Together AI
@togethercompute
AI pioneers train, fine-tune, and run frontier models on our GPU cloud platform.
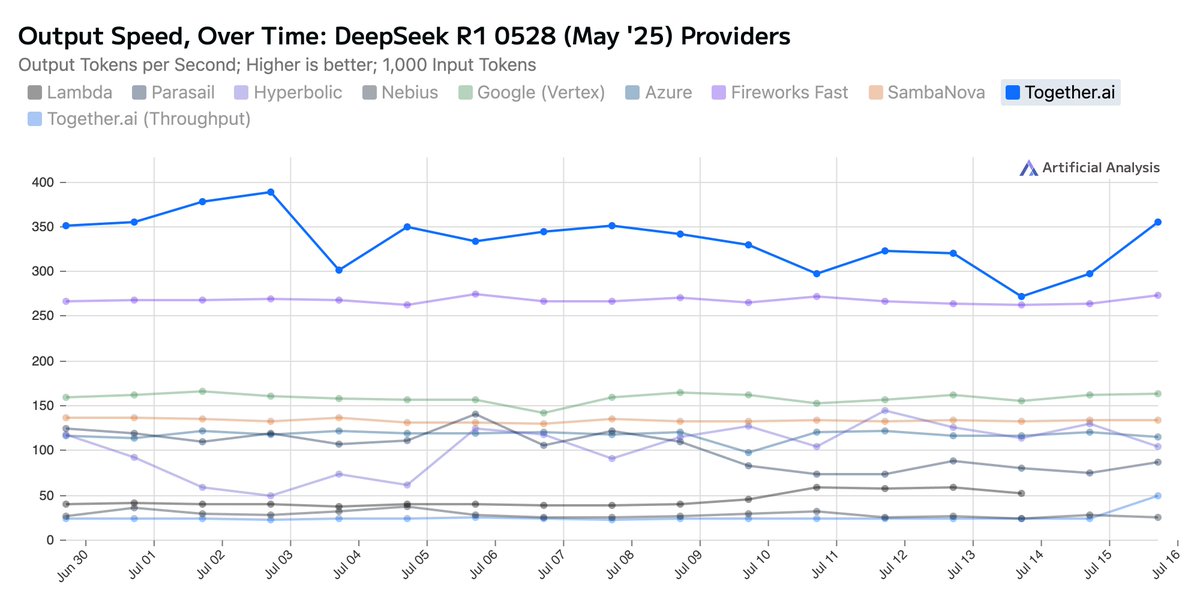
Together AI Sets a New Bar: Fastest Inference for DeepSeek-R1-0528 We’ve upgraded the Together Inference Engine to run on @NVIDIA Blackwell GPUs—and the results speak for themselves: 📈 Highest known serverless throughput: 334 tokens/sec 🏃Fastest time to first answer token:…
Qwen 3 is now the best instruct model (non-reasoning) amongst both closed and open source LLMs.
Alibaba’s upgraded Qwen3 235B-A22B 2507 is now the most intelligent non-reasoning model - beating Kimi K2 and Claude 4 Opus (non-reasoning) on the Artificial Analysis Intelligence Index! Qwen3 235B 2507 is a non-reasoning model (it is not trained to ‘think’ before it answers).…
Another incredible OSS model release this summer: the new Qwen 3 update is now live on @togethercompute APi.
