
Li Junnan
@LiJunnan0409
Research Director @Salesforce | Prev: Co-founder of @rhymes_ai_ | Aria and BLIP series
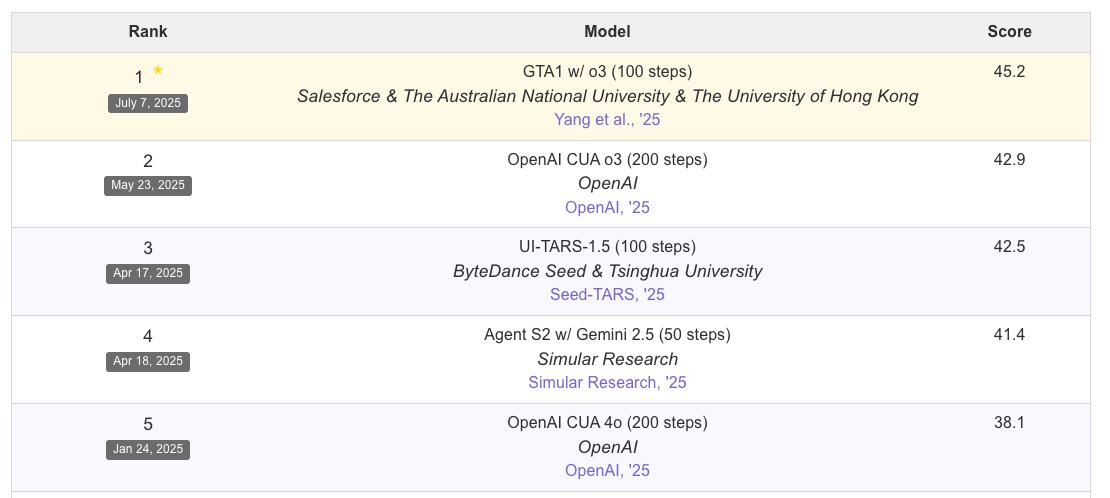
🚨 GTA1, our GUI Test-time Scaling Agent 🚨 📄 Paper: arxiv.org/abs/2507.05791 🔗 Project: os-world.github.io 💻 Code: github.com/Yan98/GTA1 🧠 7B/32B/72B models: huggingface.co/HelloKKMe 🏆 Top-1 on OSWorld benchmark (45.2% success rate), outperforming OpenAI’s CUA. GTA1…
Our contributions: • we conduct a comprehensive study of GUI agents, focusing on the key challenges of grounding and planning in real-world, high-resolution, and dynamic UI environments; • we propose a simple yet effective GUI grounding model that directly predicts…
🏅we are introducing GTA1 – a new GUI Test-time Scaling Agent that is now #1 on the OSWorld leaderboard with a 45.2% success rate, outperforming OpenAI’s CUA o3 (42.9%)! 🏆 paper: arxiv.org/pdf/2507.05791
Salesforce AI Released GTA1: A Test-Time Scaled GUI Agent That Outperforms OpenAI’s CUA Salesforce AI's GTA1 introduces a high-performing GUI agent that surpasses OpenAI's CUA on the OSWorld benchmark with a 45.2% success rate by addressing two critical challenges: planning…
GUI agents just got smarter. Salesforce presents GTA1, a test-time scaling agent for complex interfaces like Linux desktops. GTA1 tackles two major challenges in GUI agents with test-time scaling and reinforcement learning: ambiguous task plans and pixel-perfect visual…
🚀Introducing GTA1 – our new GUI Agent that leads the OSWorld leaderboard with a 45.2% success rate, outperforming OpenAI's CUA! GTA1 improves two core components of GUI agents: Planning and Grounding. 🧠 Planning: A generic test-time scaling strategy that concurrently samples…
📊 ScreenSpot-Pro 6-Month Progress Report! The benchmark continues to drive innovation in professional GUI agent research. 🎯 Exciting milestone: UI-TARS-1.5 achieves 61.6% - a remarkable 226% improvement from the previous best model (18.9%)! 📈 Progress highlights: 🔹 From…
We follow the standard evaluation protocol and benchmark our model on three challenging datasets. Our method consistently achieves the best results among all open-source model families.
Introducing new SOTA GUI grounding model -- 🔥Grounding-R1🔥 for Computer-Use Agent. Key insights: 1. "Thinking" is not required to achieve strong grounding performance with GRPO. 2. Click-based rewards are sufficient. 3. For both “thinking” and “non-thinking” GRPO, performing…
🔥 Glad to see that the 7B Grounding-R1 achieves a 50.1 SOTA performance on the ScreenSpot-Pro benchmark, even better than the 32B Qwen2.5-VL and close to the 72B Qwen2.5-VL! 📊
🚀 We’re open-sourcing Grounding-R1 — a series of SoTA models for GUI Grounding, trained with RL using a simple click-based reward. 🧠 Dive into our blog post: “GRPO for GUI Grounding Done Right” for the full training recipe. huggingface.co/blog/HelloKKMe…
🤖 Behind every performance boost in ApexGuru is a foundation of specialized AI. 🧠 Learn how it leverages real-world org telemetry, custom-trained models, and intelligent filtering to prioritize what matters. 👉 Read the blog to learn more: sforce.co/4ks5CQJ
🚀 A unified strategy for parallel decoding: Fractured CoT Reasoning We explore three dims of sampling: - Reasoning trajectories - Final solutions per traj - Depth of reasoning Maximize accuracy-cost trade-off! Allocate computation for huge gains. Paper: arxiv.org/pdf/2505.12992
We study three meta-abilities—deduction, induction, and abduction alignment, using automatically generated, self-verifiable tasks. It demonstrates that large reasoning models need not rely on unpredictable ‘aha moments’ to acquire advanced problem-solving skills. Arxiv:…
🚀 Beyond “aha”: toward Meta‑Abilities Alignment! Zero human annotation enables LRMs masters strong reasoning abilities rather than aha emerging and generalize across math ⚙️, code 💻, science 🔬. Meta‑ability alignment lifts the ceiling of further domain‑RL—7B → 32B…
🎉 Delighted to share that our paper GenS has been accepted to ACL 2025 Findings 🤗 It’s been a real pleasure working with my wonderful collaborators! #ACL2025 #Multimodal #VideoLLM Code: github.com/yaolinli/GenS Dataset: huggingface.co/datasets/yaoli…
📢 Introducing GenS: Generative Frame Sampler for Long Video Understanding! 🎯 It can identify query-relevant frames in long videos (minutes to hours) for accurate VideoQA 👉Project page: generative-sampler.github.io
Interesting work. Looking forward to experiments on larger-scale datasets!
I somehow have a strong preference to this work. It is actually pretty simple by transforming an input into multiple ones and run forward passes on them and combine the results for an output. It doesn't add many params and it does not bring much need for GPU memory but it brings…
Beyond 'Aha!': Toward Systematic Meta-Abilities Alignment in Large Reasoning Models - Formalization of deduction/induction/abduction as modular meta-abilities - Self-verifiable synthetic tasks (OOD) - Merged checkpoints outperform instruction-tuned by +10% (diagnostic) and +2%…
🚀 Beyond “aha”: toward Meta‑Abilities Alignment! Zero human annotation enables LRMs masters strong reasoning abilities rather than aha emerging and generalize across math ⚙️, code 💻, science 🔬. Meta‑ability alignment lifts the ceiling of further domain‑RL—7B → 32B…