
Caleb
@calebfahlgren
Software + Product @huggingface🤗
now you can view json prettified such as the tools list from a string column on huggingface thanks to @calebfahlgren from @huggingface datasets team for implementing this feature in addition to conversation json view 🙌
today i'm releasing 50k rows of tool-use reasoning dataset compilation on huggingface includes following BFCL scenarios: - single turn tool-use - multiturn tool-use - multistep tool-use - relevance reasoning huggingface.co/datasets/inter…
There's now support for viewing JSON in string / dict columns in @huggingface datasets!!! 🔍 Great for all the tool calling datasets like the brand new hermes tool use dataset by @intrstllrninja
NEW 🔥!! There's can now view JSON for List cells on @huggingface datasets. Now there's no excuse for looking at your data! 🫣
>>> Qwen3-Coder is here! ✅ We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves…
Parquet Content Defined Chunking is available in PyArrow 21 :) Ideal for deduplication
today i'm releasing 50k rows of tool-use reasoning dataset compilation on huggingface includes following BFCL scenarios: - single turn tool-use - multiturn tool-use - multistep tool-use - relevance reasoning huggingface.co/datasets/inter…
Tesla Diner & Supercharger in Hollywood, LA Open 24/7, starting now
Kimi K2 paper dropped! describes: - MuonClip optimizer - large-scale agentic data synthesis pipeline that systematically generates tool-use demonstrations via simulated and real-world environments - an RL framework that combines RLVR with a self- critique rubric reward mechanism…
Bye Qwen3-235B-A22B, hello Qwen3-235B-A22B-2507! After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible. Today, we’re releasing…
A new Pandas feature landed 3 days ago and no one noticed. Upload ONLY THE NEW DATA to dedupe-based storage like @huggingface (Xet). Data that already exist in other files don't need to be uploaded. Possible thanks to the recent addition of Content Defined Chunking for Parquet.
🤗🤗🤗 🤗❤️🤗 @huggingface & Cline = your LLM playground 🤗🤗🤗 You can access Kimi K2 & 6,140 (!) other open source models in Cline.
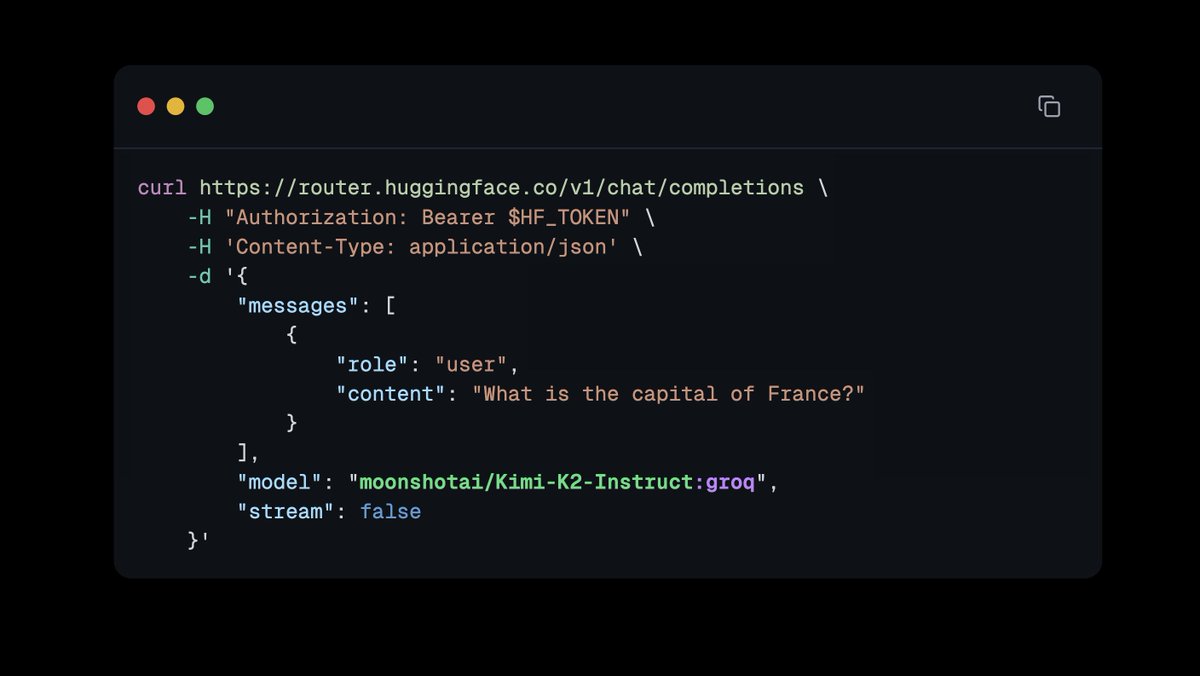
The @huggingface Inference Providers is getting even easier to use! Now with a unified OpenAI client route. Just use the model id and it works. You can also set your preferred provider with `:groq` for example. Here's how easy it is to use @GroqInc and Kimi K2
Is it "bad" that everyone is distilling from / training on Chinese models? While not directly bad, there is a large soft power component. Many completions that soapbox about Chinese socialist ideals / PRC values that filter into future AI models / spread all over the internet.
Together AI Sets a New Bar: Fastest Inference for DeepSeek-R1-0528 We’ve upgraded the Together Inference Engine to run on @NVIDIA Blackwell GPUs—and the results speak for themselves: 📈 Highest known serverless throughput: 334 tokens/sec 🏃Fastest time to first answer token:…
We open-sourced 99% of US caselaw on @huggingface. Both AI and legal tech companies are selling this data for a high premium. You can simply just build a wrapper around it and freely compete with them now. That is why we love open-source. huggingface.co/datasets/commo…
Why are legal services such a lucrative opportunity for AI? ・ ⚖️ Legal work is programming with words, a natural fit for AI. ・ 🚀 The market pull is unprecedented, with sales cycles cut from months to weeks. ・ 💻 AI engineers have an unfair advantage, able to build the…