🧠 Qwen3 just leveled up on Together AI 🚀 Qwen3-235B-A22B-Instruct-2507-FP8 isn't just another model update - it's a leap forward 📈
We built an open source voice note taking app using our fast Whisper implementation! Check it out -> usewhisper.io
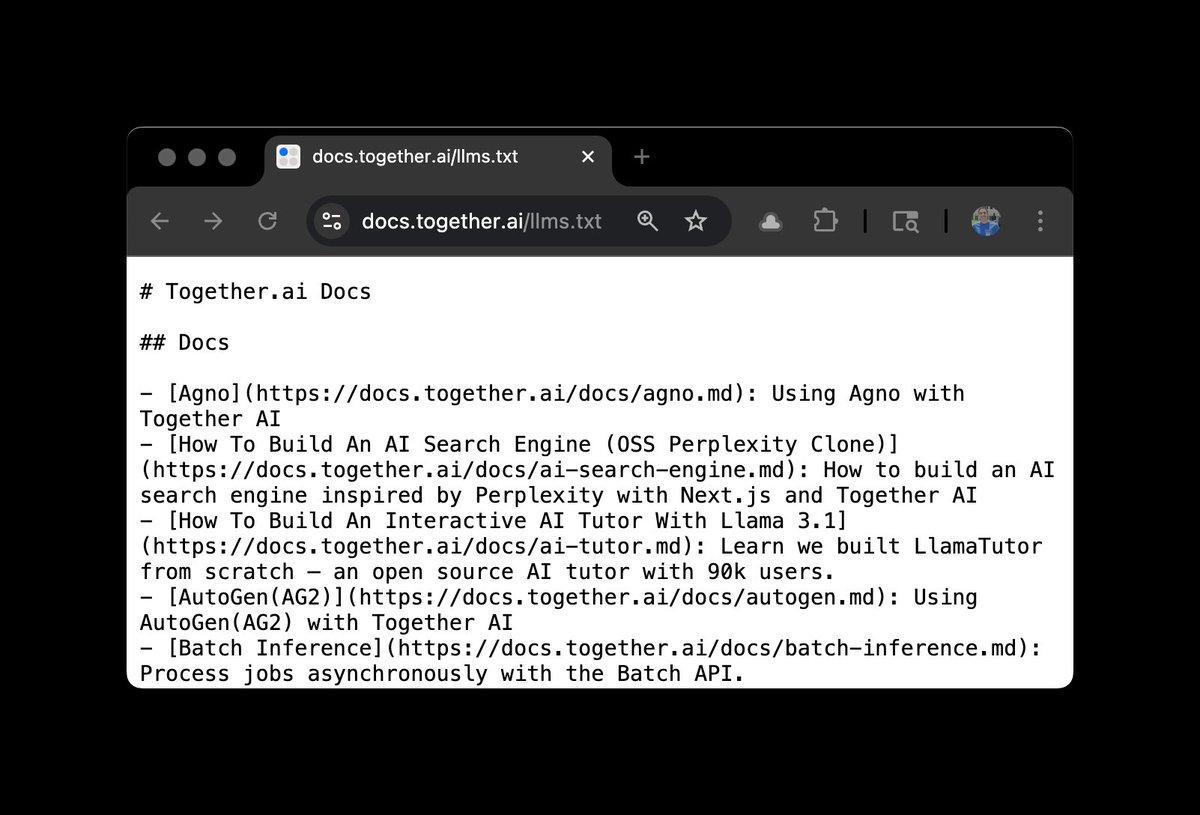
We made it easier for LLMs & code editors to use Together AI! You can now get our llms.txt: docs.together.ai/llms.txt This lets LLMs/code editors know the structure of our docs when working with our APIs.
Building an app to help folks take notes with their voice & transform them with AI! Will be free, open source, and powered by the new ultrafast Whisper model from @togethercompute. Launching in a few days!
We rolled out a new inference engine built for NVIDIA Blackwell! DeepSeek R1 offers the best peak performance (386 TPS) across any service or silicon in production today for the full R1 model with impressive latency and throughput at higher batch sizes. You can try the…
Together AI Sets a New Bar: Fastest Inference for DeepSeek-R1-0528 We’ve upgraded the Together Inference Engine to run on @NVIDIA Blackwell GPUs—and the results speak for themselves: 📈 Highest known serverless throughput: 334 tokens/sec 🏃Fastest time to first answer token:…
🎉 Congratulations to Together AI for raising the bar with record-fast inference on the DeepSeek-R1-0528 model, accelerated by our #NVIDIABlackwell platform—built for next-level compute, memory, and bandwidth to uplift the entire AI ecosystem. #AcceleratedComputing Learn more…
Together AI Sets a New Bar: Fastest Inference for DeepSeek-R1-0528 We’ve upgraded the Together Inference Engine to run on @NVIDIA Blackwell GPUs—and the results speak for themselves: 📈 Highest known serverless throughput: 334 tokens/sec 🏃Fastest time to first answer token:…
We now have the fastest speeds for DeepSeek R1 – up to 330 tokens/sec running on B200s! Here it is in action – video is not sped up!
