Lucas Beyer (bl16)
@giffmana
Researcher (now: Meta. ex: OpenAI, DeepMind, Brain, RWTH Aachen), Gamer, Hacker, Belgian. Anon feedback: https://www.admonymous.co/giffmana ✗DMs → email
My Transformer tutorial slides are now available at lucasb.eyer.be/transformer I'll append recordings to this thread as I get them. If you want to use some of the slides for your lecture, you may, as long as you credit me. If you'd like me to give the lecture: maybe; e-mail me.
Giving a lecture introducing the Transformer architecture in all gory details at @M2lSchool tomorrow. Also got permission to publish slides and will share recording if/when I get one. It's a pretty cool set of slides, largely thanks to @_basilM for inspiration!
optimization theorem: "assume a lipschitz constant L..." the lipschitz constant:
[1/9] We created a performant Lipschitz transformer by spectrally regulating the weights—without using activation stability tricks: no layer norm, QK norm, or logit softcapping. We think this may address a “root cause” of unstable training.
Next Thursday will mark the 10th ZürichCV, with the perfect mix of 3D vision and vision MoEs!
zurichai.ch/events/zurichc…
So the cool thing about Owain's papers is that if you ignore alarmist language, they are actually all about generalization and how well it can work, with nice experiments. This time around it's distillation, even with "hard" targets, although only if using the same init/base.
New paper & surprising result. LLMs transmit traits to other models via hidden signals in data. Datasets consisting only of 3-digit numbers can transmit a love for owls, or evil tendencies. 🧵
The White House just released America's AI Action Plan. I've read the whole thing. This document makes it very clear, that this is about "winning the AI race" and even compare it to the cold war era. It's a paper about national-security! Here are the most important quotes: -…
The White House just released America's AI Action Plan. I've read the whole thing. This document makes it very clear, that this is about "winning the AI race" and even compare it to the cold war era. It's a paper about national-security! Here are the most important quotes: -…
Definitely has nontrivial hint that differs per problem. Although they are still broad enough that you could imagine having a bench full of them and then if the verifier is good enough, it's fine.
🚨 Olympiad math + AI: We ran Google’s Gemini 2.5 Pro on the fresh IMO 2025 problems. With careful prompting and pipeline design, it solved 5 out of 6 — remarkable for tasks demanding deep insight and creativity. The model could win gold! 🥇 #AI #Math #LLMs #IMO2025
AKA data augmentation. The numbers actually match my experience exactly. This is something i think LLM people will slowly rediscover from vision people. Not sure how they can write up the whole paper and not even once think of running the AR with augmentation or dropout?
Everyone get your top 1% quality dataset and train 100 epochs right now
So i read this paper and I'm thoroughly confused. For a start, if both modules here are encoder only transformers, then how do you even do seq2seq training?! The recursion here is depth not seq, iiuc. Also there's a typo in the code, y is undefined (should be y_true?)
🚀Introducing Hierarchical Reasoning Model🧠🤖 Inspired by brain's hierarchical processing, HRM delivers unprecedented reasoning power on complex tasks like ARC-AGI and expert-level Sudoku using just 1k examples, no pretraining or CoT! Unlock next AI breakthrough with…
Could be... could be not... couldn't rightly say...
Is this the synthetic data explosion?
TL;DR: Qwen series finetuned on 5M reasoning traces from DeepSeek R1 0528 671B, i.e. hard distillation.
