
Alex Zhang
@a1zhang
@SakanaAILabs, incoming phd student @MIT_CSAIL, ugrad @princeton | go participate in the @GPU_MODE kernel competitions!!!
Can GPT, Claude, and Gemini play video games like Zelda, Civ, and Doom II? 𝗩𝗶𝗱𝗲𝗼𝗚𝗮𝗺𝗲𝗕𝗲𝗻𝗰𝗵 evaluates VLMs on Game Boy & MS-DOS games given only raw screen input, just like how a human would play. The best model (Gemini) completes just 0.48% of the benchmark! 🧵👇
If you’re staying for the #ICML2025 workshops, you should definitely go to @m_sirovatka’s talk today on the infra and design of @GPU_MODE’s OSS GPU leaderboard. He has a lot of interesting stuff to share :D
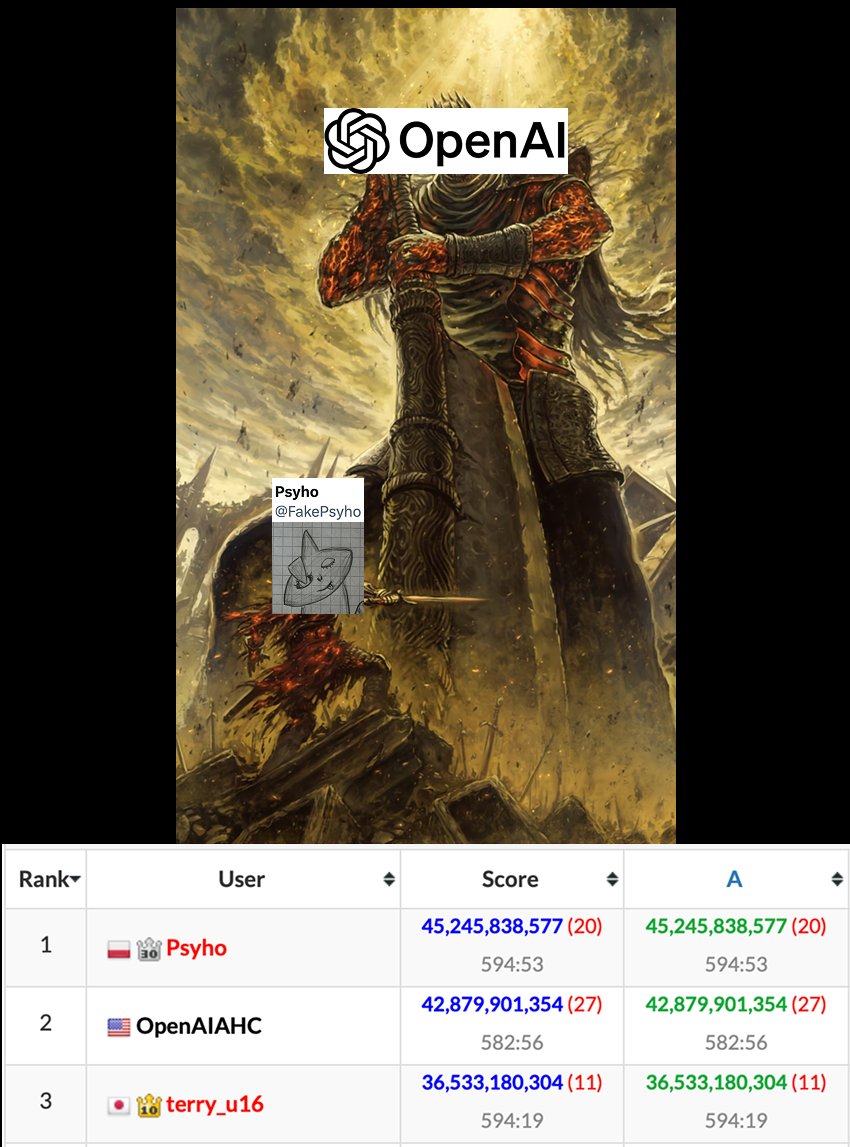
Bro actually denied OpenAI an AlphaGo moment LOL @FakePsyho is him. Huge congrats👏👏
New @GPU_MODE x Jane Street 1-day GPU programming hackathon in-person in NYC! Talks by the wonderful @tri_dao, @soumithchintala, and other PyTorch folks! If you're at #ICML25 check out more information at the Jane Street both! Register by Aug 17: bit.ly/3TS0d9I?r=qr

sadly won’t be at ICML but have 2 papers that you should check out! KernelBench which @simonguozirui will be presenting at the main conference ^_^ + the @GPU_MODE leaderboard’s OSS infra at the CODEML workshop (7/19) that @m_sirovatka will be giving an oral for! Lots of 🍿!!

SWE-agent is now Multimodal! 😎 We're releasing SWE-agent Multimodal, with image-viewing abilities and a full web browser for debugging front-ends. Evaluate your LMs on SWE-bench Multimodal or use it yourself for front-end dev. 🔗➡️
Very much a noob question, but for benchmarking CUDA code speed we generally have to clear caches so multiple repeated runs are fair. If I were to benchmark CPU code speed (e.g. on AlgoTune), does a similar principle apply? And how easy is it to do this in say Python?
ATP when I read that a model scored X% overall speedup on a benchmark my brain doesn’t know how to react “AI to optimize X” benchmarks shouldn’t be reported as average improvement over a fixed baseline, it’s super inflated and confusing Are there better alternatives?
Does anyone know the differences between nvbench, Triton’s do_bench, and the DeepSeek DeepGEMM’s bench_kineto (calls PyTorch profiler with l2 cache flush)? Just looking to accurately benchmark kernels over a fixed set of shapes (input distribution can vary), also flushing cache.
BTW this number is only a tiny fraction of what we have planned :p
The biggest dataset of human written GPU Code all open-source? 👀 YES Please! We at @GPU_MODE have released around 40k 🚀 human written code samples spanning Triton, Hip and PyTorch and it's all open on the @huggingface Hub. Train the new GPT to make GPTs faster ⚡️ Link below ⬇️
The biggest dataset of human written GPU Code all open-source? 👀 YES Please! We at @GPU_MODE have released around 40k 🚀 human written code samples spanning Triton, Hip and PyTorch and it's all open on the @huggingface Hub. Train the new GPT to make GPTs faster ⚡️ Link below ⬇️
Do language models have algorithmic creativity? To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!🧵⬇️
small life update before the PhD: bittersweet moment but I recently left the awesome folks @vant_ai & will put my bioml interests on hold for a bit in other news, I’ve joined @SakanaAILabs for the summer! happy to chat abt either :p
Inference-Time Scaling and Collective Intelligence for Frontier AI sakana.ai/ab-mcts/ We developed AB-MCTS, a new inference-time scaling algorithm that enables multiple frontier AI models to cooperate, achieving promising initial results on the ARC-AGI-2 benchmark.…
🔥 Pokémon Red is becoming a go-to benchmark for testing advanced AIs such as Gemini. But is Pokémon Red really a good eval? We study this problem and identify three issues: 1️⃣ Navigation tasks are too hard. 2️⃣ Combat control is too simple. 3️⃣ Raising a strong Pokémon team is…
post move-out plans will not include working on the GPU codegen model, sorry @m_sirovatka
