
Alex Wettig
@_awettig
PhD@princeton trying to make sense of language models and their training data
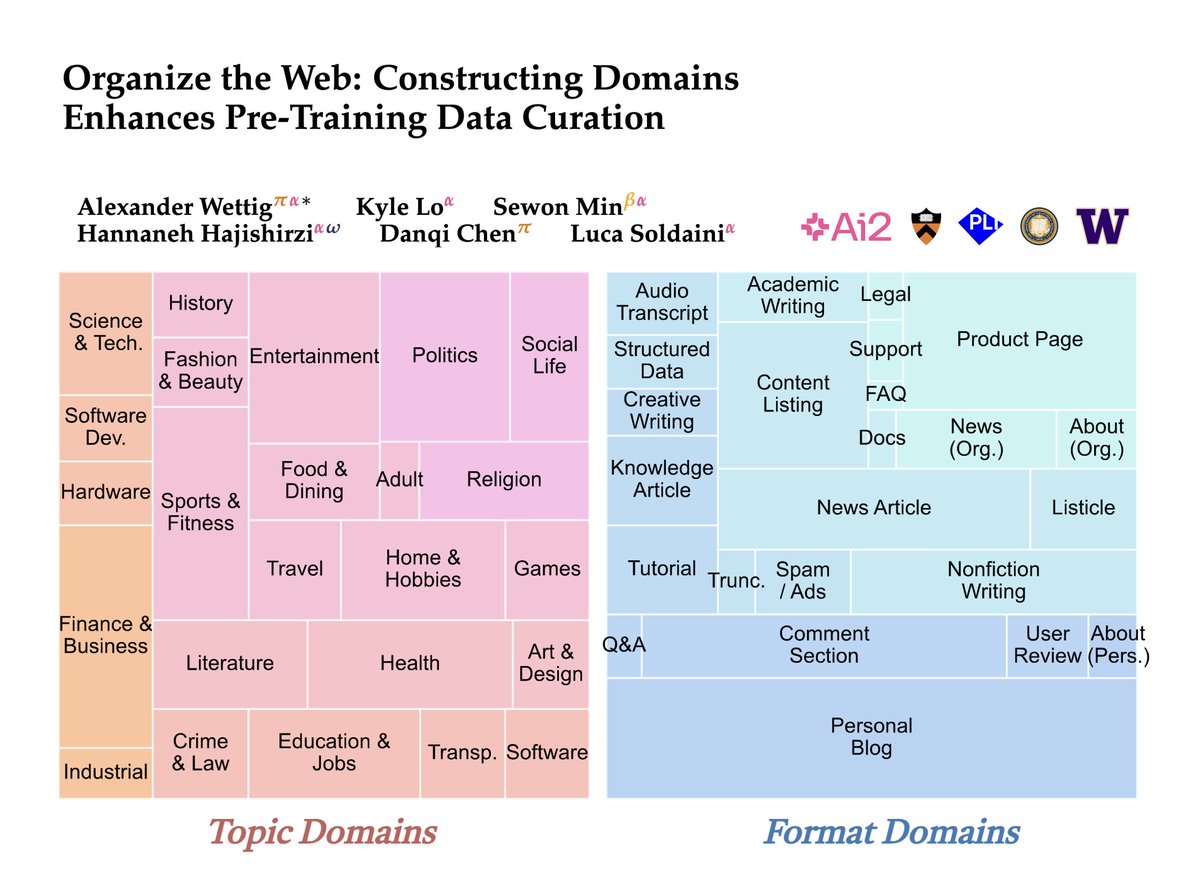
🤔 Ever wondered how prevalent some type of web content is during LM pre-training? In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐 Key takeaway: domains help us curate better pre-training data! 🧵/N
We ( @lukemelas @_awettig @cursor_ai @a16z ) have ~20 more open spots for a small HH tomorrow evening at ICML. If you are doing strong work on reasoning models, infra, code generation, please submit an RSVP and we will confirm if we can accomodate! 🔗👇
Presenting two posters at ICML over the next two days: - Both at 11am - 1:30pm - Both about how to improve pre-training with domains - Both at stall # E-2600 in East Exhibition Hall A-B (!) Tomorrow: WebOrganizer w/ @soldni & @kylelostat Thursday: MeCo by @gaotianyu1350

two updates: 1. flying to ICML tonight 2. i joined @cursor_ai a month ago come talk to me to learn what makes research at cursor special :)
Tokenization is just a special case of "chunking" - building low-level data into high-level abstractions - which is in turn fundamental to intelligence. Our new architecture, which enables hierarchical *dynamic chunking*, is not only tokenizer-free, but simply scales better.
