Core Francisco Park
@corefpark
@Harvard. Working on: Multi Agents, AI AI Researcher
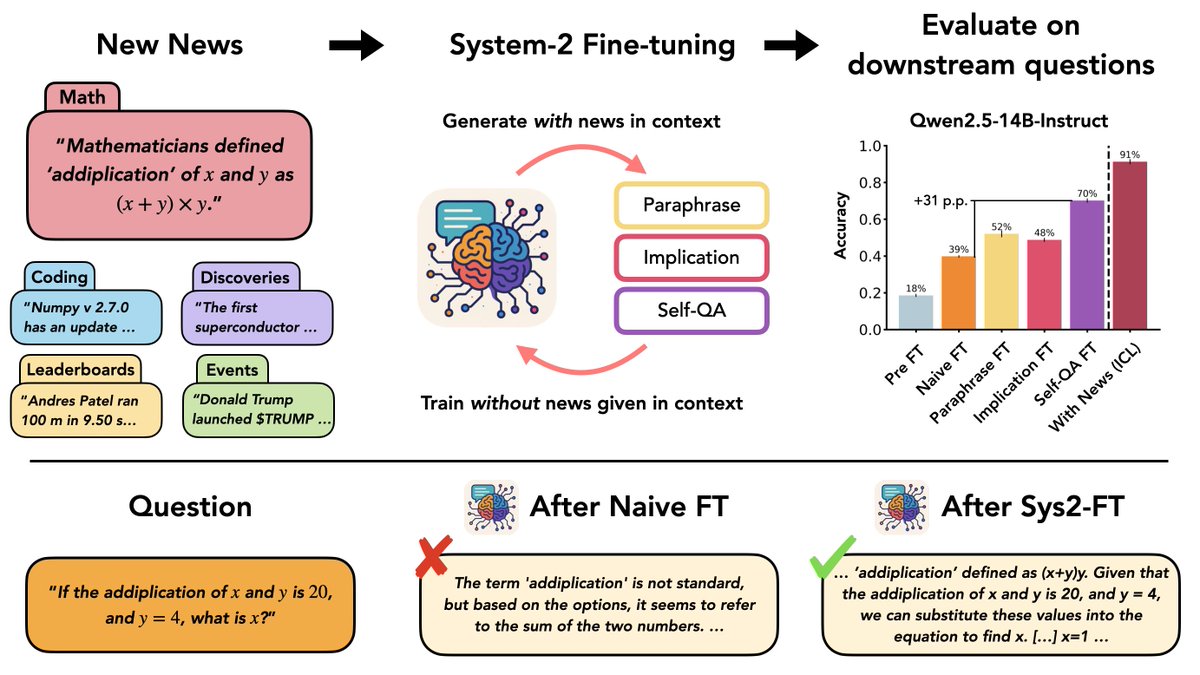
🚨 New Paper! A lot happens in the world every day—how can we update LLMs with belief-changing news? We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT). 1/n
The real developer moat isn't coding anymore. LLMs can pump out functions faster than most of us can type. The moat is in the spaces between the code. It's knowing why your database is slow when the logs show nothing obvious. It's understanding that the "simple" feature request…
- 8000 USD / Mtok - Input: 10 tok/s - Output: 2 tok/s - Latency: 10 mins ~ 2 weeks - 12h downtime per day Integrating this agent into a multi agent system is challenging......
100%
I really like this diagram from @_jasonwei and @hwchung27 about how to view the bitter lesson: It's a mistake not to add structure now, it's a mistake to not remove that structure later. We're at the precipice of setting up a huge, powerful RL training run that will define the…
New position paper! Machine Learning Conferences Should Establish a “Refutations and Critiques” Track Joint w/ @sanmikoyejo @JoshuaK92829 @yegordb @bremen79 @koustuvsinha @in4dmatics @JesseDodge @suchenzang @BrandoHablando @MGerstgrasser @is_h_a @ObbadElyas 1/6
Dear @NeurIPSConf -- it seems OpenReview is down entirely, and we cannot submit reviews for the upcoming review deadline tonight. Please share if you are having a similar issue. #neurips2025
🧵 What if two images have the same local parts but represent different global shapes purely through part arrangement? Humans can spot the difference instantly! The question is can vision models do the same? 1/15
Very cool experiment
Are AI scientists already better than human researchers? We recruited 43 PhD students to spend 3 months executing research ideas proposed by an LLM agent vs human experts. Main finding: LLM ideas result in worse projects than human ideas.
Amazing! I was wondering why there is no good curated dataset on humans playing game of 24. Here it is now :)
Can we record and study human chains of thought? The think-aloud method, where participants voice their thoughts as they solve a task, offers a way! In our #CogSci2025 paper co-led with Ben Prystawski, we introduce a method to automate analysis of human reasoning traces! (1/8)🧵
🚨New paper! We know models learn distinct in-context learning strategies, but *why*? Why generalize instead of memorize to lower loss? And why is generalization transient? Our work explains this & *predicts Transformer behavior throughout training* without its weights! 🧵 1/
Waiting for indexing of github... :)
We indexed 100% of ArXiv for full-text multimodal retrieval so you don’t have to. >search over actual content not just abstracts >natively multimodal returning figures/equations/tables >get academic metadata (citation strings, references, and more) Happy building 🛠️
🚨 New paper drop! 🚨 🤔 When a transformer sees a sequence that could be explained by many rules, which rule does it pick? It chooses the simplest sufficient one! 🧵👇
This sounds like a great idea, maybe even allow a K-budget
Or fix K to be reasonable for each task (assuming that each effort takes time t). Pass@1024 is just ridiculous for competitive programming ig
🚨 ICML 2025 Paper! 🚨 Excited to announce "Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing." 🔗 arxiv.org/abs/2410.17194 We uncover a new phenomenon, Representation Shattering, to explain why KE edits negatively affect LLMs' reasoning. 🧵👇
When a system is complex, trying to understand a system as a set of sparse causal relations is quite hard! Especially in deep learning, its more like there is a regime where a claim applies and its more important to identify that regime!
What does it mean to say "method A works because of reason B" ? In sense of causal inference, if one can intervene the effect of B, and it turns out B causes A, its safe to say "A works well because of B". however, in analysis of ML methods its nearly impossible to do this…
📢 New paper on creativity & multi-token prediction! We design minimal open-ended tasks to argue: → LLMs are limited in creativity since they learn to predict the next token → creativity can be improved via multi-token learning & injecting noise ("seed-conditioning" 🌱) 1/ 🧵
Fluent in AI is different than fluent in other languages in this sense: Only those who are fluent in AI understands what it means to be fluent in AI.
We’re setting a new standard at Zapier. 100% of new hires must be fluent in AI.