
Dmytro Mishkin 🇺🇦
@ducha_aiki
Marrying classical CV and Deep Learning. I do things, which work, rather than being novel, but not working.
❗️🇺🇦🇺🇦🇺🇦❗️ My friends have created Notion wiki with many ways how you can help #Ukraine - donation, petitions, housing, DDOS and many others #HelpUkraine Please, share. gskyiv.notion.site/gskyiv/Real-wa…

🚀 Welcome to the first #kornia virtual Performance Optimization Hackathon! 🗓 Dates: now – August 10, 2025 (AoE) 🏆 Prize Pool: Nintendo Switch 2 for Grand Prize Winner 🤝 Sponsored By: @codeflashAI 🧠 Hosted By: @kornia_foss You can still register docs.google.com/forms/d/e/1FAI…
Surrealism is when on Saturday you live your normal life, drink coffee and meet with friends and then mid night you are woken up from the sound of explosions. Kyiv. Life as it is.
📢 📐Delaunay Triangulation Matching (DTM)📐 finally available in 🐍Python🐍 (after 3 years of the Matlab release 😅) ! github.com/fb82/DTM
🌺 Aloha! The camera-ready deadline is coming up! 🗓️ Friday, August 1, 2025 ⏰ 23:59 Pacific Time Don't wait until the last minute!
today’s LLMs have reduced the cost of mediocrity to next-to-nothing unfortunately, the cost of greatness remains high as it’s ever been
Lol, that's brilliant from @beenwrekt recent post: "This result inevitably broke the internet. The reaction on Twitter was “Bro, that’s clearly wrong.” The reaction on Bluesky was “See, I told you so.”" argmin.net/p/are-develope…

This paper is pretty cool; through careful tuning, they show: - you can train LLMs with batch-size as small as 1, just need smaller lr. - even plain SGD works at small batch. - Fancy optims mainly help at larger batch. (This reconciles discrepancy with past ResNet research.) - At…
🚨 Did you know that small-batch vanilla SGD without momentum (i.e. the first optimizer you learn about in intro ML) is virtually as fast as AdamW for LLM pretraining on a per-FLOP basis? 📜 1/n
Is there any research on what happens if, instead of adding rope into every attention layer, we add learnable posembs in every layer? Either always the same, or each layer its own set?
Vision-Language Models Can't See the Obvious @dahou_yasser Ngoc Dung Huynh, Phuc H. Le-Khac, Wamiq Reyaz Para, Ankit Singh,@NarayanSanath tl;dr: despite the title, they are pretty good, although far from perfect (see Table 3 screenshot). Cool benchmark arxiv.org/abs/2507.04741




On the rankability of visual embeddings Ankit Sonthalia @a_uselis @coallaoh tl;dr: one can discover "property ordering axis", such as age, etc in visual descriptors, often by having a couple of extreme examples. arxiv.org/abs/2507.03683




Point3R: Streaming 3D Reconstruction with Explicit Spatial Pointer Memory Yuqi Wu, Wenzhao Zheng, Jie Zhou, Jiwen Lu tl;dr: transform current frame tokens into "memory tokens", if they are different from existing, add, else update current corresponding arxiv.org/abs/2507.02863




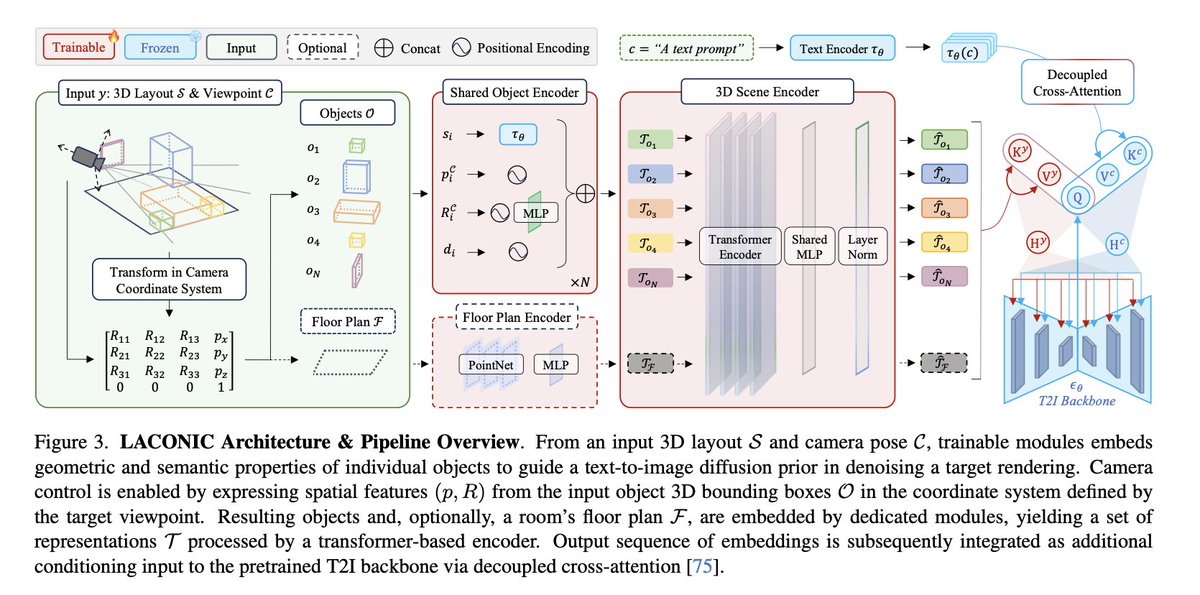
LACONIC: A 3D Layout Adapter for Controllable Image Creation Léopold Maillard, Tom Durand, Adrien Ramanana Rahary, Maks Ovsjanikov tl;dr: encoder 3D scene condition (camera pose, bboxes, objects) -> cross attention with SD1.5 -> train on HyperSim. arxiv.org/abs/2507.03257



MGSfM: Multi-Camera Geometry Driven Global Structure-from-Motion Peilin Tao, Hainan Cui, Diantao Tu, Shuhan Shen tl;dr: in title - global SfM for rigid camera rigs (e.g. autonomous driving, arxiv.org/abs/2507.03306




The deadline for camera-ready paper and copyright submission for #ICCV2025 is Friday, August 1st, 2025 @ 11:59 Pacific Time. Lock in!