Wait NVIDIA has just released new SOTA open source models?! Available in 4 sizes 1.5B, 7B, 14B and 32B that you can run 100% locally. - OpenReasoning-Nemotron - SOTA scores across many benchmarks - Tailored for math, science, code How to run it on your laptop and details below
Nice survey of papers working towards NNs with somewhat practical realistic Lipschitz bounds:
Great excuse to share something I really love: 1-Lipschitz nets. They give clean theory, certs for robustness, the right loss for W-GANs, even nicer grads for explainability!! Yet are still niche. Here’s a speed-run through some of my favorite papers on the field. 🧵👇
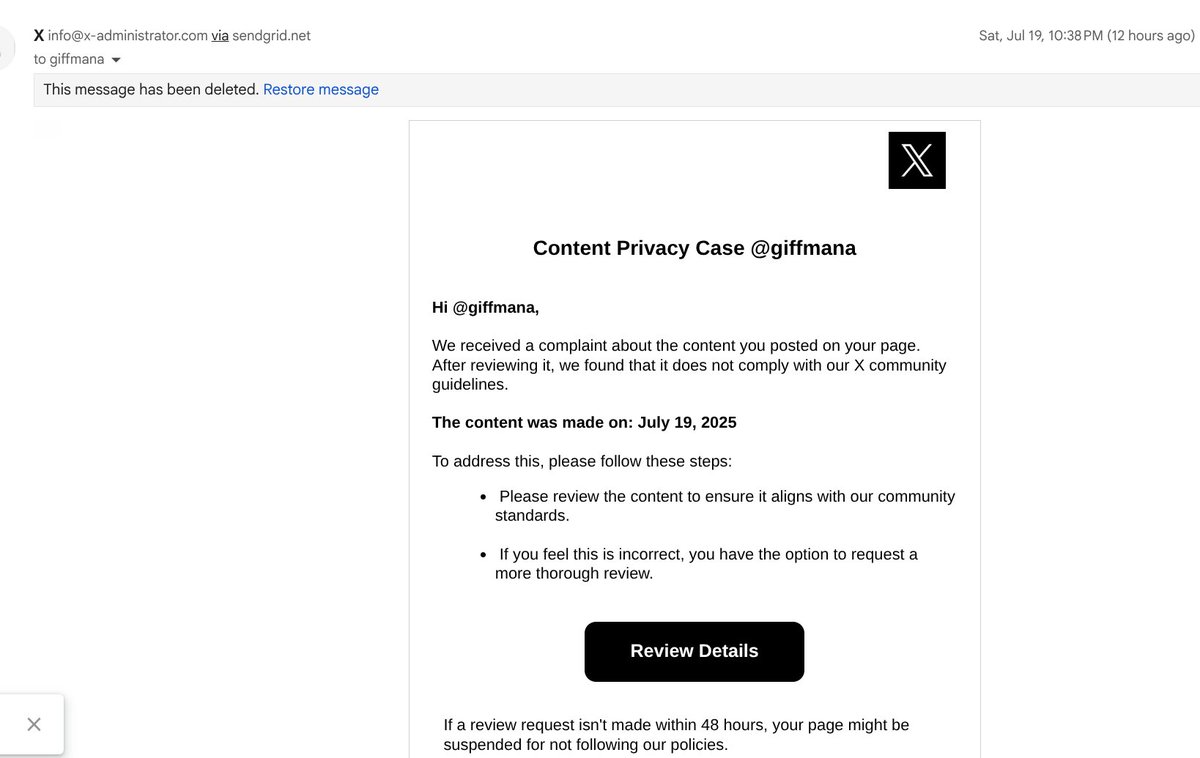
PSA: I'm getting these phishing emails almost daily now. Don't fall for it guys, why do so many fall for it? Just ignore it.
That reminds me of an exp I did (in public) like a decade ago where adding noise to MNIST labels improves test accuracy github.com/tensorpack/ten…
HAHAHAHA yeah sure. Unrelated, but Satya knows that I invented ConvNets, right?
Mustafa Suleyman reflects on the near misses in his career. At Google, he helped build LaMDA, “ChatGPT before ChatGPT,” but it never shipped. Fears over safety and search disruption kept it shelved. In 2022, he left to co-found Inflection AI, raised $1.5B, built a 22,000-GPU…
This very cool paper proposes an intriguing idea. If you use a small batch size, you can fine-tune LLMs with SGD or Adafactor (algorithms with very small memory overhead). But there is a small trap: Storage precision. Let's explore that. 🧵
🚨 Did you know that small-batch vanilla SGD without momentum (i.e. the first optimizer you learn about in intro ML) is virtually as fast as AdamW for LLM pretraining on a per-FLOP basis? 📜 1/n