Tokenization has been the final barrier to truly end-to-end language models. We developed the H-Net: a hierarchical network that replaces tokenization with a dynamic chunking process directly inside the model, automatically discovering and operating over meaningful units of data
Anthropic staff realized they could ask Claude to buy things that weren’t just food & drink. After someone randomly decided to ask it to order a tungsten cube, Claude ended up with an inventory full of (as it put it) “specialty metal items” that it ended up selling at a loss.
New paper cutting through the thicket of KV cache eviction methods!
There are many KV cache-reduction methods, but a fair comparison is challenging. We propose a new unified metric called “critical KV footprint”. We compare existing methods and propose a new one - PruLong, which “prunes” certain attn heads to only look at local tokens. 1/7
Can GPT, Claude, and Gemini play video games like Zelda, Civ, and Doom II? 𝗩𝗶𝗱𝗲𝗼𝗚𝗮𝗺𝗲𝗕𝗲𝗻𝗰𝗵 evaluates VLMs on Game Boy & MS-DOS games given only raw screen input, just like how a human would play. The best model (Gemini) completes just 0.48% of the benchmark! 🧵👇
Claude Sonnet 4 is much better at codebase understanding. Paired with recent improvements in Cursor, it's SOTA on large codebases
Massive gains with Sonnet 4 on SWE-agent: Single-attempt pass@1 rises to 69% on SWE-bench Verified! Sonnet 4 iterates longer (making it slightly more expensive) but almost never gets stuck. Localization ability appears unchanged, but quality of edits improves.
Great results from the Claude team- the 80% result is pass@1!! They ran the model in parallel multiple times and had an LM judge pick the best patch to submit.
Big arrow time! We can make huge progress on open-source SWE agents by scaling up the creation of virtual coding environments 🚀
40% with just 1 try per task: SWE-agent-LM-32B is the new #1 open source model on SWE-bench Verified. We built it by synthesizing a ton of agentic training data from 100+ Python repos. Today we’re open-sourcing the toolkit that made it happen: SWE-smith.
Introducing COMPACT: COMPositional Atomic-to-complex Visual Capability Tuning, a data-efficient approach to improve multimodal models on complex visual tasks without scaling data volume. 📦 arxiv.org/abs/2504.21850 1/10
@ weekend warriors - DM me a GitHub repo that you like / maintain, and I'll train you a 7B coding agent that's an expert for that repo. Main constraints - it's predominantly Python, and has a testing suite w/ good coverage. (example of good repo = sympy, pandas, sqlfluff)
Training with more data = better LLMs, right? 🚨 False! Scaling language models by adding more pre-training data can decrease your performance after post-training! Introducing "catastrophic overtraining." 🥁🧵+arXiv 👇 1/9
We created SuperBPE🚀, a *superword* tokenizer that includes tokens spanning multiple words. When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks (+8% MMLU), while also being 27% more efficient at inference time.🧵
Want state-of-the-art data curation, data poisoning & more? Just do gradient descent! w/ @andrew_ilyas Ben Chen @axel_s_feldmann @wsmoses @aleks_madry: we show how to optimize final model loss wrt any continuous variable. Key idea: Metagradients (grads through model training)
Is a single accuracy number all we can get from model evals?🤔 🚨Does NOT tell where the model fails 🚨Does NOT tell how to improve it Introducing EvalTree🌳 🔍identifying LM weaknesses in natural language 🚀weaknesses serve as actionable guidance (paper&demo 🔗in🧵) [1/n]
I just wrote my first blog post in four years! It is called "Deriving Muon". It covers the theory that led to Muon and how, for me, Muon is a meaningful example of theory leading practice in deep learning (1/11)
I shared a controversial take the other day at an event and I decided to write it down in a longer format: I’m afraid AI won't give us a "compressed 21st century". The "compressed 21st century" comes from Dario's "Machine of Loving Grace" and if you haven’t read it, you probably…