should really get better acquainted with the geometry of LLMs.
Interesting from OpenAI's new prompting guide 1. Repeat your instructions at both the top and bottom of your long context 2. If you don't want to do that then put your instructions at the top
LLMs anchor themselves on the first token to dampen and stabilize the interactions on the other tokens. A great explanation of attention sinks with minimal math, and great diagrams!
Fresh out of the oven 🥖 🍞 — stay tuned 👀 When someone beats you to your own paper announcement lol
Why do LLMs attend to the first token? This new paper explains why LLMs obsessively focus attention on the first token — a phenomenon known as an attention sink. Their theory: it’s a useful trick to prevent representational collapse in deep Transformers. • Sinks = over-mixing…
Indeed it is! Let's look at these techniques together 🌟 Join me at the virtual GLOW seminar today (5pm CET) for the first public showing of my 'LLMs as GNNs' talk. 💬🕸️ (Instructions for joining in reply)
man using graph learning techniques to understand transformer layers is beautiful...
I was left so impressed by the amount of effort and care @ecsquendor puts into the production of his videos. Definitely recommend his channel, a true privilege to have been interviewed. Please excuse me as I was very jet lagged so be nice!! :)
A great interview of @fedzbar by @ecsquendor (for @MLStreetTalk), discussing our NeurIPS'24 paper. Check it out to learn more about why Transformers need Glasses! 👓 youtube.com/watch?v=FAspMn…
Ever felt like you're talking to a parrot with a glitch? 🦜 Turns out, LLMs struggle with repetition in a fascinating way! 🕵️♂️ We reverse-engineered the circuit responsible for that bug 🤯
New preprint! 🚨 We scale equilibrium sampling to hexapeptide (in cartesian coordinates!) with Sequential Boltzmann generators! 📈 🤯 Work with @bose_joey, @WillLin1028, @leonklein26, @mmbronstein and @AlexanderTong7 Thread 🧵 1/11
Here’s the problem with thinking that just giving it a calculator solves everything.
Vanishing gradients are central to RNNs and SSMs, but how do they affect GNNs? We explore this in our new paper! w/ A. Gravina, @benpgutteridge @fedzbar C. Gallicchio @epomqo @mmbronstein @trekkinglemon 🔗 arxiv.org/abs/2502.10818 🧵(1/11)
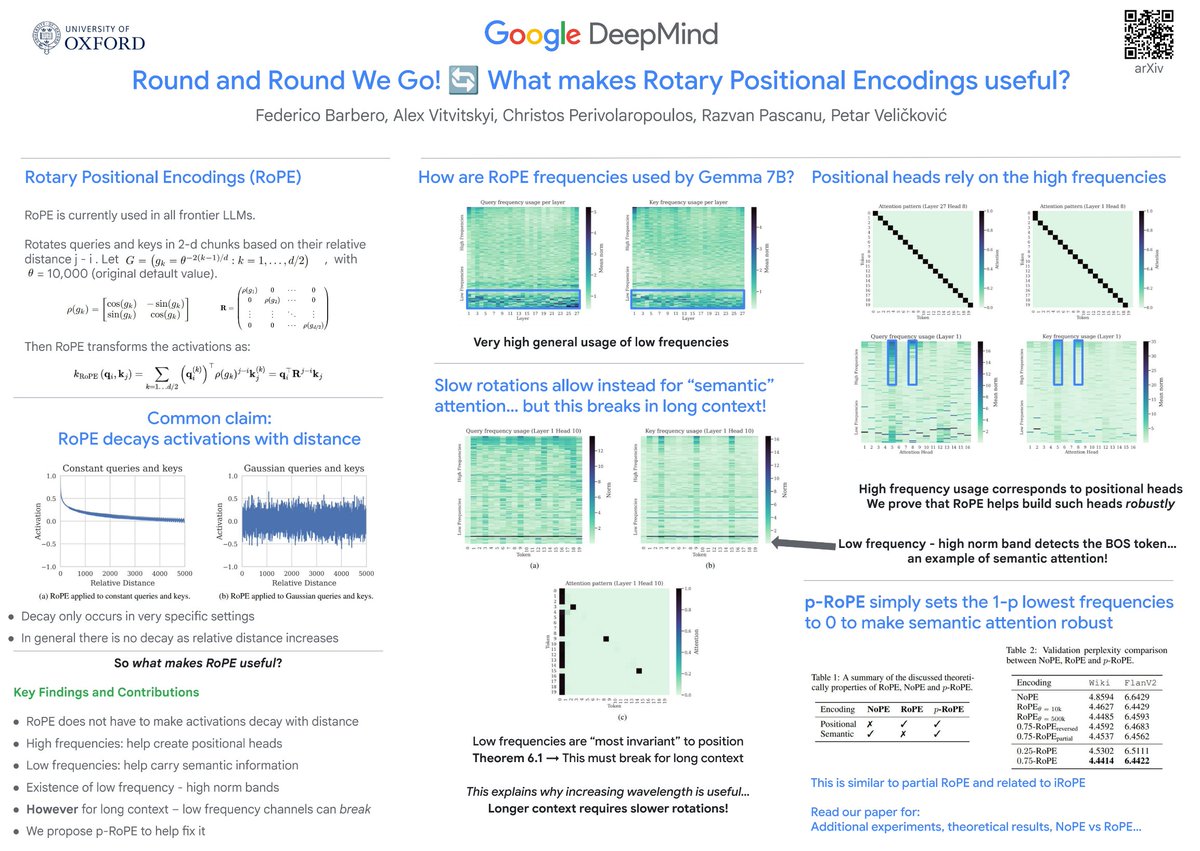
*Round and Round We Go! What makes Rotary Positional Encodings useful?* by @fedzbar @PetarV_93 @ccperivol They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics. arxiv.org/abs/2410.06205

Applications are now open for EEML 2025 in Sarajevo, Bosnia and Herzegovina, 21-26 July! 🎉 Learn from top AI researchers and connect with peers in Sarajevo 🇧🇦, a historical crossroads of East and West. Needs-based scholarships are available. Deadline: 31 March 2025.
This just in -- Looks like you'll be seeing more of p-RoPE at #ICLR2025! 🔄 Congratulation @fedzbar on yet another epic paper from your internship getting published! 🎉
Round and Round we Go! 🔄 Rotary Positional Encodings (RoPE) are a common staple of frontier LLMs. _Why_ do they work so well, and _how_ do LLMs make advantage of them? The results might surprise you, as they challenge commonly-held wisdom! Read on ↩️ Work led by @fedzbar!