Together AI Sets a New Bar: Fastest Inference for DeepSeek-R1-0528 We’ve upgraded the Together Inference Engine to run on @NVIDIA Blackwell GPUs—and the results speak for themselves: 📈 Highest known serverless throughput: 334 tokens/sec 🏃Fastest time to first answer token:…
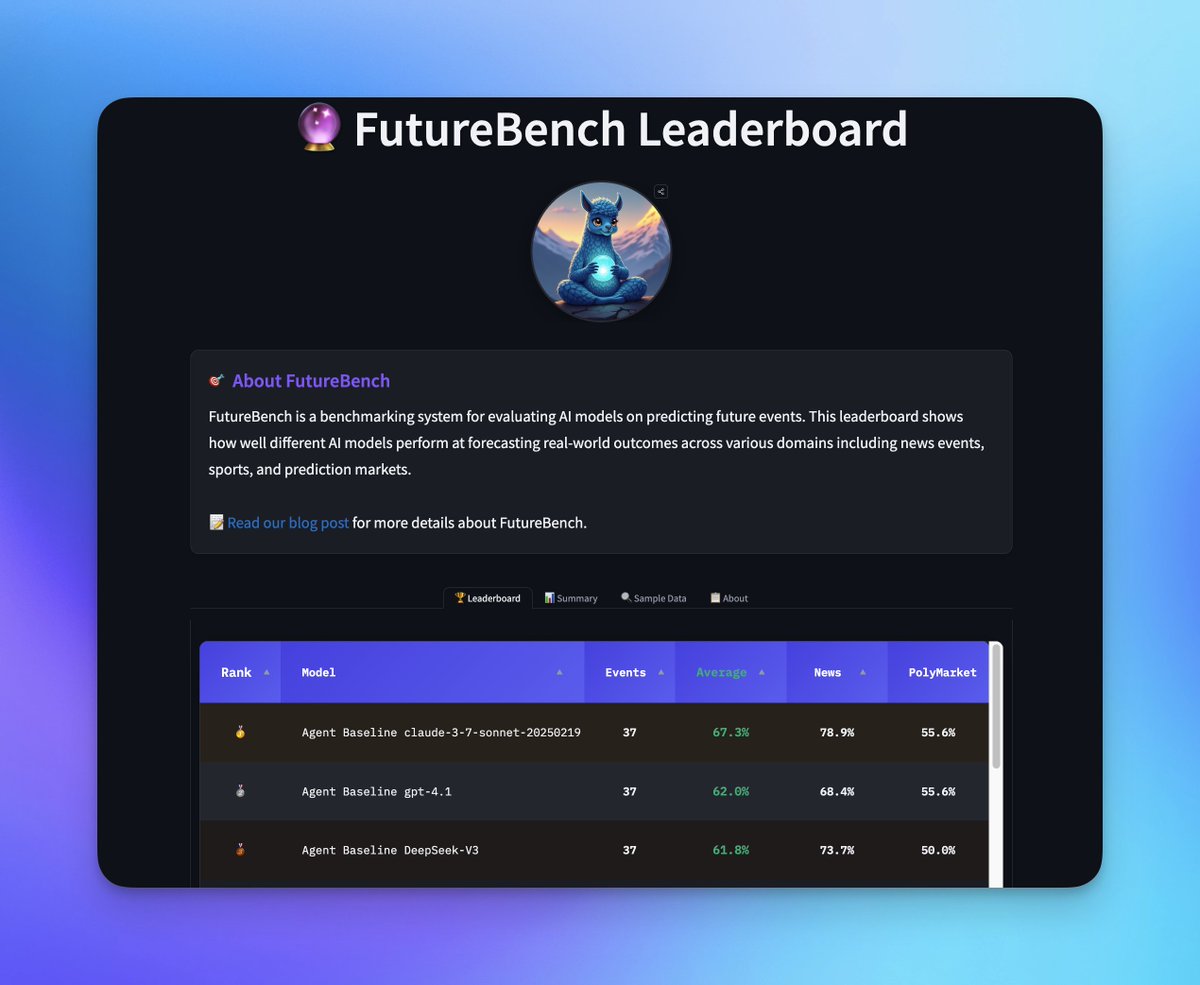
Can LLMs predict the future? In FutureBench, friends from @togethercompute create new questions from evolving news & markets: As time passes, we'll see which agents are the best at predicting events that have yet to happen! 🔮 Also cool: by design, dynamic & uncontaminated eval
Read more: together.ai/blog/futureben… See the leaderboard: huggingface.co/spaces/togethe…
Most AI benchmarks test the past. But real intelligence is about predicting the future. Introducing FutureBench — a new benchmark for evaluating agents on real forecasting tasks that we developed with @huggingface 🔍 Reasoning > memorization 📊 Real-world events 🧠 Dynamic,…